 Capt. Flatus O'Flaherty ☠
Capt. Flatus O'Flaherty ☠After messing about with some networks for a couple of months in an attemt to design computer vision for machines, I started to notice a few re-occurring topics and buzz words such as 'prototext' and 'weights'.
Curiosity has now got the better of me and I worked out that the various prototext files associated with a network describe it's structure in reasonably simple and human readable terms eg:
layer {
name: "pool2/3x3_s2"
type: "Pooling"
bottom: "conv2/norm2"
top: "pool2/3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
I presume that this is a python layer, but I'm not sure, but it does not matter for now.
The fantastic Nvidia Digits software enables print out of a fancy graphical representation of the whole network and, starting with the renowned bvlc_googlenet.caffemodel, I thought I'd try and hack it and learn something through experimentation.
One of the first thing I looked for was symmetry and repetition, with the desire to simplify what initially look very complicated. I noticed that the above layer describes a 'link' between other blocks of layers that seem to repeat themselves about 6 times:
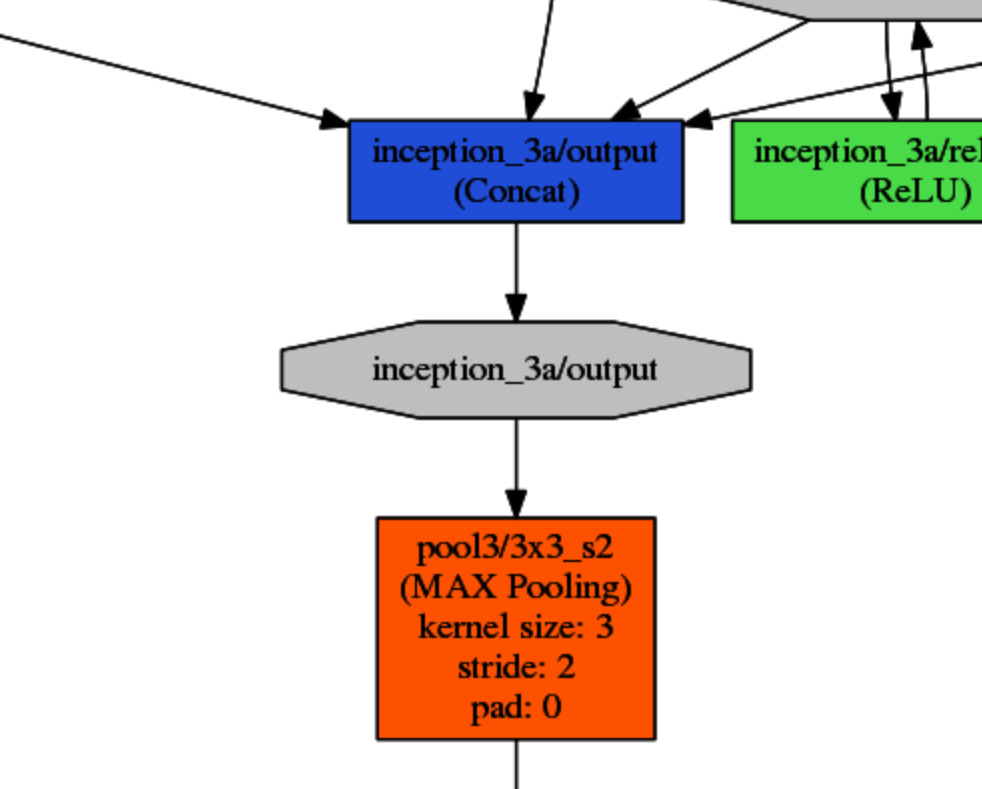
...... in the massive bvlc_googlenet network:
..... and in this way I managed to simplify it by removing what looked like about 6 large blocks of repeating layers to this:
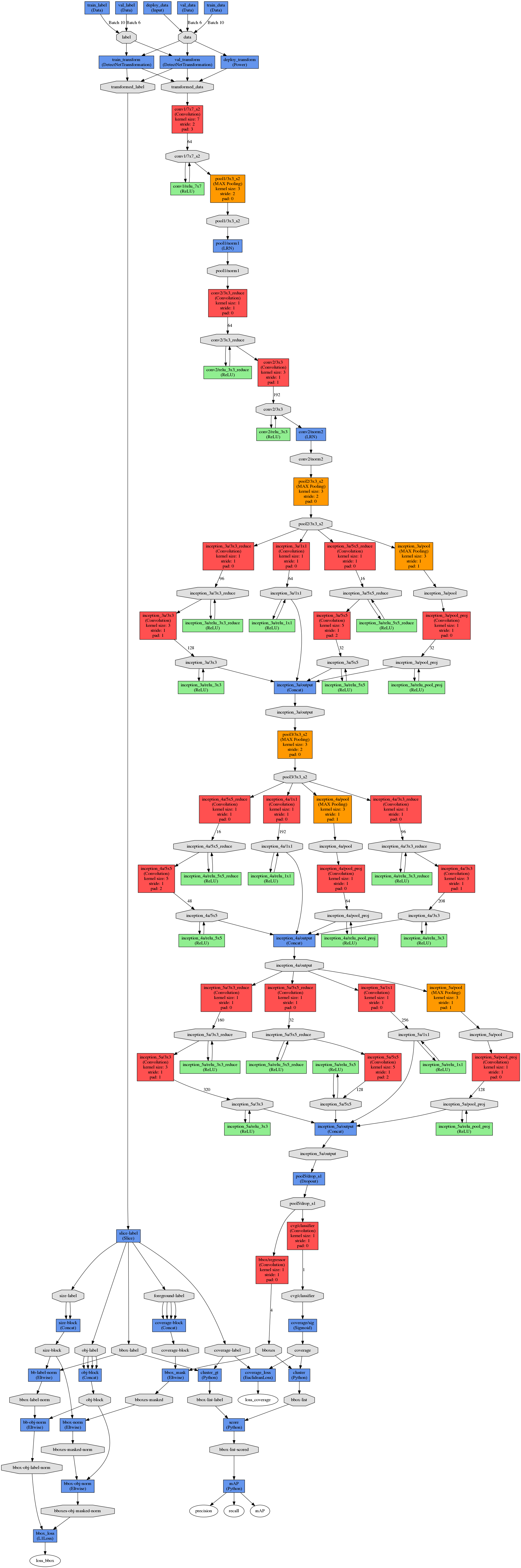
...... And looking at this diagram very carefully, there's still one big block that repeats and should also be able to be removed. I tried removing it, but unfortunately gave this error:
Creating layer coverage/sig Creating Layer coverage/sig coverage/sig <- cvg/classifier coverage/sig -> coverage Setting up coverage/sig Top shape: 2 1 80 80 (12800) Memory required for data: 851282688 Creating layer bbox/regressor Creating Layer bbox/regressor bbox/regressor <- pool5/drop_s1_pool5/drop_s1_0_split_1 bbox/regressor -> bboxes Setting up bbox/regressor Top shape: 2 4 80 80 (51200) Memory required for data: 851487488 Creating layer bbox_mask Creating Layer bbox_mask bbox_mask <- bboxes bbox_mask <- coverage-block bbox_mask -> bboxes-masked Check failed: bottom[i]->shape() == bottom[0]->shape()
...... So that's it for now ..... and here's my 'simplified' network prototext for object detection:
# DetectNet network
# DetectNet network
# Data/Input layers
name: "DetectNet"
layer {
name: "train_data"
type: "Data"
top: "data"
data_param {
backend: LMDB
source: "examples/kitti/kitti_train_images.lmdb"
batch_size: 10
}
include: { phase: TRAIN }
}
layer {
name: "train_label"
type: "Data"
top: "label"
data_param {
backend: LMDB
source: "examples/kitti/kitti_train_labels.lmdb"
batch_size: 10
}
include: { phase: TRAIN }
}
layer {
name: "val_data"
type: "Data"
top: "data"
data_param {
backend: LMDB
source: "examples/kitti/kitti_test_images.lmdb"
batch_size: 6
}
include: { phase: TEST stage: "val" }
}
layer {
name: "val_label"
type: "Data"
top: "label"
data_param {
backend: LMDB
source: "examples/kitti/kitti_test_labels.lmdb"
batch_size: 6
}
include: { phase: TEST stage: "val" }
}
layer {
name: "deploy_data"
type: "Input"
top: "data"
input_param {
shape {
dim: 1
dim: 3
dim: 640
dim: 640
}
}
include: { phase: TEST not_stage: "val" }
}
# Data transformation layers
layer {
name: "train_transform"
type: "DetectNetTransformation"
bottom: "data"
bottom: "label"
