 ziggurat29
ziggurat29Jun-12 3:10 PM - Jun-12 6:01 PM
I was eager to get some empirical validation (or negation) of these hypotheses (and maybe even get some new ones). However, I didn't have the actual hardware. On the one hand, you can't draw conclusive inferences when testing on a non-normative platform, but on the other hand, what else can I use. So I decided to go ahead and port the program to a desktop application, and just try to be careful to avoid measuring anything that was not CPU related (like screen I/O), and even then, take the results with a grain of salt.
Mostly because of personal familiarity, and partially because of expedience, I decided to port the ubasic into a Windows application. The reasons were:
- I have a bunch of Windows build systems on-hand
- I have familiarity with using Developer Studio's profiler. Well, mostly.
It seems that Microsoft has significantly dumbed-down the profiler in VS, in the past few years. On the upside, it's much easier to start up, but I do miss the granularity of control that I had before. Maybe I'm a masochist. Anyway, for this exercise, I'm using Developer Studio 2013 Community Edition. (Old, I know, but I use virtual machines for my build boxes, and I happened to have one already setup with this version in it.)
But first things first: building an application.
The needed changes were relatively straightforward, thanks to the clean effort of the [project's authors] -- especially considering how quickly they built this system. Mostly, I needed to do some haquery to simply stub out the hardware-specific stuff (like twiddling gpio), since my test program didn't use those, and then change the video output to go to the screen. Fortunately, since those routines were character-oriented at the point where I was slicing, it was easy for me to change those to stdio things like 'putc' and 'puts'. It still took about 3 hours to do, because you need to also understand what you're cutting out when you're doing the surgery.
After that, I was able to run the sample BASIC life program. The screen output was garbage, so maybe it wasn't working, but I could see screen loads of output, followed by a pause, followed by more screen loads of output. Nothing crashed. This is a pretty good indication that things are more-or-less working.
Just looking at the output change during the run showed that it was pretty slow. This was running on my 2.8 GHz desktop machine and it was slow, so I can only imagine the experience on the 48 MHz embedded processor. To make it visually look a little better, I tweaked the source code to output a different character, and implemented the 'setxy' function to actually set the cursor position, and then had Windows remember the screen size, which I set to 40x21 (I added a row because doing a putc to the last character position would stimulate a screen scroll). Now it looks a little more like 'Life'.
OK, that's enough play time. We should be ready to do a profiling run. As mentioned, this is more easily launched in current Visual Studios. In the case of VS 2013, it is under the DEBUG menu as 'Performance and Diagnostics. (check the docco for your version if different; they move it from time-to-time.)
Which will lead to the opening screen.
And when you click 'start' you'll get into the 'performance wizard', which is just a sequence of dialog boxes with options.
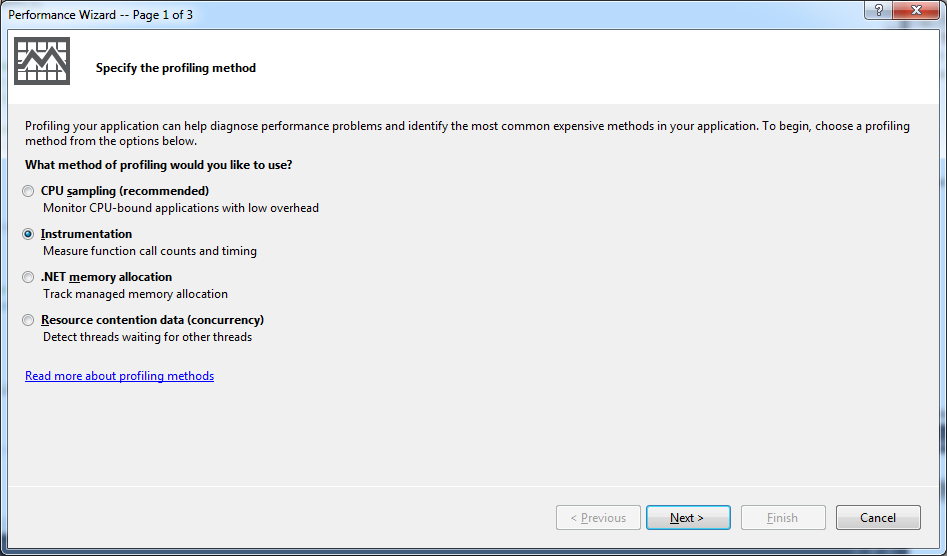
There's several ways to profile. The default is a low-impact sampling method. In retrospect, I probably should have used this to start with -- it usually presents a reasonably accurate view, and it is low-impact. But I was going for precision out of habit, and I chose 'Instrumentation'. This has associated costs.
The 'CPU sampling' method presumably works by periodically interrupting the process and seeing where it is, and taking notes. The 'Instrumentation' method does a special link activity, where every function [well, almost! as we'll see in a subsequent post] gets a little prologue and epilogue injected, which reports time taken in that function. As you can imagine, 'Instrumentation' is more exact, but incurs a big overhead. It also generates voluminous data -- like gigabytes for just a couple generations of Life. [This is one reason I liked the old profiler system: I had control over what sections of the application to profile, so I didn't incur these impacts across the whole thing.]
