 lpauly
lpaulyAdministrative:
Repositories:
Videos:
Licensing:
Mesh DHCP Extensions: GNU GPLv3
Web administration panel: GNU GPLv3
Embedded computer/router: TAPR
OpenWRT: GNU GPLv2 (note that OpenWRT itself is built with many other packages, some of which may not be released under the GPLv2 license. For more information, see http://wiki.openwrt.org/about/license.
About:
Block Diagram:
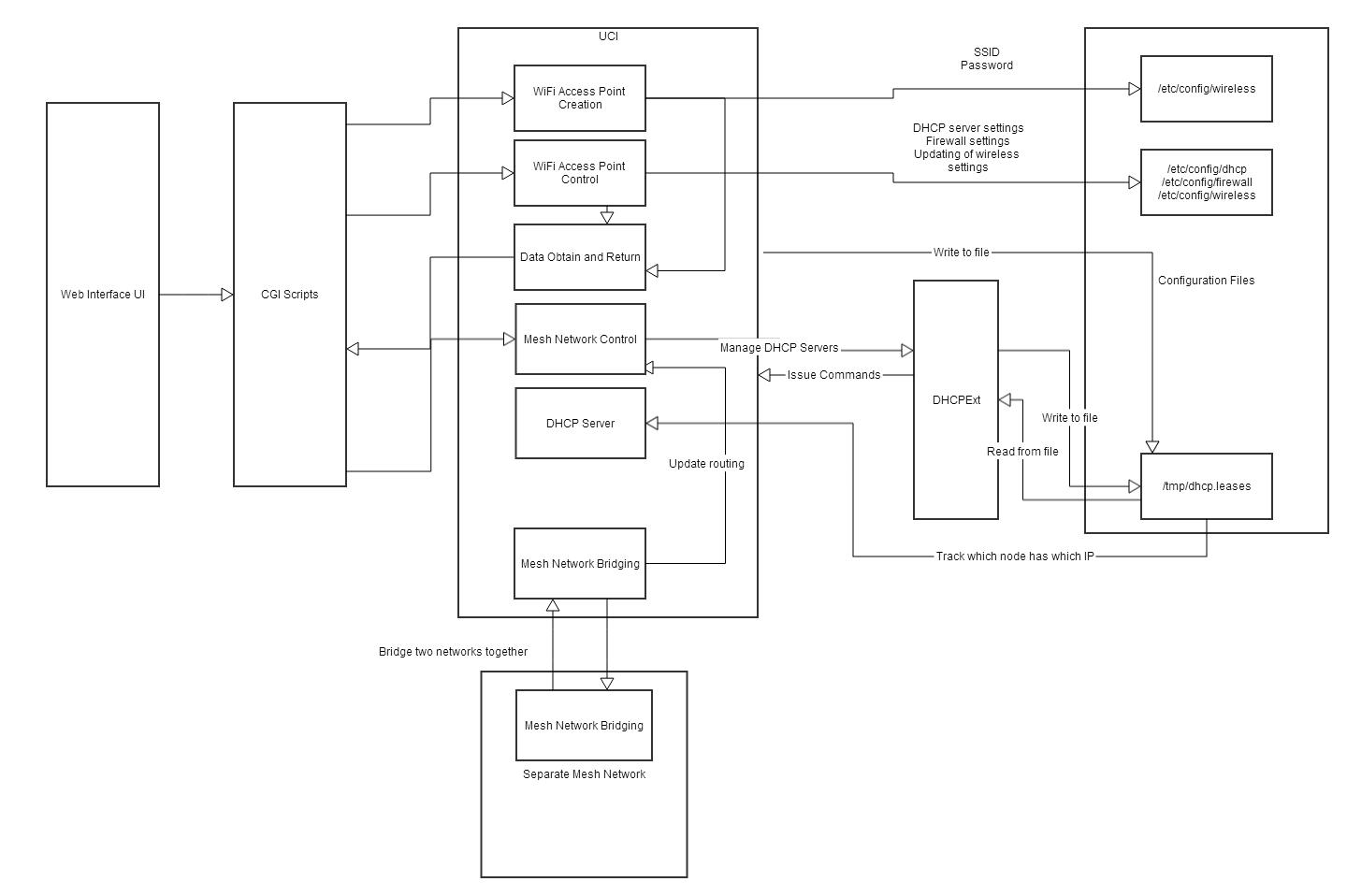
Description:
This project was undertaken to simplify the setup of mesh networks. The reason for this is that mesh nets solve a number of large issues in networking, including (but not limited to) link oversaturation, and single points of failure. However, this is offset by the fac that they require significant knowledge in computer administration (and especially, oftentimes, the Bash shell) to set up. Thus, our goal is to simplify this.
We wish to provide 2 options to end users - a piece of hardware, likely based on an ARM or MIPS processor architecture, running our system image, with wireless and ethernet network interfaces, as well as the image itself, such that those with the prerequisite knowledge have the option to flash their own hardware.
Our goals for the software are:
- to support firewall filtering, using TCPDump BPF bytecode (with the option of handwriting the code, or using the web administration panel)
- to provide a web administration panel, to administrate the network
- to allow automatic failover of the DHCP server, to allow for no single point of failure
- to utilize the Multipath TCP specification, to allow the mesh to make use of multiple connections to the public Internet (secondary goal)
This will be built upon a base of OpenWRT, to allow for a greater flexibility with regards to hardware that can be used, and to take out most of the legwork involved in the generation of a working system. This also allows end users, with the knowledge to do so, to customize their system to achieve other goals as well, dependent of course on the limitations of OpenWRT and its available packages.
