 Nick Bild
Nick Bild![]()
Doom Air
Play Doom on a giant screen using your body as the controller.
Note: Doom was developed by id Software. I have created a new interface for that game, but not the game itself.
How It Works
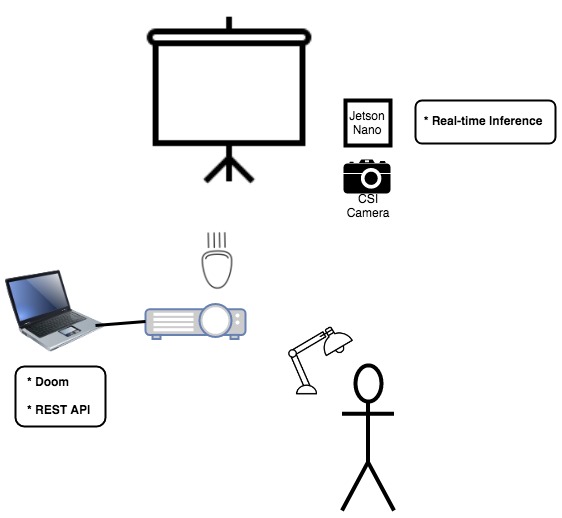
Doom runs on a laptop, which is connected to a projector. The laptop also runs a REST API that simulates physical key presses on the keyboard when each endpoint receives a remote request.
A Jetson Nano has a CSI camera pointed at the subject. It is running a convolutional neural network (CNN) model in real time as images are captured by the camera. When a gesture (of the set of gestures the model has been trained on) is detected, an API request is sent to the laptop. This simulates a keypress, and controls the action in Doom.
Gestures
The CNN has been trained to detect the following gestures.
| Action | Example |
|---|---|
| Forward |  |
| Backward |  |
| Left |  |
| Right |  |
| Shoot |  |
| Use |  |
| Jump |  |
| Crouch |  |
| Next Weapon |  |
| God Mode |  |
| Nothing |  |
Training
The CNN was ultimately trained on 3,300 images (300 per gesture). I tried as many as 32,000 training images, but found that I got a bit sloppy in the course of capturing so many images and some of the gestures were a bit off what I actually wanted detected, so the network would get a bit confused at times. Machine learning requires a lot of data, yes, but the quality of that data also matters.
I found it necessary to capture each gesture from a variety of slightly varying angles and lighting conditions or the resultant network was not tolerant of the unavoidable variances that will be present in real data. Here are a few of the images captured for the 'shoot' gesture, for example:

To capture so many images, I created an automated pipeline that would prompt me for each gesture, then capture images at a specified interval.
Designing the model and finding optimal parameters involved a lot of intuition, trial and error, and time on AWS GPU instances. Trial and error seems to pretty well be the state of the art in machine learning at this time. I'm being slightly flippant in saying this, but only slightly. There are some efforts, such as AutoML that are working to improve the present situation.
It was also necessary to consider that, while the Jetson Nano has some decent AI horsepower, it is limited. So, I needed to keep my models reasonable or they'd run too slow for real time image classification.
I settled on a model with 8 convolutional layers and 2 fully connected layers. It evaluated the test data set with approximately 98% accuracy, and performed very well under real conditions. The depth of the convolutional layers helped pick out higher order features, like arms, legs, head, etc. Too shallow of a network would only pick out basic features like lines, and it would struggle to recognize gestures.
AWS
I trained on g3s.xlarge instances at Amazon AWS, with Nvidia Tesla M60 GPUs. The Deep Learning AMI (Ubuntu) Version 23.1 image has lots of machine learning packages preinstalled, so it's super easy to use. Just launch an EC2 instance from the web dashboard, then clone my github repo:
git clone https://github.com/nickbild/doom_air.git
Then start up a Python3 environment with PyTorch and dependencies and switch to my codebase:
source activate pytorch_p36 cd doom_air
Now, run my training script:
python3 train.py
That's it! Now, watch the output to see when the test accuracy gets to a good level (percentage in the 90s).
This will generate *.model output files from each epoch that you can download, e.g. with scp to use with the infer_rt.py script.
To train for your own gestures, just place your own images in the data folder under train and test. You can make your own folders there if you want to add new gestures.
Evaluation
To make the evaluation rock-solid, I used a few tricks. First, I tested the model out in real time and found what scores were associated with correct gestures. Scores...
Read more »

 alex.miller
alex.miller