So, now the program is REALLY slow, and needs some baby sitting. I let it get through a couple generations while I did other things, and then exit it to stop profiling. It generated over 7 GB or data, so know this before you start. It also takes quite a while for the profiler to collate that data after your program ends. So there's another opportunity for a coffee break. Afterwards, you are rewarded with a pretty summary screen:
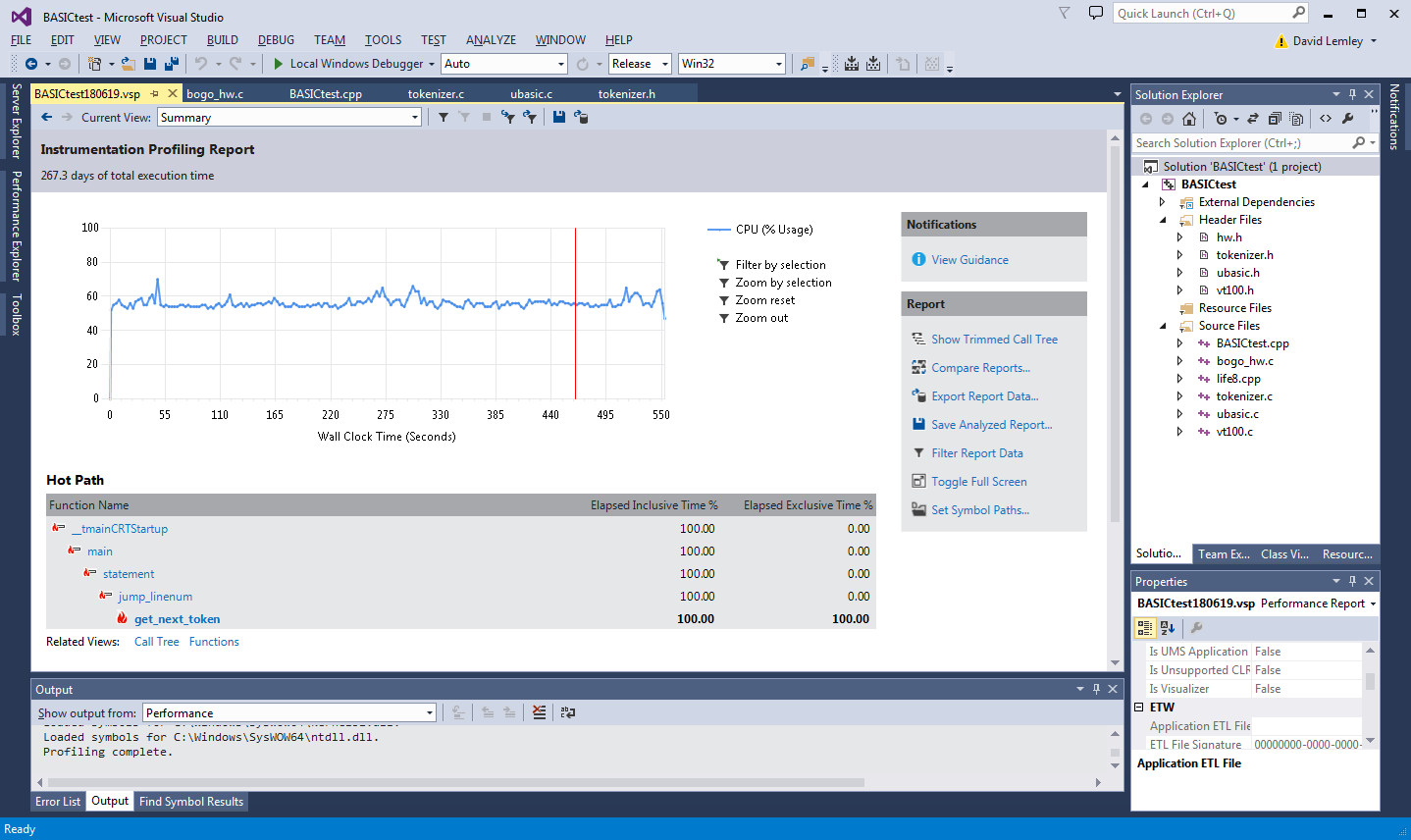
It conveniently determines the 'hot path' through your application, but that is just a summary, I like to look at the gory data. In the 'Functions' view, you get a spreadsheet-esque table listing the various functions profiled, and their 'Inclusive' and 'Exclusive' times, amongst other things:
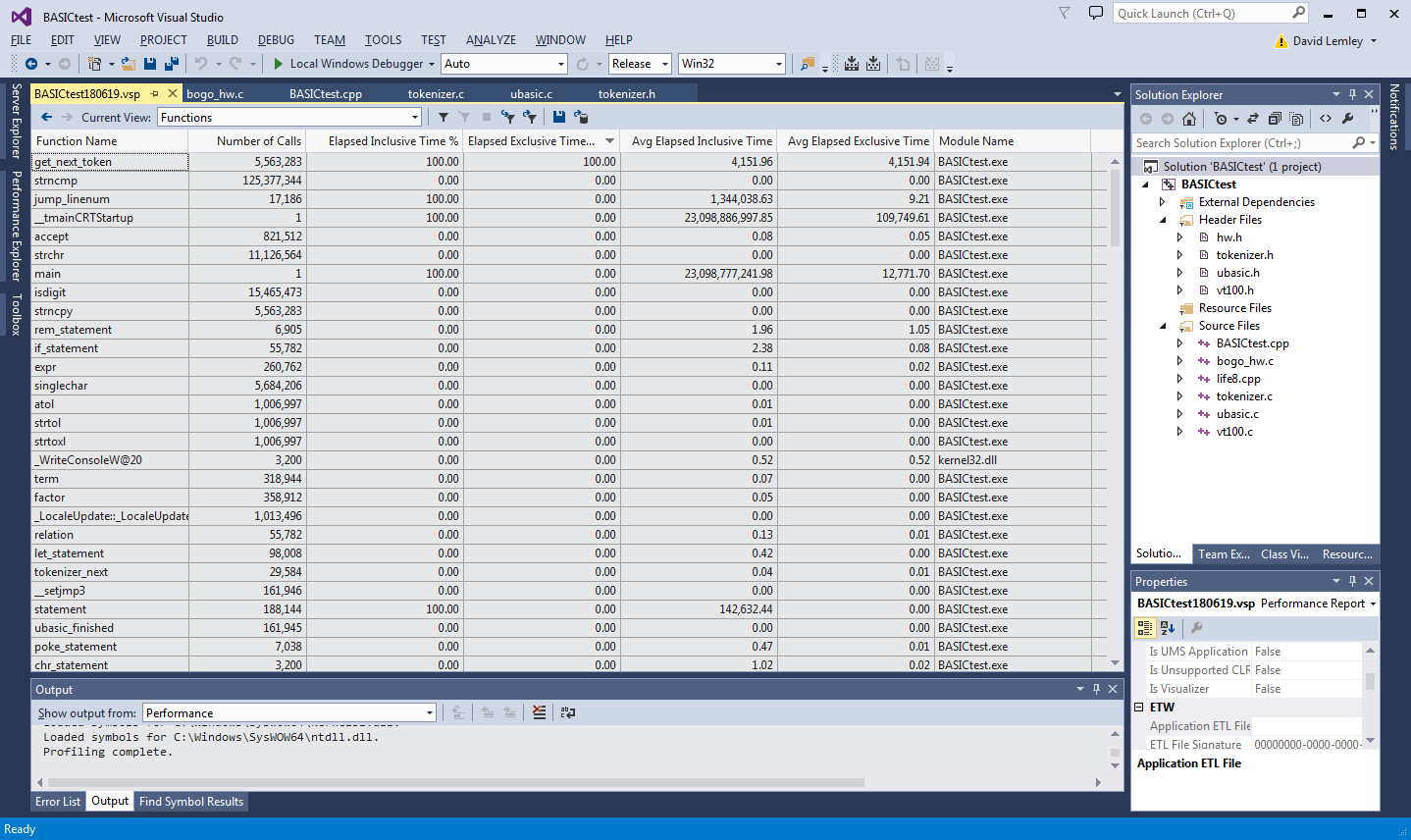
The 'Inclusive' time is the time spent in this function, and all the functions it called. The 'Exclusive' time is the time spent just in this function, disregarding that in the functions it calls. I usually first focus on the 'Exclusive' time, because that tells me where some code can be directly modified that has a performance impact, but 'Inclusive' is also important because that can indicate opportunities in reducing the number of child function calls. Like in loops.
In this case I notice get_next_token is being indicated as taking up practically 100% of the execution time ('Exclusive'), whereas nothing else seems to matter at all.
As mentioned before, I take the numbers with a grain of salt when I am profiling a hacked test harness application like this, especially cross platform, and especially cross CPU. But given these number are so wildly skewed towards this particular function ('get_next_token'), and because this is simple C code, I feel pretty sure that this gives a reasonably accurate picture of what's the root cause of the performance problem. And on the positive side, it looks like improving this one function will have a tremendous benefit to performance overall!
At this point I did overlook some things, but I'm not going to describe that here, since that is the subject of a subsequent post.
I announced these findings to [the original inquirer], and suggested that some low-hanging fruit would be to look at the implementation of get_next_token(). Further, since it represents nearly 100% of the execution time, net gains will initially be directly proportional to gains in this function alone. E.g. speeding the function to take 50% of the time will make the app as a whole take 50% of the time. This is only true at the beginning -- every gain you make will cause the other functions' times to increasingly dominate -- so the margins will decrease. But it will be great at the beginning.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
I want to promote my business and for that, I am searching for tips online. I am glad I have found your post. Your post is really very helpful for me. I am also searching for the business plan services online and found an https://www.ogscapital.com/business-plans/ website in which I have found many business plan articles. You can also visit that website if you want to gather information regarding business plans.
Are you sure? yes | no