 biemster
biemsterThe workflow will be as follows:
- Find the trained models (DONE)
- Figure out how to import the model in TensorFlow (DONE)
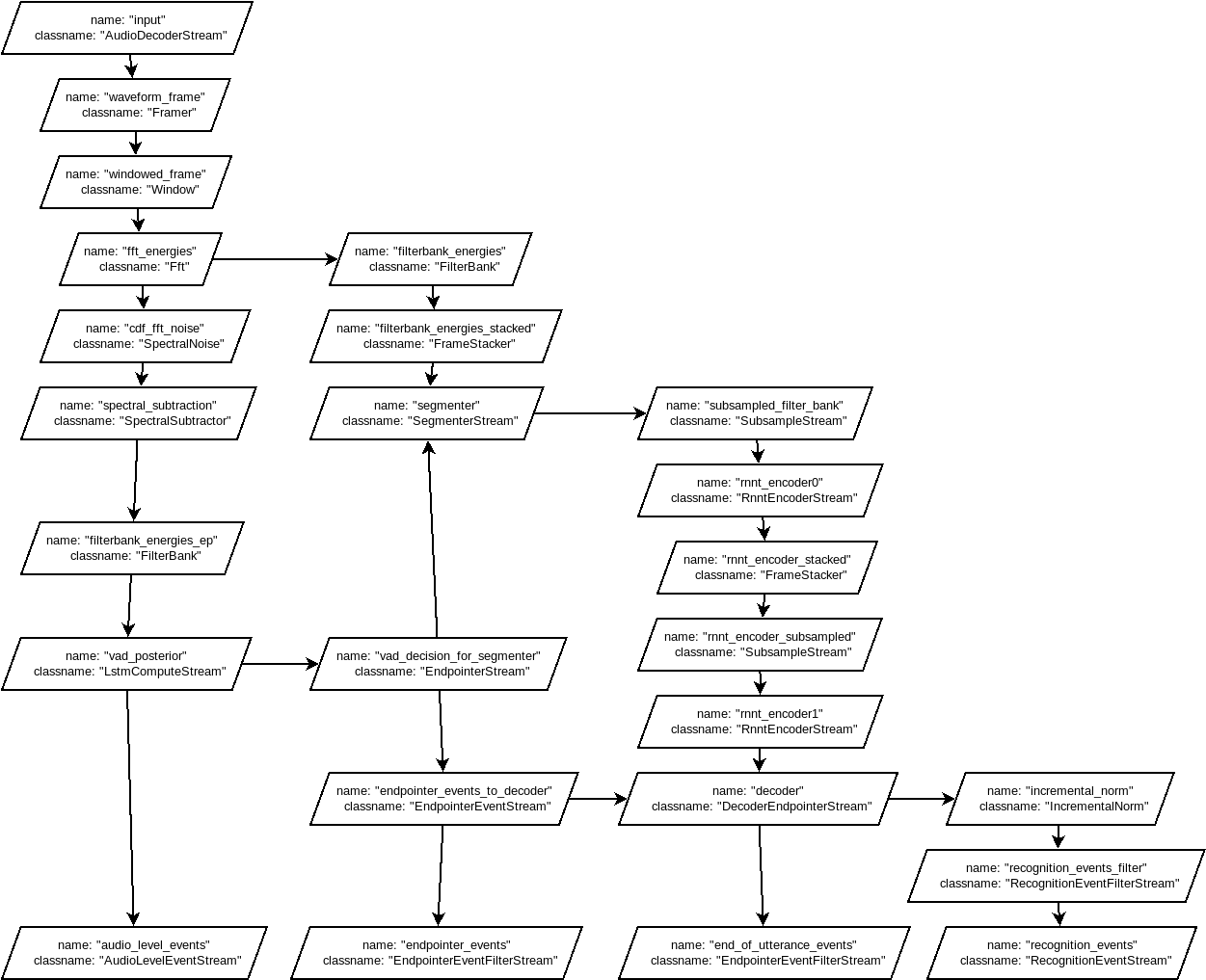
- Figure out how to connect the different inputs and outputs to each other (in progress)
- (optional) export to lwtnn
- Write lightweight application for dictation (DONE)
Finding the trained models was done by reverse engineering the GBoard app using apktool. Further analysis of the app is necessary to find the right parameters to the models, but the initial blog post also provides some useful info:
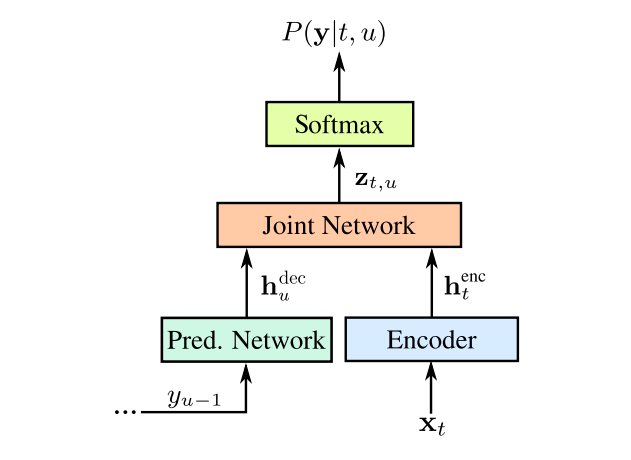
Representation of an RNN-T, with the input audio samples, x, and the predicted symbols y. The predicted symbols (outputs of the Softmax layer) are fed back into the model through the Prediction network, as yu-1, ensuring that the predictions