 mateusz.kolanski
mateusz.kolanskiKorg DW-6000 is a 6 voice polyphonic synthesizer from 1985. It's hybrid, because its tone generators are digital (sample based), but amplifiers and filters are analog. DW-6000 has been superseded by his bigger brother, DW-8000 which featured more waveforms (16 instead of 8), more voices (8 instead of 6), digital effects section (well, I think that the DW-6000's analog chorus is way better than DW-8000's digital delay, but you know, back then - c'mon - it's digital dude, and digital is better).
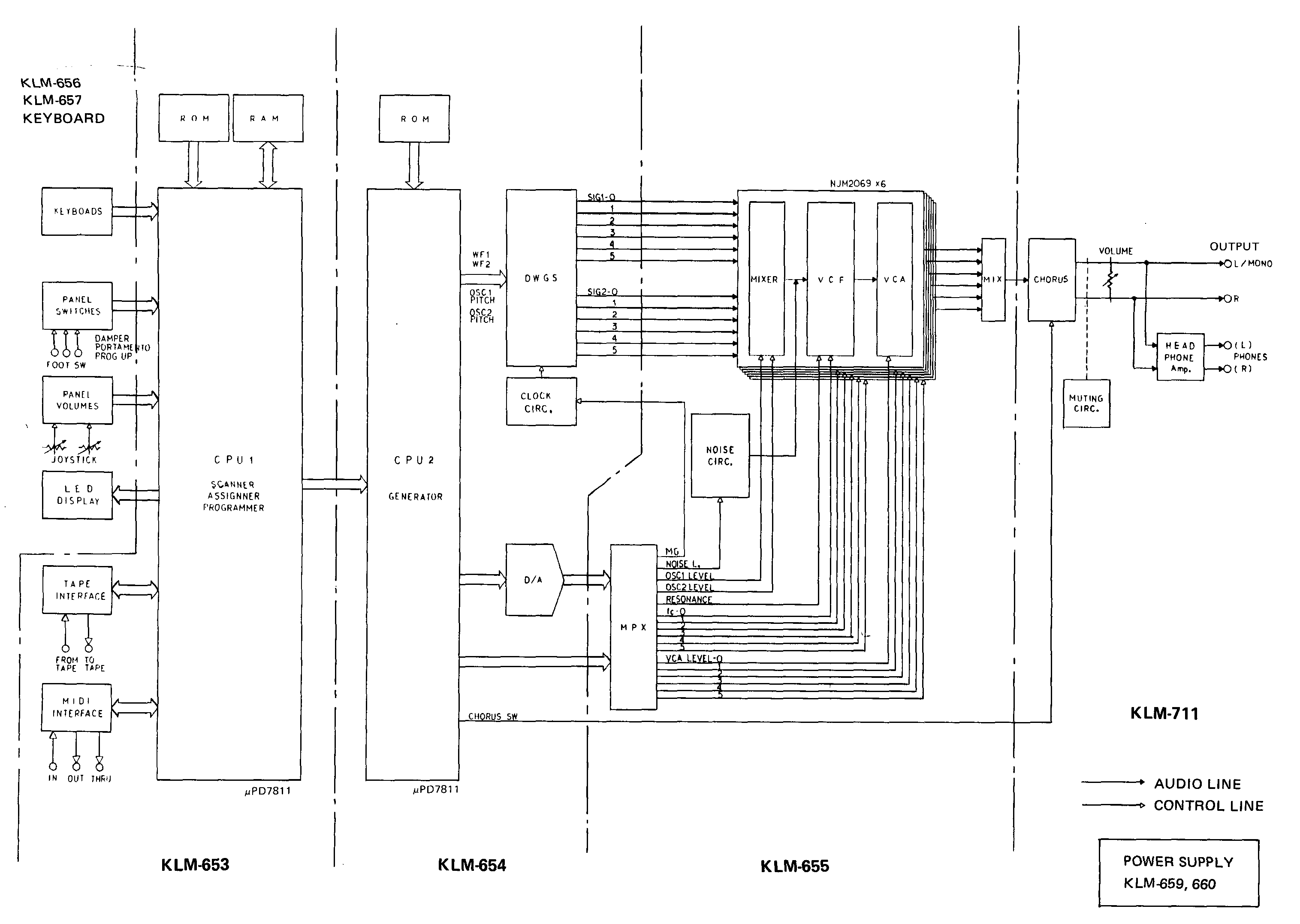
Internally, DW-6000 consists of 3 main boards:
- KLM-653 - programmer / assigner board - (this is the board I'm working on)
- KLM-654 - generator (here be voice ROMs)
- KLM-655 - analog board
This is how it looks like on a block diagram:
The idea (at least from electrical point of view) is fairly simple:
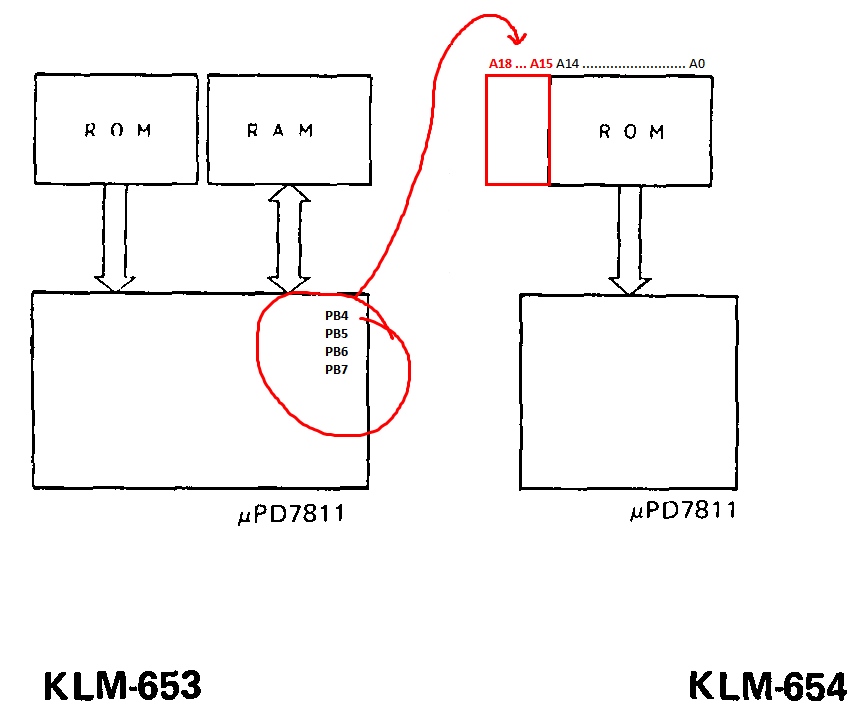
- replace the stock ROMs (KLM-654, IC29 and IC30 - HN613256, 256 kb) with bigger ones (4 Mb) and fill them with some new waveforms
- connect four unused address lines (A15-A18) to PB4-PB7 of IC1 (uPD7811, KLM-653)
- modify DW-6000s firmware to implement bank switching mechanism - add a new parameter (14) with 4 bit resolution (1-16), which will tell the CPU to set a value on PB4-PB7
 P.S. I have started this project some time ago and I didn't pay much attention to logging activities, that's why I'm adding a whole bunch of stuff right now and that's also why I'm missing some dates. Once I'm happy with my backlog, I will make this project public and start logging things as they appear.
P.S. I have started this project some time ago and I didn't pay much attention to logging activities, that's why I'm adding a whole bunch of stuff right now and that's also why I'm missing some dates. Once I'm happy with my backlog, I will make this project public and start logging things as they appear.