top: "transformed_data"
top: "transformed_label"
detectnet_groundtruth_param: {
stride: 16
scale_cvg: 0.4
gridbox_type: GRIDBOX_MIN
coverage_type: RECTANGULAR
min_cvg_len: 20
obj_norm: true
image_size_x: 640
image_size_y: 640
crop_bboxes: false
object_class: { src: 1 dst: 0} # obj class 1 -> cvg index 0
}
detectnet_augmentation_param: {
crop_prob: 1
shift_x: 32
shift_y: 32
flip_prob: 0.5
rotation_prob: 0
max_rotate_degree: 5
scale_prob: 0.4
scale_min: 0.8
scale_max: 1.2
hue_rotation_prob: 0.8
hue_rotation: 30
desaturation_prob: 0.8
desaturation_max: 0.8
}
transform_param: {
mean_value: 127
}
include: { phase: TRAIN }
}
layer {
name: "val_transform"
type: "DetectNetTransformation"
bottom: "data"
bottom: "label"
top: "transformed_data"
top: "transformed_label"
detectnet_groundtruth_param: {
stride: 16
scale_cvg: 0.4
gridbox_type: GRIDBOX_MIN
coverage_type: RECTANGULAR
min_cvg_len: 20
obj_norm: true
image_size_x: 640
image_size_y: 640
crop_bboxes: false
object_class: { src: 1 dst: 0} # obj class 1 -> cvg index 0
}
transform_param: {
mean_value: 127
}
include: { phase: TEST stage: "val" }
}
layer {
name: "deploy_transform"
type: "Power"
bottom: "data"
top: "transformed_data"
power_param {
shift: -127
}
include: { phase: TEST not_stage: "val" }
}
# Label conversion layers
layer {
name: "slice-label"
type: "Slice"
bottom: "transformed_label"
top: "foreground-label"
top: "bbox-label"
top: "size-label"
top: "obj-label"
top: "coverage-label"
slice_param {
slice_dim: 1
slice_point: 1
slice_point: 5
slice_point: 7
slice_point: 8
}
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
layer {
name: "coverage-block"
type: "Concat"
bottom: "foreground-label"
bottom: "foreground-label"
bottom: "foreground-label"
bottom: "foreground-label"
top: "coverage-block"
concat_param {
concat_dim: 1
}
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
layer {
name: "size-block"
type: "Concat"
bottom: "size-label"
bottom: "size-label"
top: "size-block"
concat_param {
concat_dim: 1
}
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
layer {
name: "obj-block"
type: "Concat"
bottom: "obj-label"
bottom: "obj-label"
bottom: "obj-label"
bottom: "obj-label"
top: "obj-block"
concat_param {
concat_dim: 1
}
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
layer {
name: "bb-label-norm"
type: "Eltwise"
bottom: "bbox-label"
bottom: "size-block"
top: "bbox-label-norm"
eltwise_param {
operation: PROD
}
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
layer {
name: "bb-obj-norm"
type: "Eltwise"
bottom: "bbox-label-norm"
bottom: "obj-block"
top: "bbox-obj-label-norm"
eltwise_param {
operation: PROD
}
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
######################################################################
# Start of convolutional network
######################################################################
layer {
name: "conv1/7x7_s2"
type: "Convolution"
bottom: "transformed_data"
top: "conv1/7x7_s2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 3
kernel_size: 7
stride: 2
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "conv1/relu_7x7"
type: "ReLU"
bottom: "conv1/7x7_s2"
top: "conv1/7x7_s2"
}
layer {
name: "pool1/3x3_s2"
type: "Pooling"
bottom: "conv1/7x7_s2"
top: "pool1/3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "pool1/norm1"
type: "LRN"
bottom: "pool1/3x3_s2"
top: "pool1/norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2/3x3_reduce"
