 michal.nand
michal.nandRobot hardware
- cortex m4f mcu, 72MHz, stm32f303
- motor driver TI drv8834
- pololu HP motors 1:30 with magnetic encoders
- pololu 28mm tyres, high adhesion
- IMU (gyro + accelerometer) LSM6DS0
- 8 line sensors sensitive for green light (540nm), 3 IR obstacle sensors
- 180mAh LiPol 2S acu
- USB programming via bootloader

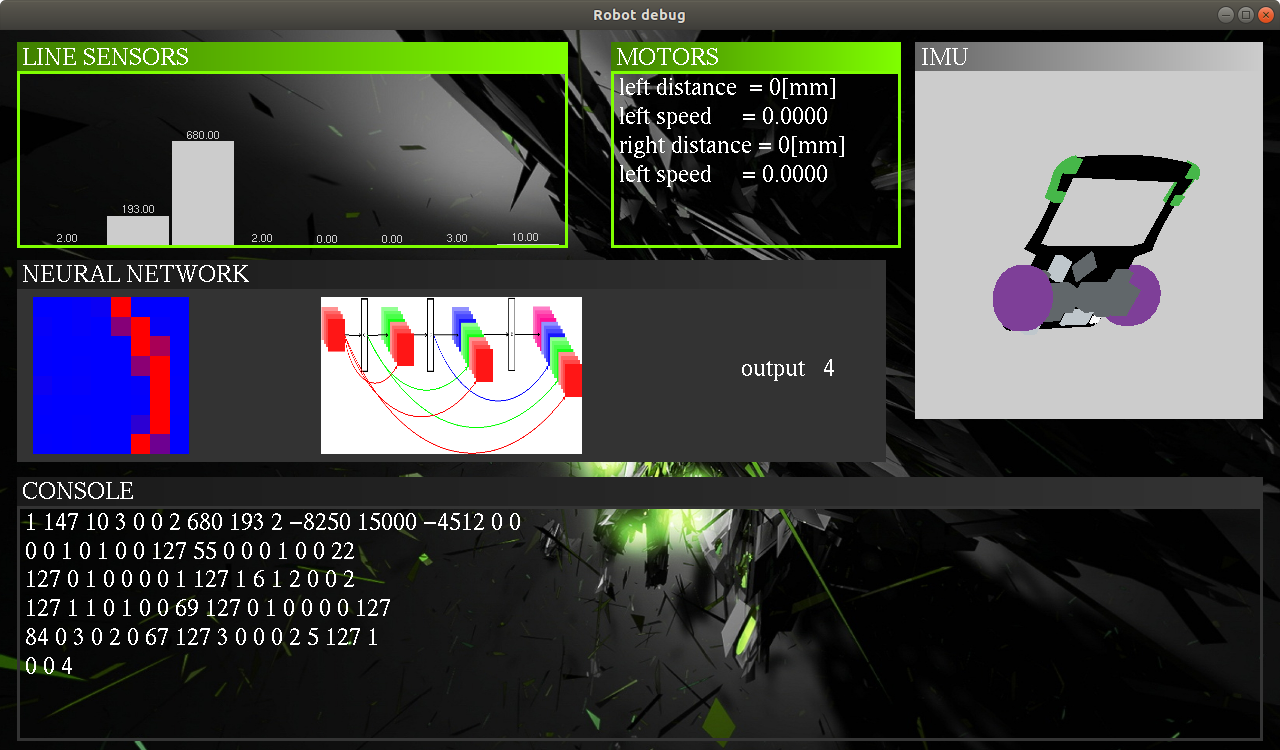
opengl debug application
I created user friendly debug application, showing :
- line sensor raw data
- motors status - speed, encoders
- IMU
- neural network classification process
- raw data from USART
Robot software is based on this key points :
- quadratic interpolation : high precission line position computing
- main loop running on 200Hz
- steering PID : PD controller for steering
- motor PID : two PIDs for motors speed controll
