Shebin Jose Jacob
Shebin Jose JacobThe components which are needed to accomplish this project are
HardWare components
1 . Raspberry Pi 3
2. Camera module (compatible with Raspberry Pi)
3. Speaker
4.LCD module
5. Mic
SoftWare components
1. OpenCV
2. Text to Speech application (TTS)
3 . Speech to Text application
Working
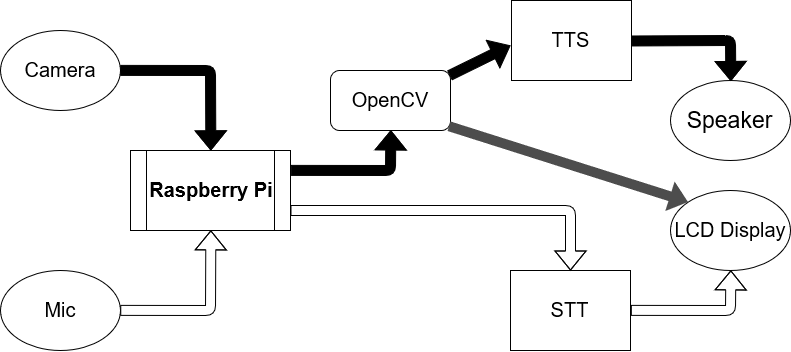
1 . Camera
Camera acts as an input device for SLT which captures the sign and transfer corresponding images to Raspberry Pi , the brain .
2 . Microphone
Microphone also acts as an input device for SLT which captures the sound and transfer it to the brain .
3 . Raspberry Pi
Raspberry Pi act as the brain of the entire device and it perform different types of function depending on the three modes of operation of this device .
1 . SIGN to SPEECH Translation mode
This is the mode which is used when a speech impaired man communicates with a common man . In this mode the camera snap the gestures and the corresponding images are transferred into Raspberry Pi . The OpenCV library installed on the Raspberry Pi processes the image and produce a corresponding text output , which is made to speech using a Text to Speech application .
2 . SIGN to TEXT Translation mode
This is the mode which is used when a speech impaired man communicates with a hearing impaired man . In this mode the camera snap the gestures and the corresponding images are transferred into Raspberry Pi . The OpenCV library installed on the Raspberry Pi processes the image and produce a corresponding text output , which is displayed on the LCD module .
3 . SPEECH to TEXT Translation mode
This is the mode which is used when a common man communicates with a hearing impaired man . In this mode the microphone records the sound and is transferred into Raspberry Pi . Using a Speech to Text application the sound is converted into text and is displayed on the LCD module .
4 . Speaker
It acts as an output device which produce sound output according to the signals from the brain .
5 . LCD MODULE
It also acts as an output device which produce text output according to the signals from the brain .
6 . OpenCV
It is the core where actual function of translation takes place . OpenCV is a real time computer vision library with strong processing efficiency . OpenCV processes the image captured by camera on various approaches
1. Template Based Approaches
Unknown speech is compared against a set of pre-recorded words (templates) in order to find the best match.
2.Knowledge Based Approaches
An expert knowledge about variations in speech is hand coded into a system.
3.Statistical Based Approaches
In which variations in speech are modelled statistically, using automatic, statistical learning procedure.
4.The Artificial Intelligence Approach
The artificial intelligence approach attempts to mechanize the recognition procedure according to the way a person applies its intelligence in visualizing, analyzing, and finally making a decision on the measured acoustic features.
We are using template based approaches and in future versions another approaches may be used .
7 . Text to Speech application
It is used to convert the text output produced by OpenCV to speech .
8 . Speech to Text application
It is used to convert the speech input into text output .
The flow of data is as shown below