are conditioned both on the audio samples so far and on past outputs. The Prediction and Encoder Networks are LSTM RNNs, the Joint model is a feedforward network (paper). The Prediction Network comprises 2 layers of 2048 units, with a 640-dimensional projection layer. The Encoder Network comprises 8 such layers. Image credit: Chris Thornton
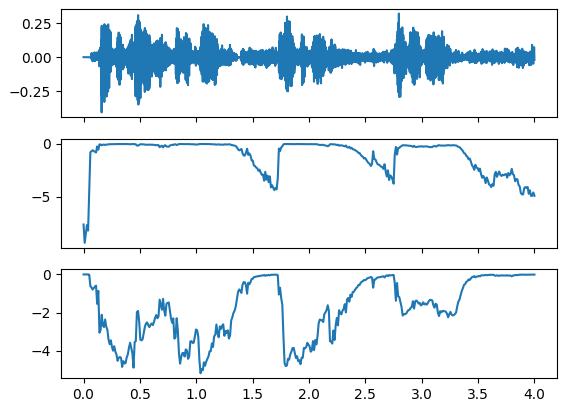
Audio input
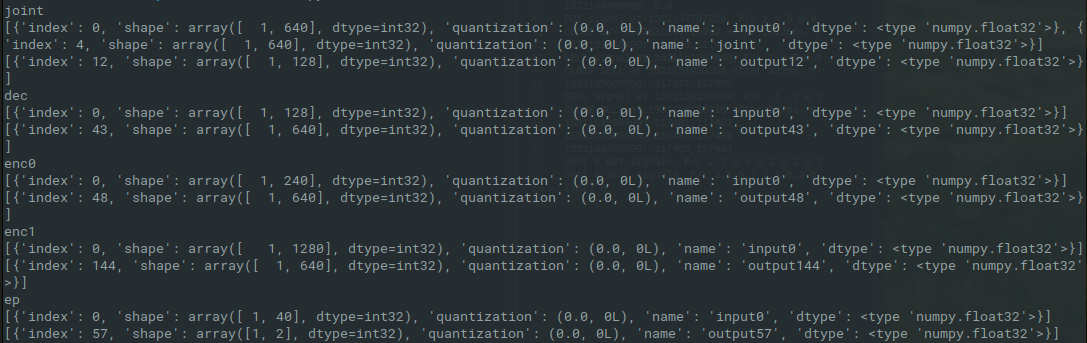
The audio input is probably 80 log-Mel channels, as described in this paper. Gauging from the number of inputs to the first encoder (enc0), 3 frames should be stacked and provided to enc0. Then three more frames should be captured to run enc0 again to obtain a second output. Both those outputs should be fed to the second encoder (enc1) to provide it with a tensor of length 1280. The output of the second encoder is fed to the joint.