type: "Convolution"
bottom: "pool1/norm1"
top: "conv2/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "conv2/relu_3x3_reduce"
type: "ReLU"
bottom: "conv2/3x3_reduce"
top: "conv2/3x3_reduce"
}
layer {
name: "conv2/3x3"
type: "Convolution"
bottom: "conv2/3x3_reduce"
top: "conv2/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 192
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "conv2/relu_3x3"
type: "ReLU"
bottom: "conv2/3x3"
top: "conv2/3x3"
}
layer {
name: "conv2/norm2"
type: "LRN"
bottom: "conv2/3x3"
top: "conv2/norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool2/3x3_s2"
type: "Pooling"
bottom: "conv2/norm2"
top: "pool2/3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
########################################################### 3a starts
layer {
name: "inception_3a/1x1"
type: "Convolution"
bottom: "pool2/3x3_s2"
top: "inception_3a/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_1x1"
type: "ReLU"
bottom: "inception_3a/1x1"
top: "inception_3a/1x1"
}
layer {
name: "inception_3a/3x3_reduce"
type: "Convolution"
bottom: "pool2/3x3_s2"
top: "inception_3a/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_3a/3x3_reduce"
top: "inception_3a/3x3_reduce"
}
layer {
name: "inception_3a/3x3"
type: "Convolution"
bottom: "inception_3a/3x3_reduce"
top: "inception_3a/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_3x3"
type: "ReLU"
bottom: "inception_3a/3x3"
top: "inception_3a/3x3"
}
layer {
name: "inception_3a/5x5_reduce"
type: "Convolution"
bottom: "pool2/3x3_s2"
top: "inception_3a/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_3a/5x5_reduce"
top: "inception_3a/5x5_reduce"
}
layer {
name: "inception_3a/5x5"
type: "Convolution"
bottom: "inception_3a/5x5_reduce"
top: "inception_3a/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_5x5"
type: "ReLU"
bottom: "inception_3a/5x5"
top: "inception_3a/5x5"
}
layer {
name: "inception_3a/pool"
type: "Pooling"
bottom: "pool2/3x3_s2"
top: "inception_3a/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_3a/pool_proj"
type: "Convolution"
bottom: "inception_3a/pool"
top: "inception_3a/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_3a/relu_pool_proj"
type: "ReLU"
bottom: "inception_3a/pool_proj"
top: "inception_3a/pool_proj"
}
################################################################### start of connecting block
layer {
name: "inception_3a/output"
type: "Concat"
bottom: "inception_3a/1x1"
bottom: "inception_3a/3x3"
bottom: "inception_3a/5x5"
bottom: "inception_3a/pool_proj"
top: "inception_3a/output"
}
################################################################### 3a finish
################################################################### start of connecting block
layer {
name: "pool3/3x3_s2"
type: "Pooling"
bottom: "inception_3a/output"
top: "pool3/3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
################################################################### 4a starts
layer {
name: "inception_4a/1x1"
type: "Convolution"
bottom: "pool3/3x3_s2"
top: "inception_4a/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 192
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_1x1"
type: "ReLU"
bottom: "inception_4a/1x1"
top: "inception_4a/1x1"
}
layer {
name: "inception_4a/3x3_reduce"
type: "Convolution"
bottom: "pool3/3x3_s2"
top: "inception_4a/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_4a/3x3_reduce"
top: "inception_4a/3x3_reduce"