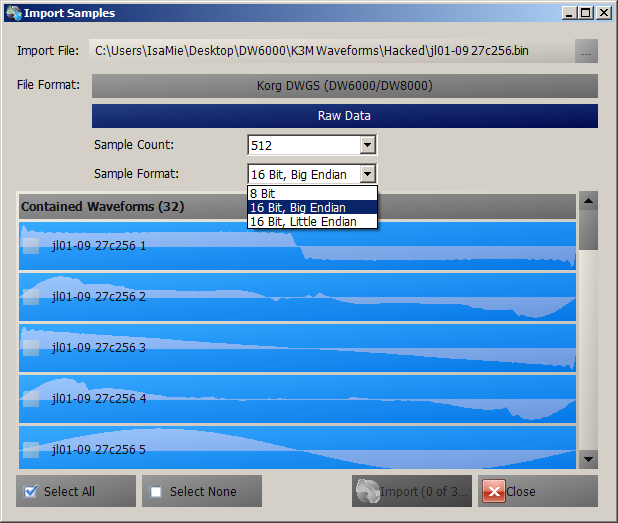 - Draw Samples:
- Draw Samples: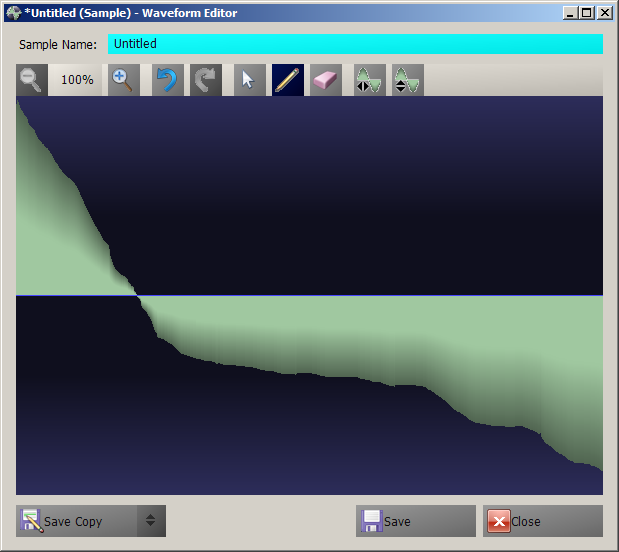 - Create complex Waveforms using... well, something probably best described as extended additive synthesis:
- Create complex Waveforms using... well, something probably best described as extended additive synthesis: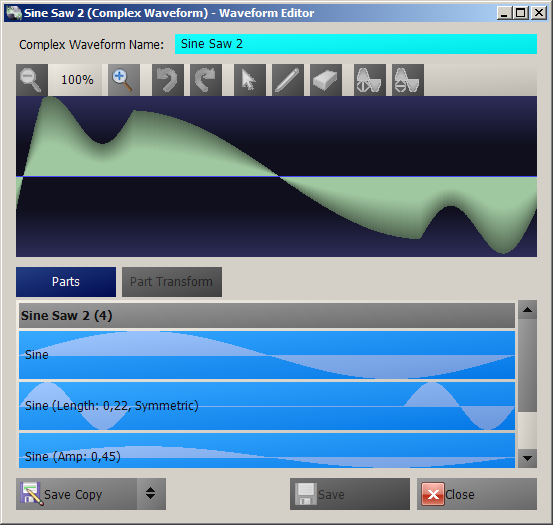 With the Waveforms created or imported, we can create new WaveROMs (for standard DW6000 and DW8000 and, of course, the extended format for this mod):
With the Waveforms created or imported, we can create new WaveROMs (for standard DW6000 and DW8000 and, of course, the extended format for this mod):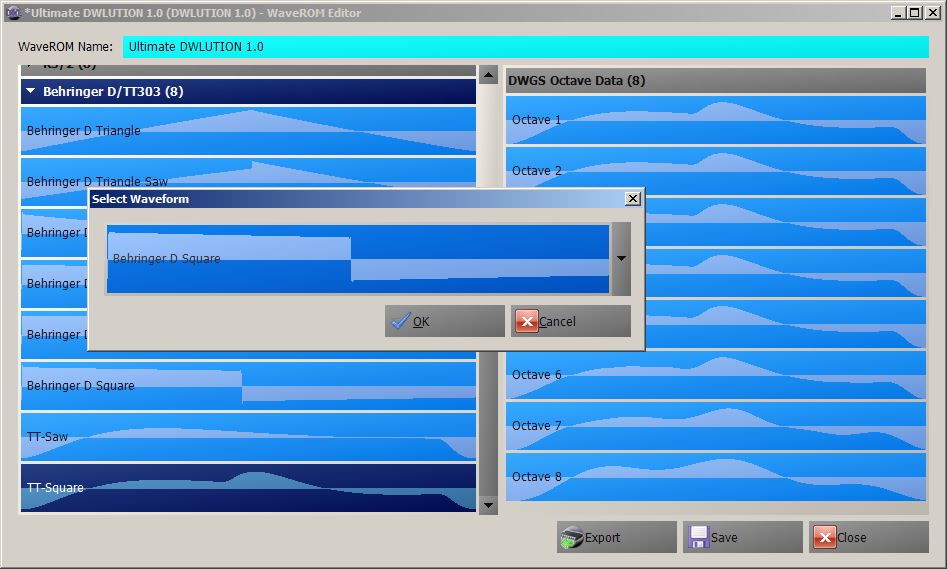 And because we (or at least I) don't want to remember where which waveform resides, the export function not only creates binary files that can be burned to EEPROMs, but also a Waveform cheat sheet that can be printed out and fits the dimensions of the waveform list on your DW6000:
And because we (or at least I) don't want to remember where which waveform resides, the export function not only creates binary files that can be burned to EEPROMs, but also a Waveform cheat sheet that can be printed out and fits the dimensions of the waveform list on your DW6000: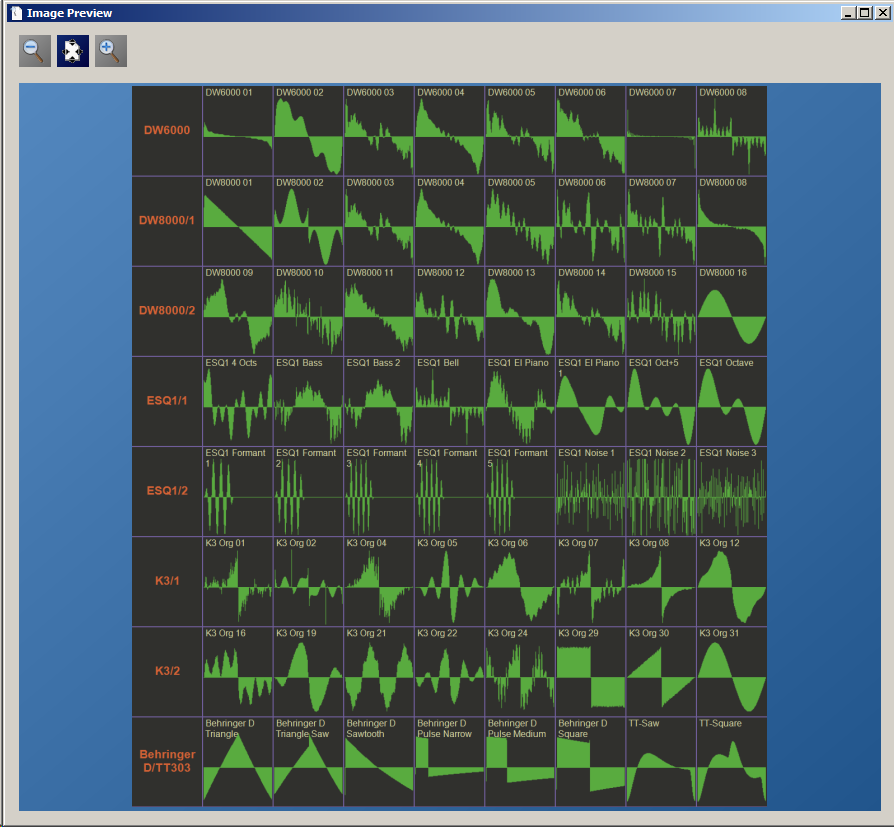 What's missing?
What's missing? Stay tuned for more!
Stay tuned for more!



 After making sure, that it still works, I've soldered some wires directly to the CPU (notice the battery:)) ...