Decoder
The decoder is fed with a tensor of zeros at t=0. The output is fed to the joint. In the next iteration the decoder is fed with the output of the softmax layer, which is of lenght 128 and represents the probabilities of the symbol heard in the audio. This way the current symbol depends on all the previous symbols in the sequence.
Joint and softmax
The joint and softmax have the least amount of tweakable parameters. The two inputs of the joint are just the outputs of de decoder and encoder, and the softmax only turns this output into probabilities between 1 and 0.
Overview
I recently found a nice overview presentation of (almost) current research, with an interesting description starting on slide 81 explaining when to advance the encoder and retain the prediction network state.


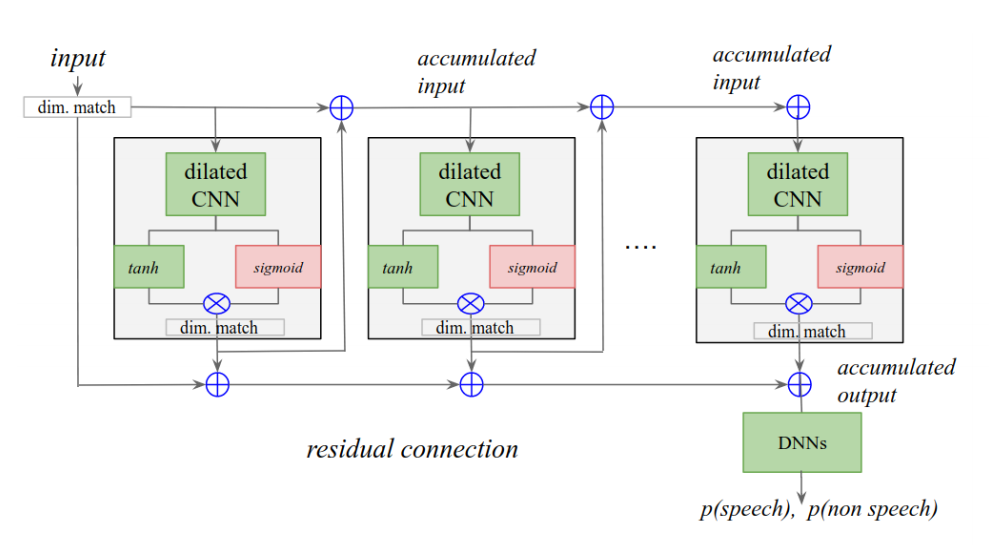











 Ronald Sousa
Ronald Sousa
 Valentin
Valentin
Hi! Awesome project! I'm currently trying to compile it. After downloading the models from Chrome (libsoda version: 1.1.0.1) I'm getting this error:
g++ -o gasr gasr.c -L. -Wl,-rpath,. -lsoda
/usr/bin/ld: /tmp/ccOy0vpm.o: in function `main':
gasr.c:(.text+0x172): referencia a `CreateSodaAsync' sin definir
/usr/bin/ld: gasr.c:(.text+0x22b): reference to `AddAudio' undefined
/usr/bin/ld: gasr.c:(.text+0x24f): reference to `DeleteSodaAsync' undefined
collect2: error: ld returned 1 exit status
make: *** [Makefile:5: gasr] Error 1
Might this be due to some backwards compatibility issue? Maybe the project source code requires an older libsoda version (1.0.X.X)? Should this be the case, any tips on how to get an older lisoda version?
Thanks!!