}
layer {
name: "inception_4a/3x3"
type: "Convolution"
bottom: "inception_4a/3x3_reduce"
top: "inception_4a/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 208
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_3x3"
type: "ReLU"
bottom: "inception_4a/3x3"
top: "inception_4a/3x3"
}
layer {
name: "inception_4a/5x5_reduce"
type: "Convolution"
bottom: "pool3/3x3_s2"
top: "inception_4a/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_4a/5x5_reduce"
top: "inception_4a/5x5_reduce"
}
layer {
name: "inception_4a/5x5"
type: "Convolution"
bottom: "inception_4a/5x5_reduce"
top: "inception_4a/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 48
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_5x5"
type: "ReLU"
bottom: "inception_4a/5x5"
top: "inception_4a/5x5"
}
layer {
name: "inception_4a/pool"
type: "Pooling"
bottom: "pool3/3x3_s2"
top: "inception_4a/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_4a/pool_proj"
type: "Convolution"
bottom: "inception_4a/pool"
top: "inception_4a/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_pool_proj"
type: "ReLU"
bottom: "inception_4a/pool_proj"
top: "inception_4a/pool_proj"
}
################################################################### 4a finish
layer {
name: "inception_4a/output"
type: "Concat"
bottom: "inception_4a/1x1"
bottom: "inception_4a/3x3"
bottom: "inception_4a/5x5"
bottom: "inception_4a/pool_proj"
top: "inception_4a/output"
}
################################################################### start of connecting block
layer {
name: "inception_5a/1x1"
type: "Convolution"
bottom: "inception_4a/output"
top: "inception_5a/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_1x1"
type: "ReLU"
bottom: "inception_5a/1x1"
top: "inception_5a/1x1"
}
layer {
name: "inception_5a/3x3_reduce"
type: "Convolution"
bottom: "inception_4a/output"
top: "inception_5a/3x3_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 160
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.09
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_3x3_reduce"
type: "ReLU"
bottom: "inception_5a/3x3_reduce"
top: "inception_5a/3x3_reduce"
}
layer {
name: "inception_5a/3x3"
type: "Convolution"
bottom: "inception_5a/3x3_reduce"
top: "inception_5a/3x3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 320
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_3x3"
type: "ReLU"
bottom: "inception_5a/3x3"
top: "inception_5a/3x3"
}
layer {
name: "inception_5a/5x5_reduce"
type: "Convolution"
bottom: "inception_4a/output"
top: "inception_5a/5x5_reduce"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.2
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_5x5_reduce"
type: "ReLU"
bottom: "inception_5a/5x5_reduce"
top: "inception_5a/5x5_reduce"
}
layer {
name: "inception_5a/5x5"
type: "Convolution"
bottom: "inception_5a/5x5_reduce"
top: "inception_5a/5x5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 2
kernel_size: 5
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_5x5"
type: "ReLU"
bottom: "inception_5a/5x5"
top: "inception_5a/5x5"
}
layer {
name: "inception_5a/pool"
type: "Pooling"
bottom: "inception_4a/output"
top: "inception_5a/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "inception_5a/pool_proj"
type: "Convolution"
bottom: "inception_5a/pool"
top: "inception_5a/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_pool_proj"
type: "ReLU"
bottom: "inception_5a/pool_proj"
