 SHAOS
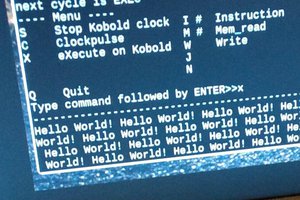
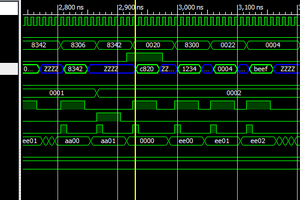
SHAOSIdea of Super-V appeared in my head when I worked on Retro-V - lightweight RISC-V RV32I implementation with 8-bit external data bus. I thought what if external data bus will be 64-bit? In this case we can read TWO 32-bit instructions at once (or even FOUR 16-bit "compressed" instructions). In order to work with such throughput we will need Superscalar approach...
0%
0%
Super-V
Research possibilities for superscalar 32-bit RISC-V under GPL v3
Become a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests



 Erik Piehl
Erik Piehl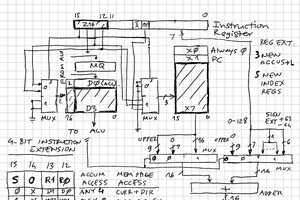
 zpekic
zpekic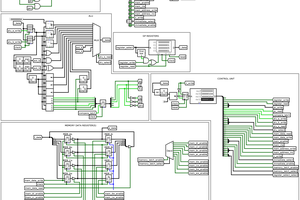
GPL is a virus yes, but not good, if something is GPL tagged and your kids are starving GPL makes sure you cant use that GPL infected code pay for the food. If you license something under GPL (like the hw RTL) and it is really good it would be stolen anyway, but from those who can afford layers, if a small guys does it, he gets into trouble, big corporations not. GPL is nonsense for RTL designs.