Jack Qiao
Jack Qiao-
High level decision making
08/27/2016 at 05:55 • 0 commentsTo connect the disparate pieces of code into a working whole, the robot needs some faculties for high level decision making. This might make you think of "AI" or machine learning, but our needs are closer to game AI: something simple, rules-based and easy to debug. After some research the dominant approaches to this task are HSM (hierarchical state machines) and behavior trees.
![]()
I thought behavior trees made more intuitive sense, so that's what I ended up using. Fortunately there is a pretty good looking implementation for ROS in python, created by the maker of the pirobot.
It comes out of the box with ROS-related blocks for performing actions on changes to a ROS topic as well as the basic building blocks of behavior trees like Selectors and Sequences. As I worked through the behaviors for the robot I had to implement a few new task blocks:
TwistTask - issues a constant twist (linear and angular velocity) to the robot for x seconds
PublishTask - publish on a ROS topic to trigger some action
DynamicActionTask - navigate to a target pose, same as SimpleActionTask, but takes the goal from the blackboard so it can be updated dynamically at runtime
As of now the behavior tree for the robot is quite simple, it just runs down a list of actions when a voice command is triggered. For more robustness there should be some recovery behaviors for example, if a navigation command fails.
code on github: https://github.com/Jack000/bunnybot/blob/master/launch/bunnybot.py
-
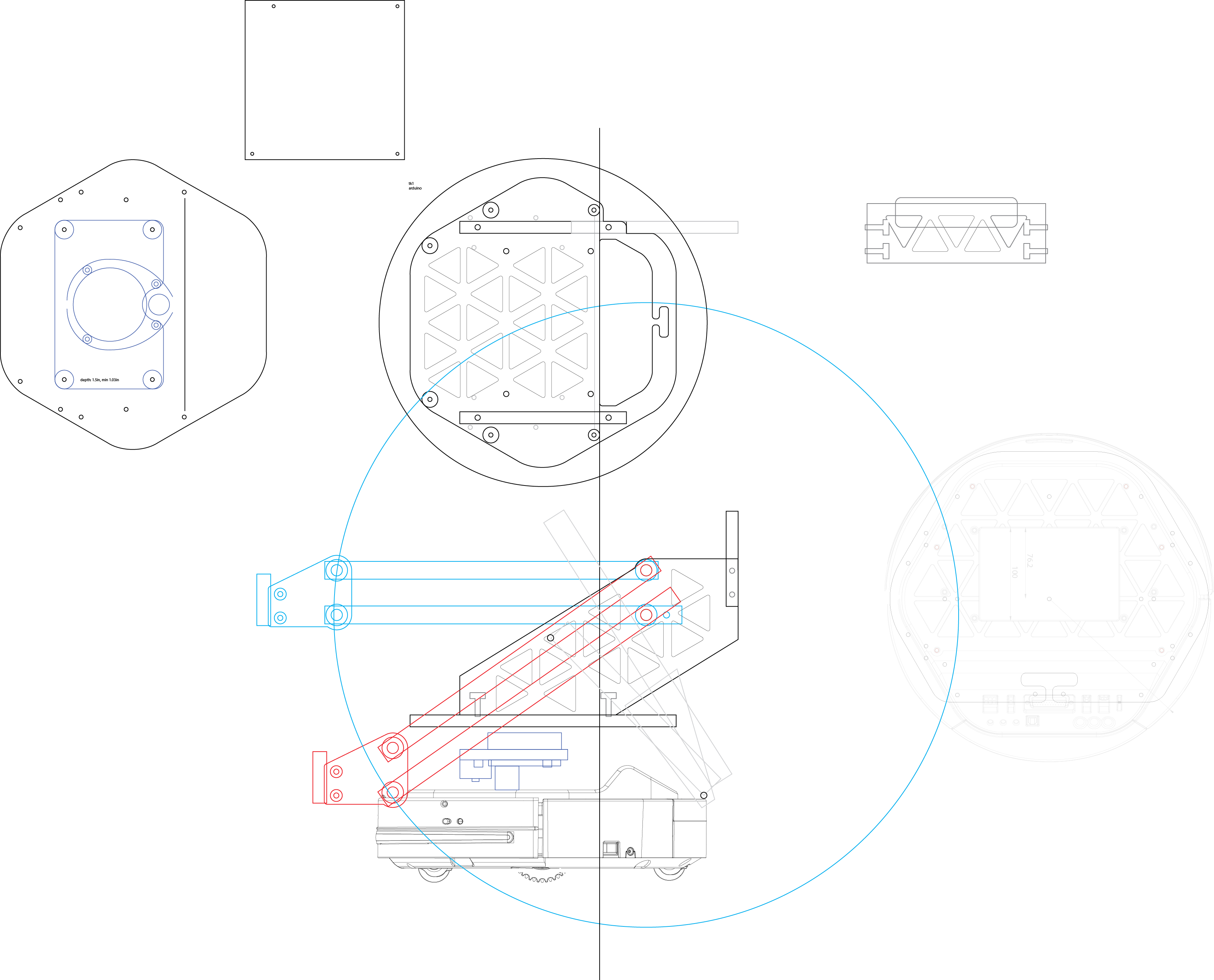
code and design files
08/20/2016 at 07:09 • 0 commentsThe project is still in progress, but at this stage I think I will upload the code and design files for the robot.