System Design - Mesh DHCP Extensions
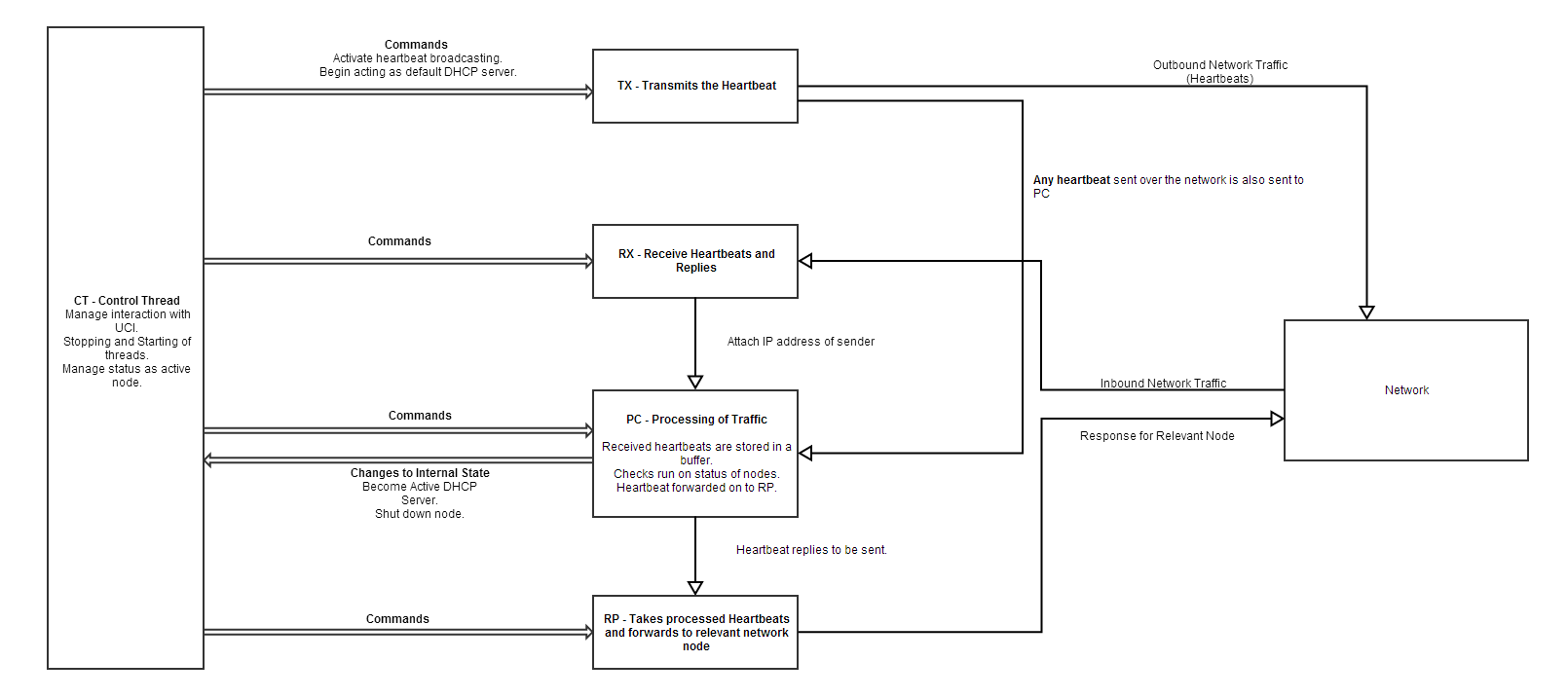
The control thread, CT, is in charge of the overall management of the other four threads. It interfaces with the UCI and a web admin panel to allow external control of the software, and to allow it to issue commands to other pieces of software, and handles the stopping and starting of the other threads. It also handles the status as an active node based on commands given by PC, the processing thread.
TX simply manages the transmission of heartbeats across the network. It will broadcast heartbeats containing configuration and state details, if it is the active DHCP server. It will also send a heartbeat directly to it's defined target.
RX receives heartbeats and replies from the network, then attaches the IP address of the sender, and forwards the data to PC.
PC is responsible for the processing of traffic. When sent heartbeats are received from the TX thread, they are stored in a buffer.
When a heartbeat is received from the network, times for the node it was received from will be updated, and the heartbeat will be sent to RP, the reply thread. If a reply is received, it matched with the sent heartbeat. The sent heartbeat is removed from memory after all the nodes that are expected to reply do so.
If a heartbeat is in the queue for more than 400ms, or a node does not send a heartbeat the current node is expecting for more than 400ms, the node is assumed to be dead. This will either be reported to the DHCP server, or, if the failed node is the DHCP server, the current node is able to take over DHCP duties depending on it's location in the circular queue of possible DHCP servers.
Each node in the queue adds 100ms of lead time, to allow a possible DHCP server enough time to become active. eg, node #1 will become the DHCP server after 400ms, node #2 after 500ms, node #3 after 600ms, and so on.
RP receives received and processed heartbeats from PC, forms a response, and sends it out onto the...
Read more »







 Charles Yarnold
Charles Yarnold
 worsthorse
worsthorse
 Dylan Brophy
Dylan Brophy