 Yann Guidon / YGDES
Yann Guidon / YGDESThis project is shelved and superseded by #Libre Gates
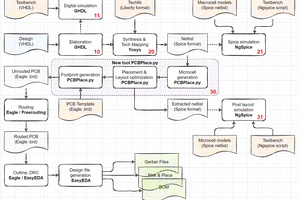
This project is "more or less related" to #Shared Silicon and aims to better prepare and prototype designs in FPGA before committing to ASIC tapeout. I'm currently using this library for the #YGREC8 to check design sanity and testability (which is also why you'll find many references and files from Y8 here).
Lately, Christos joined forces and opened new perspectives and applications for this library, for test/validation/fuzzing through the injection of faults. It enables the verification of test benches and other critical tools, for fault-tolerant circuits, wafer-stepper test vectors...
Currently I'm working on the 2nd version of the library, a deeply refactored and enhanced version, and aiming at a v3 with most desired features in the near future. This becomes even more pressing with the MPW shuttles promised by Google on the Skywater 130nm node.
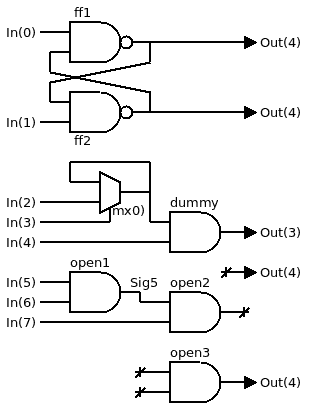
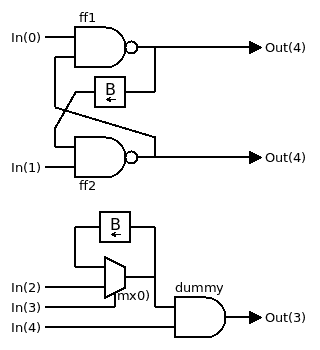
The library implements gates that can work in one of several modes, as explained in the log Modes of operation.
What can you do now with this ?
- Simulate your mapped design (the initial purpose). The "simple" implementation ( >= v2.8 ) works anywhere, it's fast but without any fancy feature.
- Check that the gates behave correctly, with histograms of their activity, and detect unused cases (this helps optimise/simplify a design, or ensure it is optimal)
- Inject unusual signals at inputs to observe the logical cone
- Alter the function of a given gate (simulate a hardware fault)
- Compare which alternative architecture toggles the least nets, investigate toggle-reduction strategies to reduce switching-induced power consumption.
- Implement arbitrary logic with the generic gates (arbitrary LUT16 is supported since 20191213, so the library is not restricted to ProASIC3 designs)
What's intended ? (not yet implemented)
- BIST verification (brute-force through all the gates is possible thanks to parallelism)
- Automatic Test Vector Generation
- Import/Export EDIF ? CircuitJS ?
It all started as a Free collection of 3-input gates and some additional ProASIC3-specific modules, used to design my own systems.
See the license/ directory for the AGPLv3 terms of distribution.
The proasic3v3/ directory contains all the gates and modules, rewritten to simulate the real tiles and hard macros.
You'll find a series of examples in the testxxxxxx directories, that implement various 8-bits units using only 3-inputs gates and with a well-defined latency.
As of 20200715, the v2 supports these tiles and hard macros:
No input:
GND VCC
1 input:
BUFD BUFF CLKINT INV INVD
2 inputs:
and2 and2a and2b nand2 nand2a nand2b nor2 nor2a nor2b or2 or2a or2b xnor2 xor2
3 inputs:
and3 and3a and3b and3c ao1 ao12 ao13 ao14 ao15 ao16 ao17 ao18 ao1a ao1b ao1c ao1d ao1e aoi1 aoi1a aoi1b aoi1c aoi1d aoi5 ax1 ax1a ax1b ax1c ax1d ax1e axo1 axo2 axo3 axo5 axo6 axo7 axoi1 axoi2 axoi3 axoi4 axoi5 axoi7 maj3 maj3x maj3xi min3 min3x min3xi mx2 mx2a mx2b ...




 Tim
Tim
 Al Williams
Al Williams
Another important fix (makes the latches work as intended) : update to YGREC8_VHDL.20200727.tgz !