I've named the robot "bunnybot", as a reference to the turtlebot with which it shares many hardware similarities.
The custom code I've written for the robot is now compiled in one repo: https://github.com/Jack000/bunnybot
key takeaways from this version of the robot:
- too short. I still have to bend over to interact with it when giving it objects. I think 2 feet would be a better height.
- object sensing. Without feedback on whether a grasp was successful sometimes it grabs air and assumes all is well
- tilting head. The narrow field of view of the camera means that the fiducials have to be at specific heights. If the camera was tiltable we'd be able to place the fiducials in the entire vertical range of the gripper.
-
bin picking
07/24/2016 at 05:58 • 0 commentsso the first task the robot will perform is bin picking. Eg. you could use voice command to tell the robot "get me a 1 kilo-ohm resistor", and it will fetch the bin and bring it to you. Afterward it will put the bin back on the shelf.
the design of the bin is constrained by the accuracy of the robot. The bins must be shaped so that they can be reliably gripped from any angle, and they have to be tolerant to being picked up or dropped a few cm from their rest position.
this is what I came up with
![]()
the container is cylindrical to be easy to grasp, and when dropped into its slot it will always come to rest at the same spot. The interior of the bin tapers up so that the center of gravity is low, and when dropped with some inaccuracy won't tend to bounce around too much.
I CNC'd the bevel into the slots to match the bin, but thinking about it now it's not really necessary.
-
Object interaction
07/23/2016 at 08:01 • 0 commentshere's a test of the fiducial marker system
I teleoperate the robot to within view of a fiducial marker, then the robot plans the grasp on its own, slowing down as it gets close to its objective.
The idea is that the global planner in ROS can get the robot to the rough vicinity of an object, then a separate planner can issue precise commands based on the observed fiducials to perform the grasp.
Because the gripper obscures view of the object during grasping, the fiducial can't be on the object itself. To do that I'll have to add a feature to trust the wheel odometry when the fiducial is lost.
In the first version of the planner code I had also accounted for marker rotation, ensuring that the robot approached from the same angle every time. But the orientation of the observed marker is very noisy, especially when at a distance, leading to bad oscillations.
I call the planner april_planner, check out the code on github: https://github.com/Jack000/april_planner
the node issues command velocities directly instead of going through the navigation stack.
-
Fiducial marker nodelet
07/14/2016 at 23:00 • 0 commentsTo interact with the environment I'll be using fiducial markers. The markers will tell the robot 1. what an object is, and 2. where it is relative to the robot
#2 is very important. The SLAM system is only accurate to about 10cm, which gives us a general idea of where we are relative to the map, but is not enough for grasping. In order to grasp objects we need to have line of sight to the fiducial marker throughout the grasping process.
The particular type of fiducial marker I'm using are called apriltags
![]()
why are they called apriltags? no idea, might be a person's name.
I had intended to write a full GPU implementation of apriltags, but I don't think I'll have enough time to make the hackaday prize deadline. So instead I'll just use an existing library that runs on the CPU.
There are a bunch of AR and other fiducial marker nodes for ROS, but strangely none of them seem to support nodelets.
If you're not familiar with ROS, inter-node communication is a rather heavy process and especially so when it comes to video. When a camera node transfers images to the fiducial marker node, it's first encoded by image_transport, then serialized and sent over TCP - even if you're on the same machine! Special implementations of nodes that do not do this are called nodelets, with the kicker that nodes and nodelets don't share the same API.
I think because ROS is used primarily for research trivial stuff like this is easily neglected. You don't have to worry about CPU load when you have a PR2 after all : ]
Anyways, not having found a suitable nodelet implementation of apriltags, I ported the code for an existing node into a nodelet container.
check it out on github: https://github.com/Jack000/apriltags_nodelet
I stress tested it with some 1080p video on the TK1. At that resolution the node runs at 2fps and the nodelet at 3, but with a 1.1 decrease in CPU usage.
For actual use on the robot I think I'll scale down the video so the detection can proc with a reasonable framerate. That thankfully, can be offloaded to the GPU.