- curve shape prediction : run on straight line, brake on curve; deep neural network
- written in C++
- network training on GPU - own framework for CNN
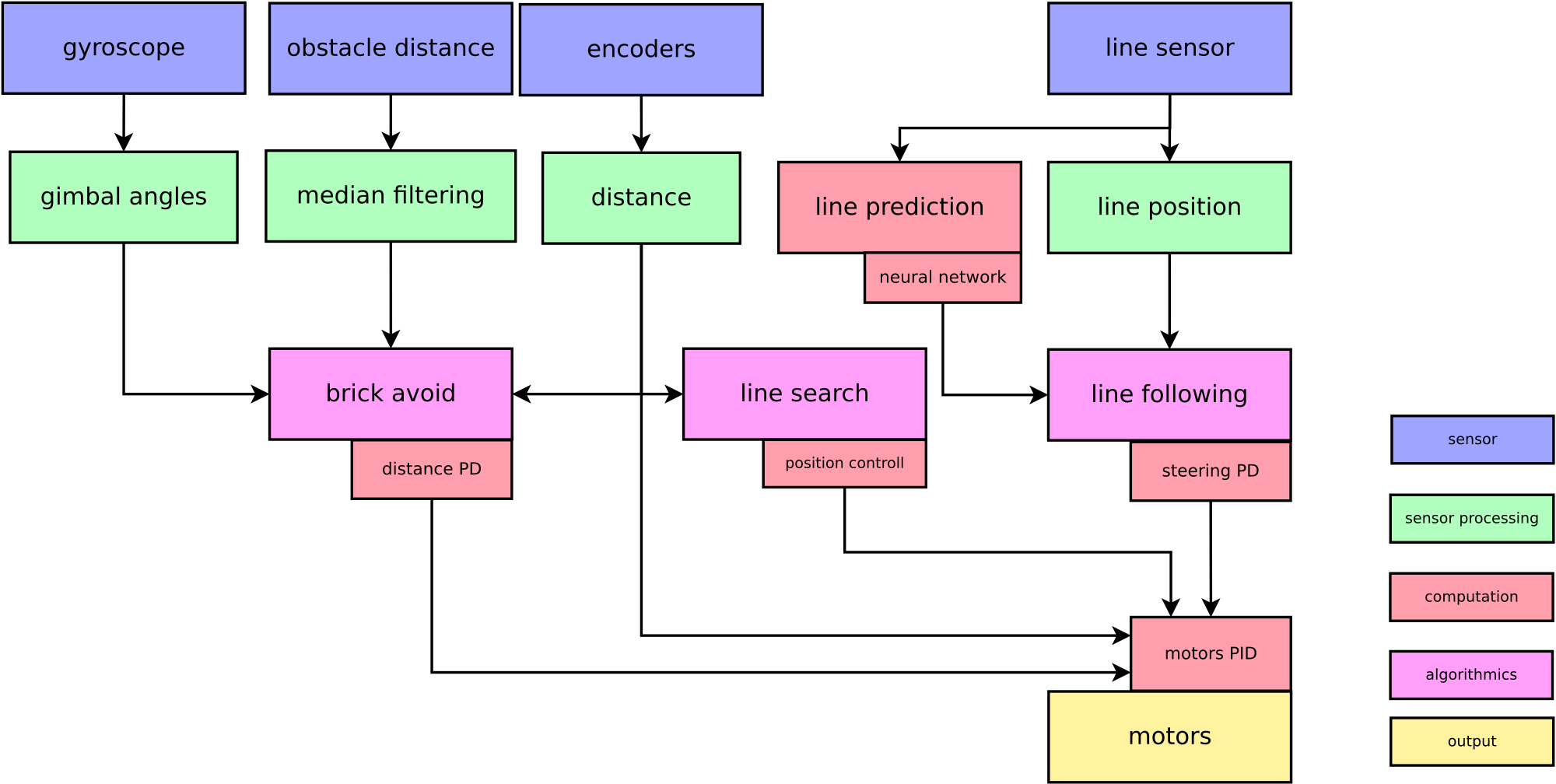
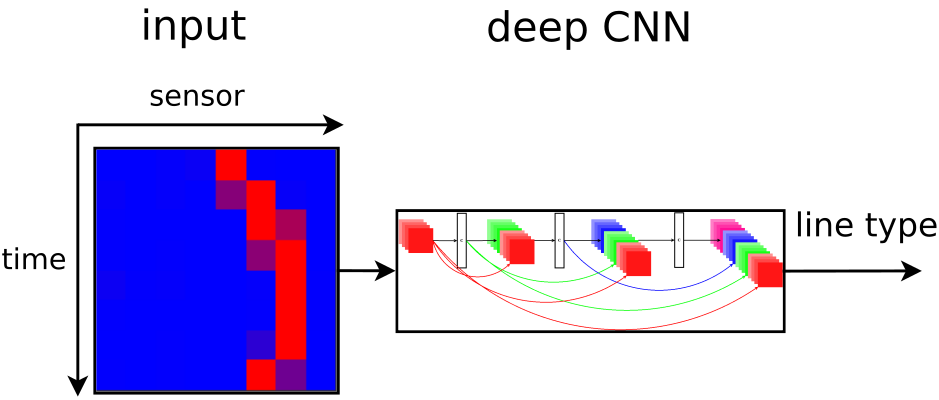
Neural network for line shape prediction
- fast run on straight line, brake on curve
- neural network for line type classification, DenseNet - densely connected convolutional neural network
- input 8x8 matrix raw data from line sensors, 8 past line positions from 8 sensors
- output 5 curves types (two right, two left, one straight
Line prediction idea from last 8 line positions is on following figure
Line dataset was made as artificially generated data,
- 25000 for training
- 5000 for testing
- augmentation - luma noise, white noise

Network architecture
I was fighting with robustness against network speed. Network have to run 200Hz.