After making sure, that it still works, I've soldered some wires directly to the CPU (notice the battery:)) ...









 Jorj Bauer
Jorj Bauer
 Yann Guidon / YGDES
Yann Guidon / YGDES
 mitxela
mitxela
 glgorman
glgorman
Hello and congratulations on the interesting project!
Before proceeding with the modification of my DW6000, however, I have a few questions to ask.
The result of the modification will be the availability of 64 waveforms, arranged in groups of 8, selectable via bank switching on parameter 14.
Are the patches programmable with any of the 64 waveforms, or are they all tied to the selected bank?
In practice, for example, if I program patch n.1 with waveform n.3 of bank n.2, then using parameter 14 I move to bank n.5 to program patch n.4, has the previous patch n.1 remained as before, or does it always end up with the waveform n.3 but from bank n.5?
Another question.
It is recommended to have the firmware with OS 5, but then patch the EPROM, so does it make sense to buy OS 5 and then have to modify it, or can the step be avoided?
Last question.
64 waveforms are amazing, but if I were to discover that there are 5 or 6 that I will never use, to replace them with the same number, I would have to disassemble everything again and reprogram the EPROMs.
Isn't there the possibility of using programmable flashes from the MIDI port via SysEx, by appropriately updating the firmware?
Thank you and greetings!