-
GPU computer vision
07/12/2016 at 00:41 • 0 commentsOne of the biggest obstacles for mobile robots is compute efficiency. Although desktop computers have become powerful, on robots there is a tradeoff for weight/running time/cost as you scale up the computational requirements. This is why high compute/low power boards like the Jetson TK1/TX1 are great for autonomous robots that rely on computer vision for navigation, obstacle avoidance and grasping.
on the ROS platform, the stock nodes for computer vision work well for research robots that don't have much power constraints, but our robot will have to squeeze out every ounce of performance from the Jetson TK1. There aren't any existing ROS nodes that takes advantage of the GPU, so I've started writing an OpenCV wrapper to perform some of the more resource intensive operations on the GPU.
![]()
One of these operations is image undistortion. TLDR: cameras subtly distort images, making objects with straight lines appear curved, we need to calibrate the camera and use software to correct the image so that straight lines in the real world appear straight in the image.
I wrote a small nodelet to do this on the GPU using OpenCV's GPU APIs. Check it out on Github: https://github.com/Jack000/image_proc_tegra
On my TK1 it reduces nodelet CPU usage from ~2.8 to ~1.8, with a 0.25 overhead in CUDA upload.
There does not appear to be a way to share CUDA pointers between ROS nodelets, so moving forward I will probably implement the GPU code all in one nodelet, and have options to turn various things on/off.
-
Robot navigation
07/04/2016 at 06:41 • 0 commentsI'm still waiting on the arm actuator to arrive, meanwhile here is a video of the robot doing SLAM
Here's a short explainer:
Phase 1, mapping: The robot has a 2d LIDAR that spins around to make a map of its surroundings. I manually give navigation goals to the robot, which drives to the commanded position while avoiding obstacles. As it does this a map is being built from the collected sensor data. I struggle a bit as there are people walking around.
Phase 2, navigation: Once we have an adequate map, we can save that map and use it for path planning. The advantage here is that the sensor data is only used for localization and not mapping, so the robot can go much faster than the mapping phase. This is mostly a limitation of our LIDAR, which is fairly slow and noisy.
About the visualization (Rviz in ROS)
- small rainbow-coloured dots are from the LIDAR
- shifty white dots are point cloud data from the realsense (used to detect obstacles outside the LIDAR plane)
- black dots are marked obstacles
- fuzzy dark blobs are the local costmap. The robot tries to avoid going into dark blobs when planning its path
- big green arrow is the target position that I give to the robot
- green line is the global plan (how the robot plans to get from its current location to the target)
- blue line is the local plan (what the robot actually does given the global plan, visible obstacles and acceleration limits of the robot)
-
mobile base
06/23/2016 at 19:57 • 0 commentsAfter experimenting (and failing) at a couple of ways of doing SLAM I've settled on the classic design of a 2d LIDAR for room mapping, supplemented with a front-facing depth sensor for obstacle detection.
Instead of a fully custom robot I'll be using a Kobuki base and putting my stuff on top. With the power constraints I will have to replace the mini-itx board with a jetson tk1, hopefully Ubuntu on ARM won't be too much of a pain. Here's what the prototype will look like:
![]()
and the boards all cut out:
![]()
-
tethered dev platform and fake-LIDAR
06/23/2016 at 19:36 • 0 comments![]()
the first prototype had some issues, the biggest of which was that it had no on-board computer and had to be tethered to my laptop. Here I've made a diy dev platform that runs a mini-itx board. It's still tethered with a power cord though.
with this platform I've experimented with 3 different approaches to 2d SLAM:
1. A "Fake" lidar scan from depth-sensor data
2. Laser line projector and triangulation
3. A neato xv-11 LIDAR
Method 1 is basically what the turtlebot uses, and it works ok for the most part. The biggest problem with this method is that the field of view is rather limited, so there are many cases where you have no data to do SLAM with.
Method 2 I saw on this hackaday post. I used a 20mw laser line projector, 650nm band-pass filter and a usb camera. The challenging part of this method is noise filtering - whenever the camera or an obstacle moves, it will show up in the inter-frame difference along with the laser line. While the band-pass optical filter limits the absolute-value of the noise, the laser line will also quickly drop to near the noise floor due to the fan spread. The 20mw laser was only usable to about 2 meters. A very specific problem that I encountered was computer monitors - when moving the camera around the difference looks exactly like a laser line. Overall I don't think this works particularly well for a moving robot.
I've had much better results with the neato LIDAR. Although it also uses parallax, the data I'm getting is a lot more reliable at farther range.
-
gripper
06/23/2016 at 19:07 • 0 comments![]()
bought a gripper on aliexpress to save time. I know, not very hackerish but there are more interesting things to work on!
BunnyBot
BunnyBot is a ROS based robot platform that can perform useful tasks using its built in gripper and vision system.