I decide to use DenseNet, which is very computation effective - in layers you need less kernels than in pure CNN.
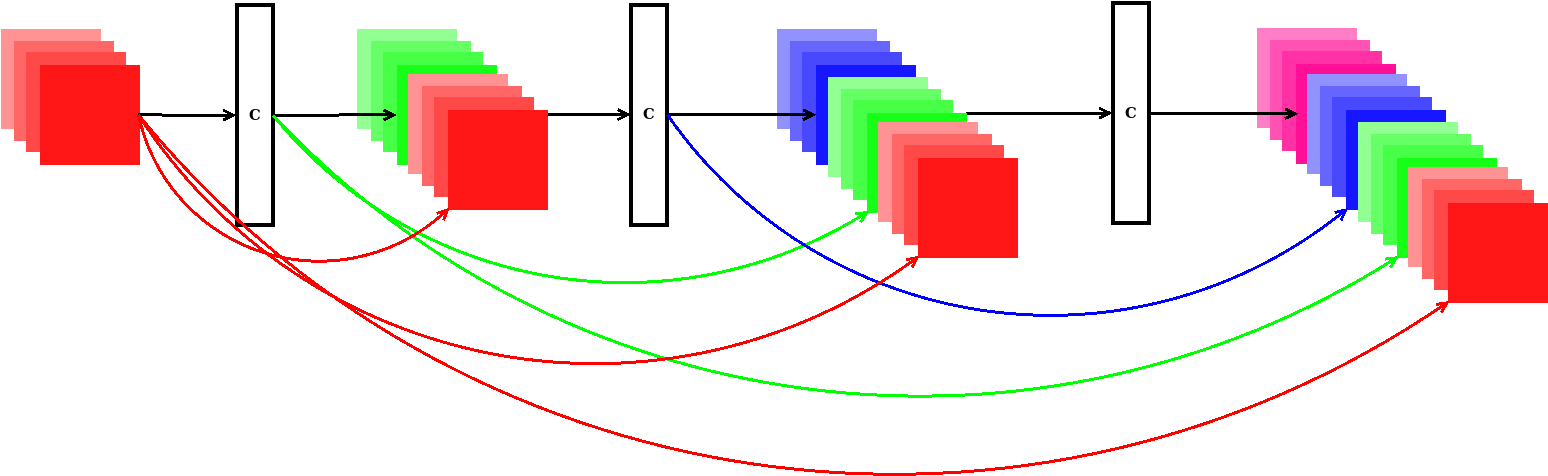
Final network architecture is :
which is able to achieve 95% classification accuracy
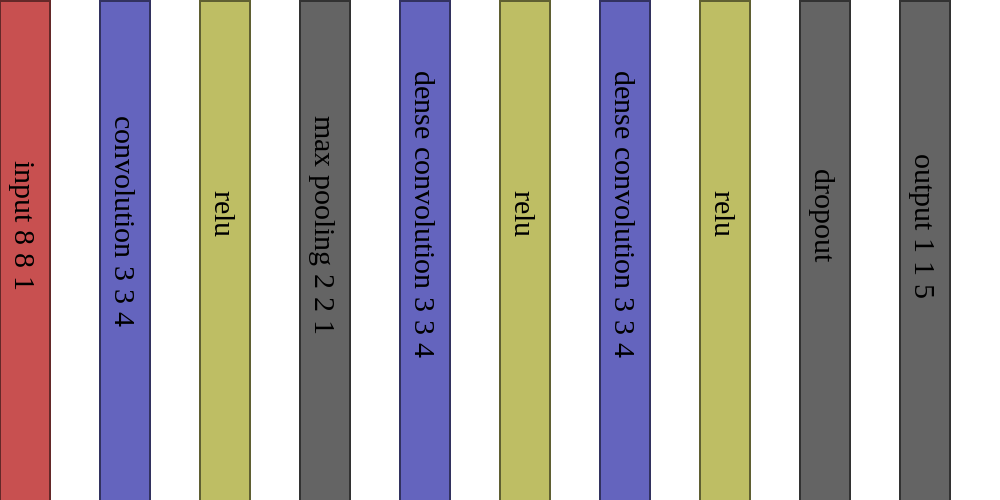
| layer | layer type | input feature map tensor size |
| 0 | convolution 3x3x4 | 8x8x1 |
| 1 | max pooling 2x2 | 8x8x4 |
| 2 | dense convolution 3x3x4 | 4x4x4 |
| 3 | dense convolution
3x3x4 | 4x4x8 |
| 4 | full connected 5 | 4x4x12 |
Fitting network into embedded
- convert float weights to int8_t
- scale weights into 8bit range
- use double buffer memory trick - to save memory, use only two common buffers for all layers





 Anmol Chopra
Anmol Chopra
 Inderpreet Singh
Inderpreet Singh

 Capt. Flatus O'Flaherty ☠
Capt. Flatus O'Flaherty ☠
how did you train the robot? and why the IMU?