top: "inception_5a/pool_proj"
}
################################################################### start of connecting block
layer {
name: "inception_5a/output"
type: "Concat"
bottom: "inception_5a/1x1"
bottom: "inception_5a/3x3"
bottom: "inception_5a/5x5"
bottom: "inception_5a/pool_proj"
top: "inception_5a/output"
}
################################################################### start of connecting block
layer {
name: "pool5/drop_s1"
type: "Dropout"
bottom: "inception_5a/output"
top: "pool5/drop_s1"
dropout_param {
dropout_ratio: 0.4
}
}
layer {
name: "cvg/classifier"
type: "Convolution"
bottom: "pool5/drop_s1"
top: "cvg/classifier"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 1
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.
}
}
}
layer {
name: "coverage/sig"
type: "Sigmoid"
bottom: "cvg/classifier"
top: "coverage"
}
layer {
name: "bbox/regressor"
type: "Convolution"
bottom: "pool5/drop_s1"
top: "bboxes"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 4
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.
}
}
}
######################################################################
# End of convolutional network
######################################################################
# Convert bboxes
layer {
name: "bbox_mask"
type: "Eltwise"
bottom: "bboxes"
bottom: "coverage-block"
top: "bboxes-masked"
eltwise_param {
operation: PROD
}
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
layer {
name: "bbox-norm"
type: "Eltwise"
bottom: "bboxes-masked"
bottom: "size-block"
top: "bboxes-masked-norm"
eltwise_param {
operation: PROD
}
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
layer {
name: "bbox-obj-norm"
type: "Eltwise"
bottom: "bboxes-masked-norm"
bottom: "obj-block"
top: "bboxes-obj-masked-norm"
eltwise_param {
operation: PROD
}
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
# Loss layers
layer {
name: "bbox_loss"
type: "L1Loss"
bottom: "bboxes-obj-masked-norm"
bottom: "bbox-obj-label-norm"
top: "loss_bbox"
loss_weight: 2
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
layer {
name: "coverage_loss"
type: "EuclideanLoss"
bottom: "coverage"
bottom: "coverage-label"
top: "loss_coverage"
include { phase: TRAIN }
include { phase: TEST stage: "val" }
}
# Cluster bboxes
layer {
type: 'Python'
name: 'cluster'
bottom: 'coverage'
bottom: 'bboxes'
top: 'bbox-list'
python_param {
module: 'caffe.layers.detectnet.clustering'
layer: 'ClusterDetections'
param_str : '640, 640, 16, 0.6, 2, 0.02, 22, 1'
}
include: { phase: TEST }
}
# Calculate mean average precision
layer {
type: 'Python'
name: 'cluster_gt'
bottom: 'coverage-label'
bottom: 'bbox-label'
top: 'bbox-list-label'
python_param {
module: 'caffe.layers.detectnet.clustering'
layer: 'ClusterGroundtruth'
param_str : '640, 640, 16, 1'
}
include: { phase: TEST stage: "val" }
}
layer {
type: 'Python'
name: 'score'
bottom: 'bbox-list-label'
bottom: 'bbox-list'
top: 'bbox-list-scored'
python_param {
module: 'caffe.layers.detectnet.mean_ap'
layer: 'ScoreDetections'
}
include: { phase: TEST stage: "val" }
}
layer {
type: 'Python'
name: 'mAP'
bottom: 'bbox-list-scored'
top: 'mAP'
top: 'precision'
top: 'recall'
python_param {
module: 'caffe.layers.detectnet.mean_ap'
layer: 'mAP'
param_str : '640, 640, 16'
}
include: { phase: TEST stage: "val" }
}
I'll have to have a go at training a model with this network on my wasp images.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.