 Ted Yapo
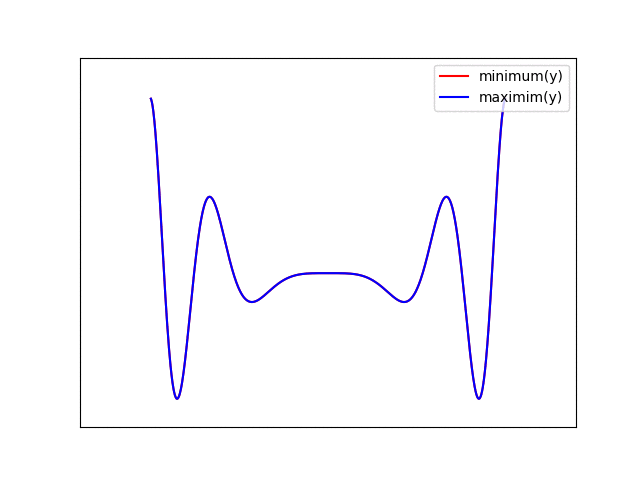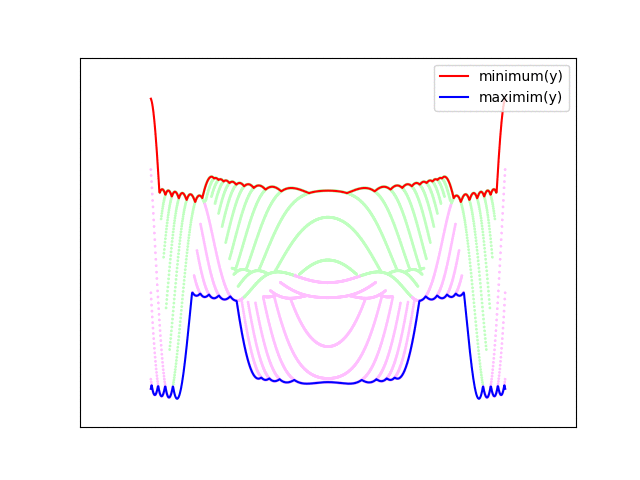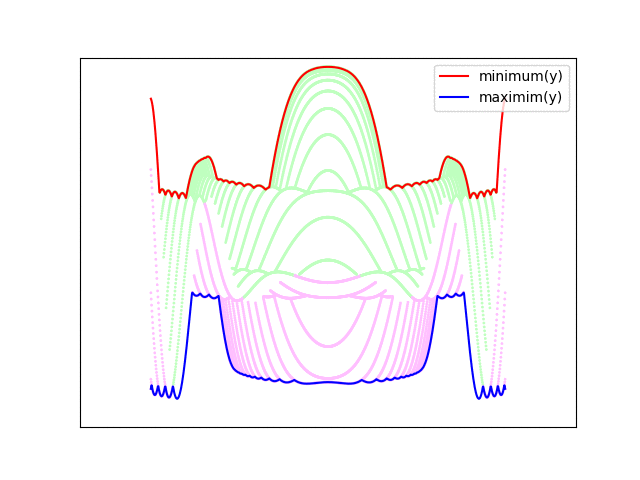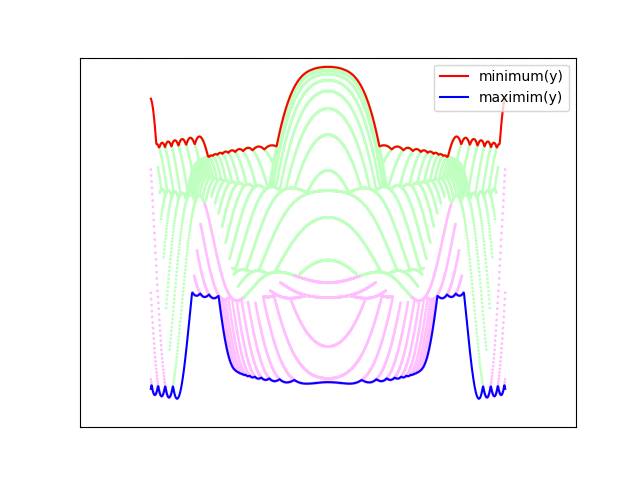
Ted YapoHere's how it looks animated - the build-up of the number of lines at the start is done for effect (as is the fade-out at the end).
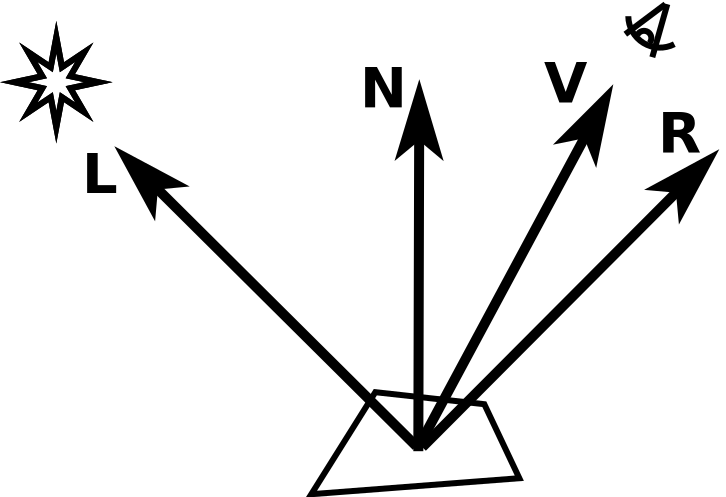
You can check out the log entries for explanations of:
If I've forgotten anything, or you have any questions, please ask. I had a blast programming this, and found the badge to be a lot of fun. What I would have given to have this thing in the 1980s!





 Bruce Land
Bruce Land
 Andy Oliver
Andy Oliver
 Mike Szczys
Mike Szczys
Really nice drawing functions dude, very impressive :-)