0%
0%
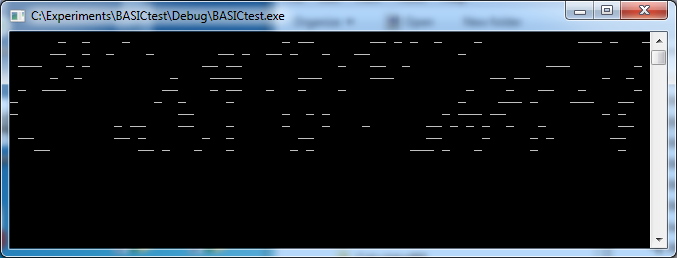
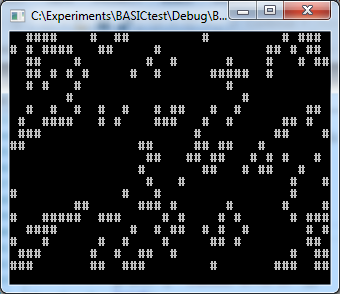
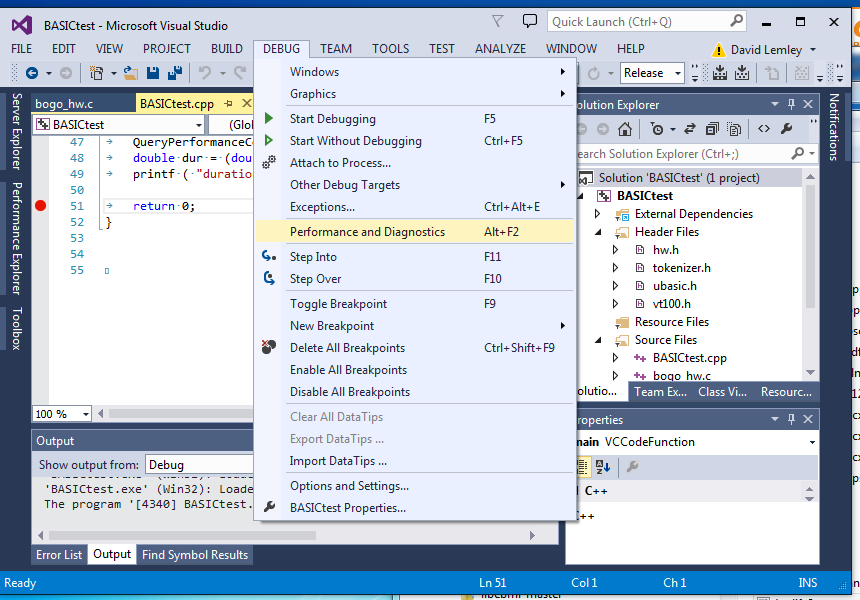
UBASIC And The Need For Speed
I basic, 'ubasic', they basic, we basic; wouldn't you like a speedy BASIC, too?
 ziggurat29
ziggurat29Become a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests

 Santo_mar_d_velaz
Santo_mar_d_velaz
 glgorman
glgorman
 Badmonky
Badmonky