Last time, I talked about how I shifted most of the heavy calculation work for rasterization into the per-triangle preparation, the PreCalc block. In this post I'll walk through some of the steps from formula to implementation.
At its heart are the following calculations:
m1 = (x3-x1)/(y3-y1) // Change in x for the long edge
m2 = (x2-x1)/(y2-y1) // Change in x for the top edge
m3 = (x3-x2)/(y3-y2) // Change in x for the bottom edge
mz = (z3-z1)/(y3-y1) // Change in z along the long edge
mr = (r3-r1)/(y3-y1) // Change in r along the long edge
mg = (g3-g1)/(y3-y1) // Change in g along the long edge
mb = (b3-b1)/(y3-y1) // Change in b along the long edge
Q = (y2-y1)/(y3-y1) // Relative position of the middle vertex along y-axis
// (c3-c1)*Q+c1 is the value of c on the long edge at height y2
// c2-(c3-c1)*Q-c1 is the change in c from the middle of the long edge to the middle vertex
// And then the full formula is the rate of change of c along the x-axis from long to short edge.
nz = (z2-(z3-z1)*Q-z1)/(x2-(x3-x1)*Q-x1) // Change of z along the x-axis from long to short edge.
nr = (r2-(r3-r1)*Q-r1)/(x2-(x3-x1)*Q-x1) // Change of r along the x-axis from long to short edge.
ng = (g2-(g3-g1)*Q-g1)/(x2-(x3-x1)*Q-x1) // Change of g along the x-axis from long to short edge.
nb = (b2-(b3-b1)*Q-b1)/(x2-(x3-x1)*Q-x1) // Change of b along the x-axis from long to short edge.
In total (ignoring additions and subtractions for now), we have 12 divisions and 5 multiplications (note that the result of the bottom half of the n* formula remains constant and only has to be calculated once.) As dividers and multipliers are pretty expensive in hardware, let's just use one of each, and just iterate through each of the calculations. Using some multiplexers and demultiplexers, we get something like this:
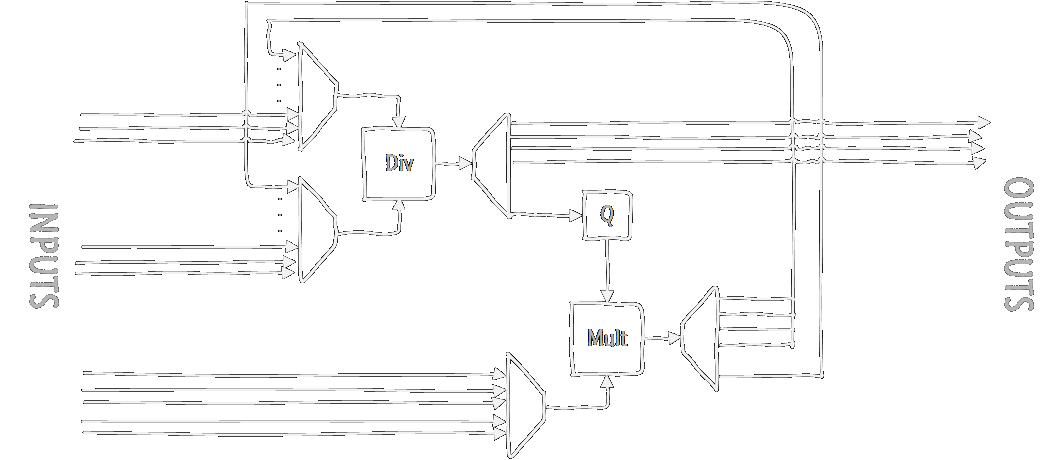
The devil is in the details, as always. Assuming all these wires have registers on them to hold the values, this setup will mostly work. Except for one small thing: the divider is incredibly slow. I just use the Xilinx CoreGen to create a divider unit for me, so that's where I'll get my restrictions, but this should apply to most divider implementations. While the divider can take and calculate new values every clock cycle, it doesn't immediately output the results. With my parameters, it takes no fewer than 32 cycles to produce an output!
As something of a motto in GPUs, latency (the time between input and the corresponding output) isn't important, throughput (how much data we can output every second) is. But we'll still have to deal with this massive latency in the divider, because we can't afford to just wait 32 cycles for every division, not to mention the second division we'll have to do for the n-values. Instead of waiting, we'll just start the calculations for the next triangle. Then, when the divisions are finally done, we'll continue processing the first triangle.
This pipelining, as it's called, is a very efficient way of using those cycles you'd otherwise just be waiting. However, this does mean we'll have to buffer the values for all the triangles we're currently processing. This can be done effectively using shift-registers. Whenever we've calculated everything we can with our current data, we'll shift new data into the registers. Then, when the divider is done, and we're ready for the next step we'll only have to look in the correct position of the shift register to get the original input data that belongs to that triangle.
Adding some clock cycles for delays and getting new input and output, I ended up with a processing cycle of 16 clock cycles. In total, the timeline looks a bit like this:
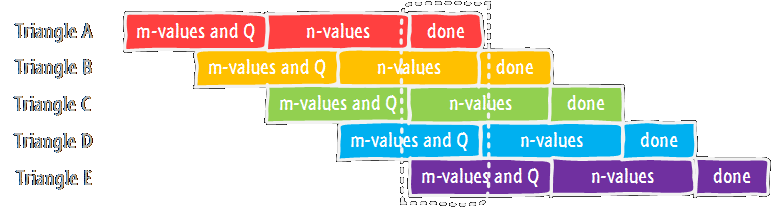
For each triangle, we first calculate the m-values and the Q, wait a bit for the results, then calculate the n-values, wait again, and finally collect the results and push them to the output. Thanks to pipelining, we can start processing the next triangle while waiting for the results of the previous. The dotted box shows what the actual PreCalc block is doing in each processing cycle: calculating the m-values and Q of the current triangle (n), waiting for the results of the previous (n-1), calculating the n-values of triangle n-2, waiting for triangle n-3, and sending triangle n-4 to the output.
All these operations are being done simultaneously (or at least within the same processing cycle) on that one divider and multiplier. In total, we need to hold the data for 5 different triangles, so that's the length of the shift registers. Add some muxes and demuxes, and a little controller to manage this schedule, and we've basically got our PreCalc unit! In total, this means that processing a triangle takes 5 processing cycles of 16 clock cycles each (80 clock cycles), and we can output a new triangle every processing cycle, for a total throughput of 6.25 million triangles per second at a 100MHz clock.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.