 cristidragomir97
cristidragomir97After building a cool looking but pretty useless prototype, and asking myself a couple of serious questions about the aim of the project, I finally boiled everything down to a concrete goal. The system should solve three core problems of the visually impaired: spatial perception, identification, and navigation.
While the previous implementation was focused on translating spatial perception from one sense to another, the current one is aimed at completely replacing it with the same concepts that are used for localization in mobile robots and drones. This implementation is centered around the Realsense T265 camera which runs the V-SLAM directly on the integrated FPGA. This works similarly to how sailors used to navigate using the movement of the stars and their position. Instead of the stars, there are visual markers, instead of the sextant there are two stereo cameras and instead of a compass, there’s an inertial measuring unit A USB connection streams the data to the connected SBC and provides information for the kinematics system. This can be the propellers of a drone or a differential drive motors on mobile robots. In this case, the output is translated into proportional vibration patterns on the left and right rim of the glasses.
V-SLAM is awesome but it does not cover every requirement for a complete navigation system. Another Realsense camera, the D435i provides a high accuracy depth image that is used for obstacle avoidance and building occupancy maps of indoor environments. Using voice control the users can choose to save the positions of different objects of interest and later navigate to them. With a GPS module, this could be implemented for outdoors later.
Identification is another issue of the visually impaired that the system aims at aiding with. This is clearly to be done by a deep convolutional neural net. There’s plenty of network options available, such as ImageNet, ResNet, Yolo. I chose the Nvidia Jetson Nano because it contains 128 standard CUDA cores, which is supported by all of the popular deep learning frameworks and can run most of the networks at around 30 FPS. The goal of the system is to detect objects and be able to name them but also detect stairs, street crossings and signs adjusting the parameters of the navigation as needed.
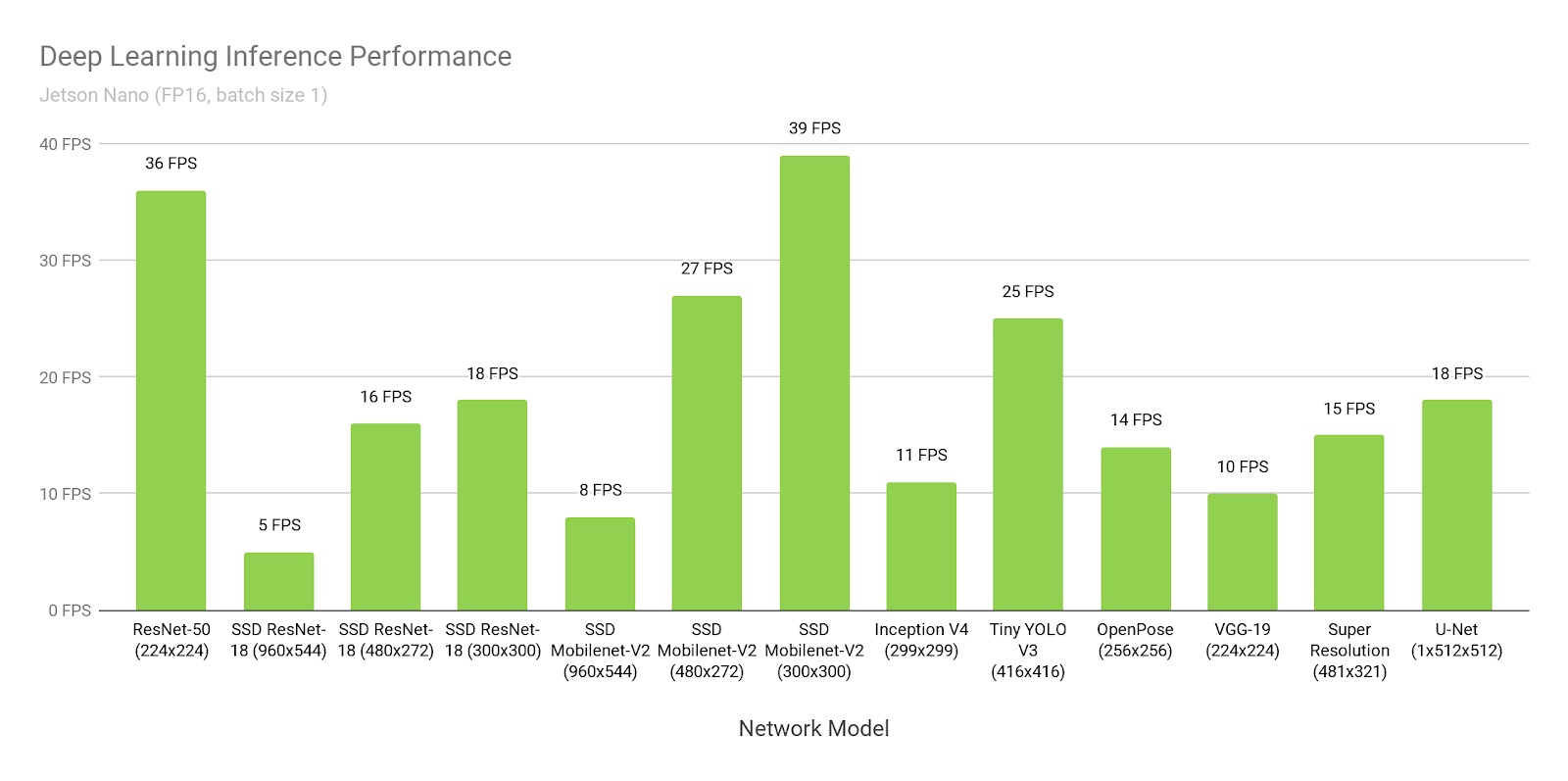
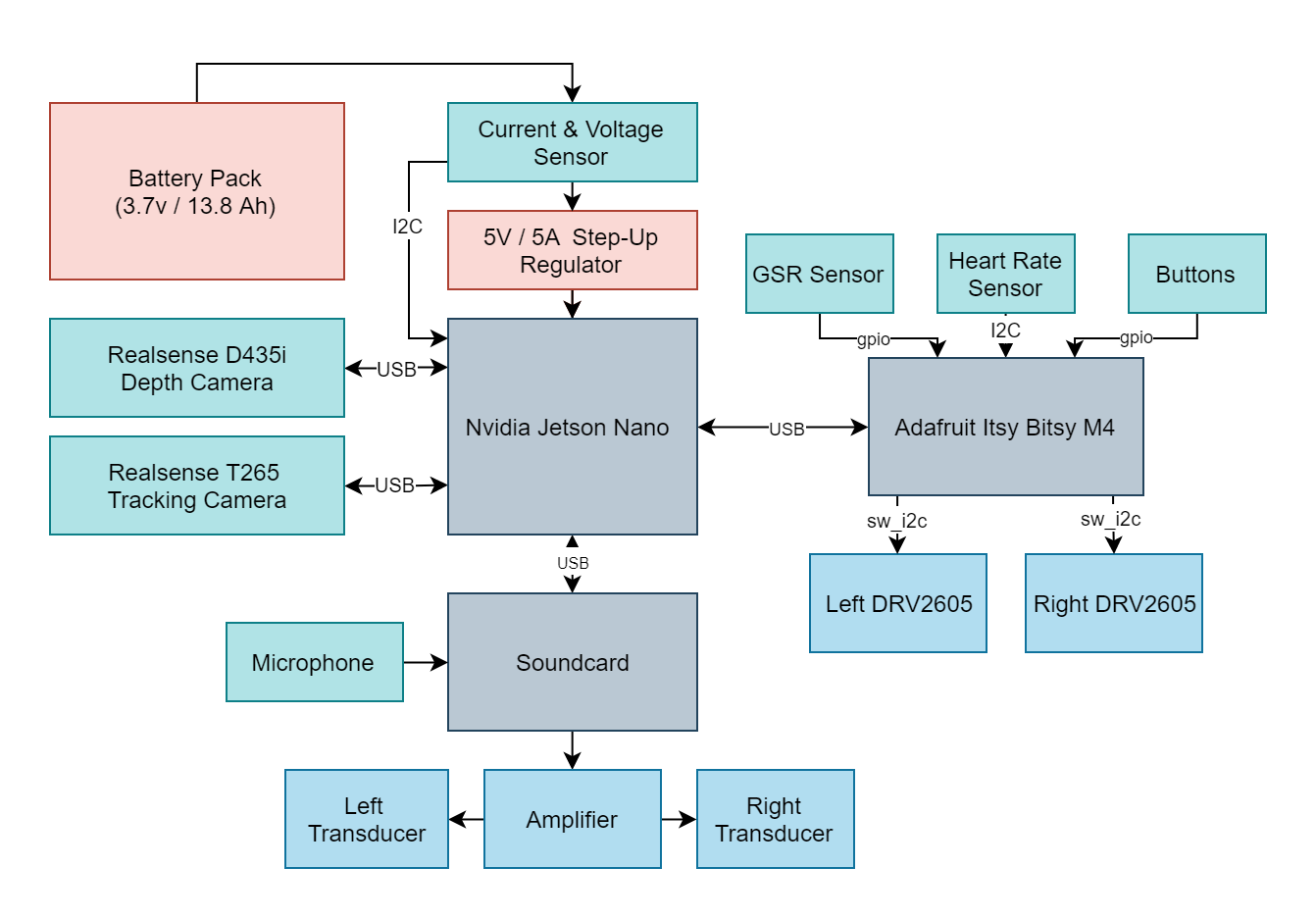
The following hardware platform is going to support the functionality:
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.