 Christoph
ChristophI downloaded the Revised New General Catalogue and Index Catalogue by Wolfgang Steinicke, which contains 13957 objects (galaxies, nebulae, star clusters, and so on). It comes as an Excel spreadsheet, so I converted it to ascii (fixed column width) and converted that to a custom binary format. The catalogue contains cross identifications where applicable, such as those for the Messier objects.
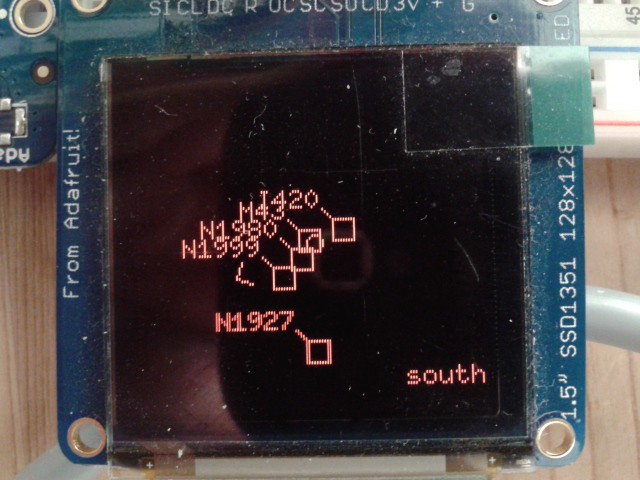
The Messier IDs are included in my binary format as an alternative ID for on-screen display. For example, the Great Orion Nebula (NGC 1976) has the alternative ID M 43, which is the displayed ID. Other NGC/IC entries don't have a Messier ID, and are displayed with their NGC or IC number. Here's a display picture of the region around M 43:
 When the mount orientation changes, new patches are loaded. That's the theory.
When the mount orientation changes, new patches are loaded. That's the theory.
Some patches contain as many as 267 objects, and some are empty. I need to filter out most of them, otherwise the display would get far too crowded (apart from the fact that the CPU and memory couldn't handle that many). This is done by loading the objects in each patch, one by one, adding them to an array, while overwriting fainter ones. The resulting displayed objects are the 10 objects with the greatest visual magnitude. Still crowded, but I'm not too worried about that now.
In the above picture you can also see that the target name (lower right corner) is still the hard-coded "south" target. I need to implement an object search that can look for NGC, IC and Messier objects.
Compared to the main project picture: I'm getting closer!
The code is becoming more and more obfuscated, but that's normal I guess...
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.