0%
0%
Hacking Yamaha Disklavier Floppies
An effort to decipher MIDI disks from the 1990s
 Tom Nardi
Tom NardiBecome a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests




 Alex Brown
Alex Brown
 kelu124
kelu124
 Eric Hertz
Eric Hertz
Such a great project. What most surprised me is that you used Python for this. In my mind this type of low-level hacking is always associated with C or C++.
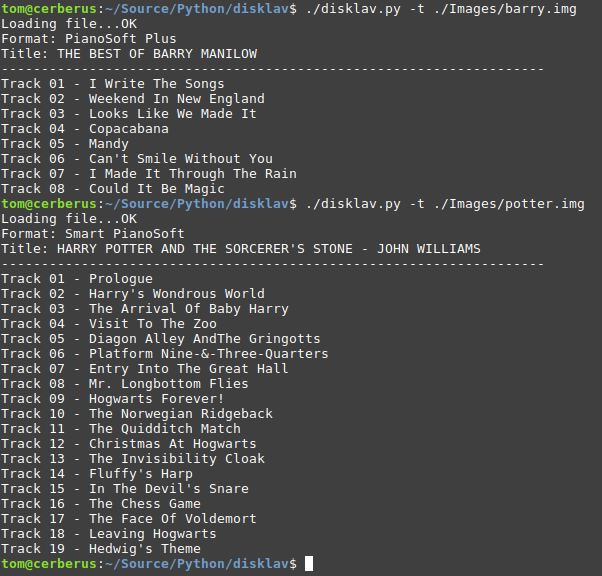
(Why anybody would want to rescue 'The best of Barry Manilow' though is beyond my imagination ..;-)