 Zack Freedman
Zack FreedmanAll files are on GitHub!
The Somatic project's priorities are:
- Control any wearable computer with a heads-up display
- Ready to use all day, instantly, with no Internet
- Doesn't cause fatigue or interfere with other tasks
- Fast enough to do a quick search in less than 10 seconds
The Somatic will not:
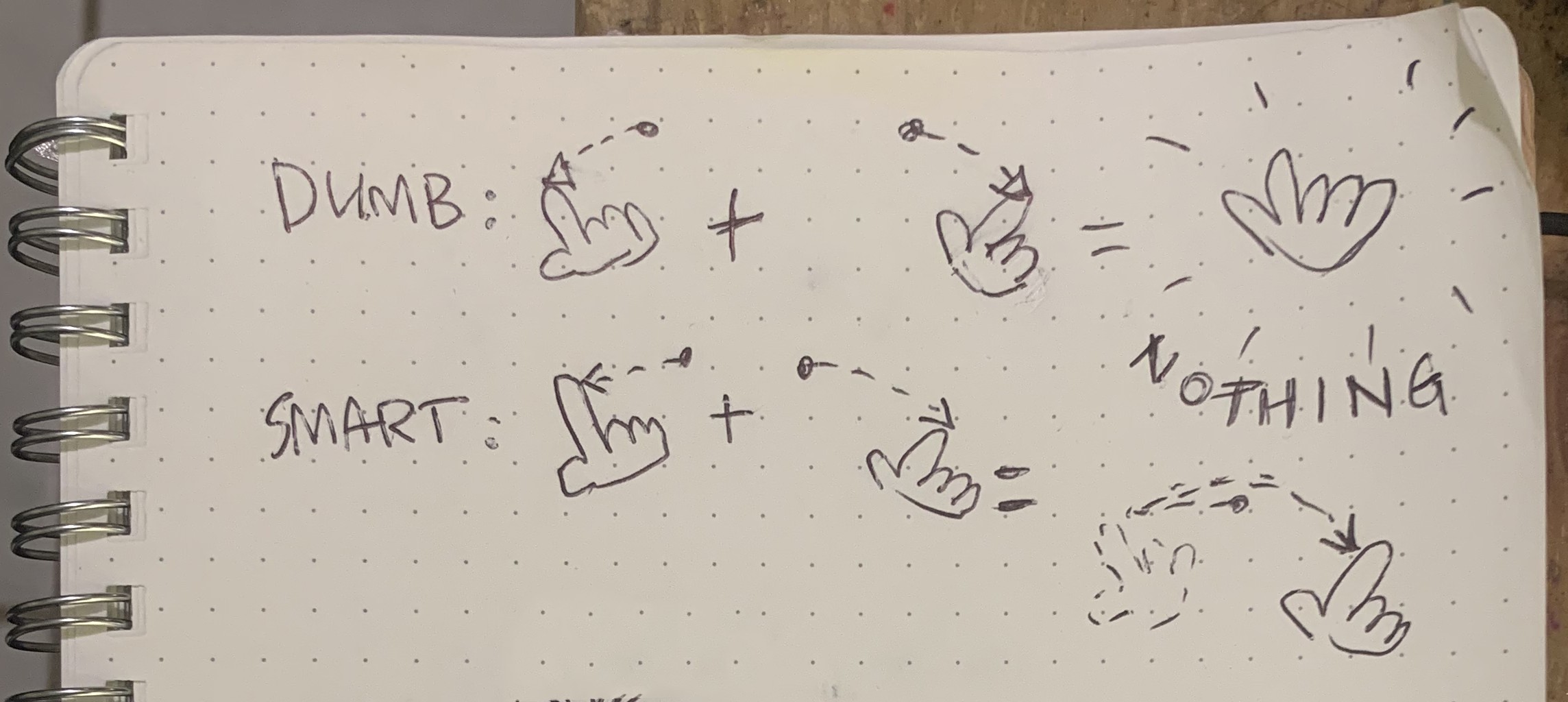
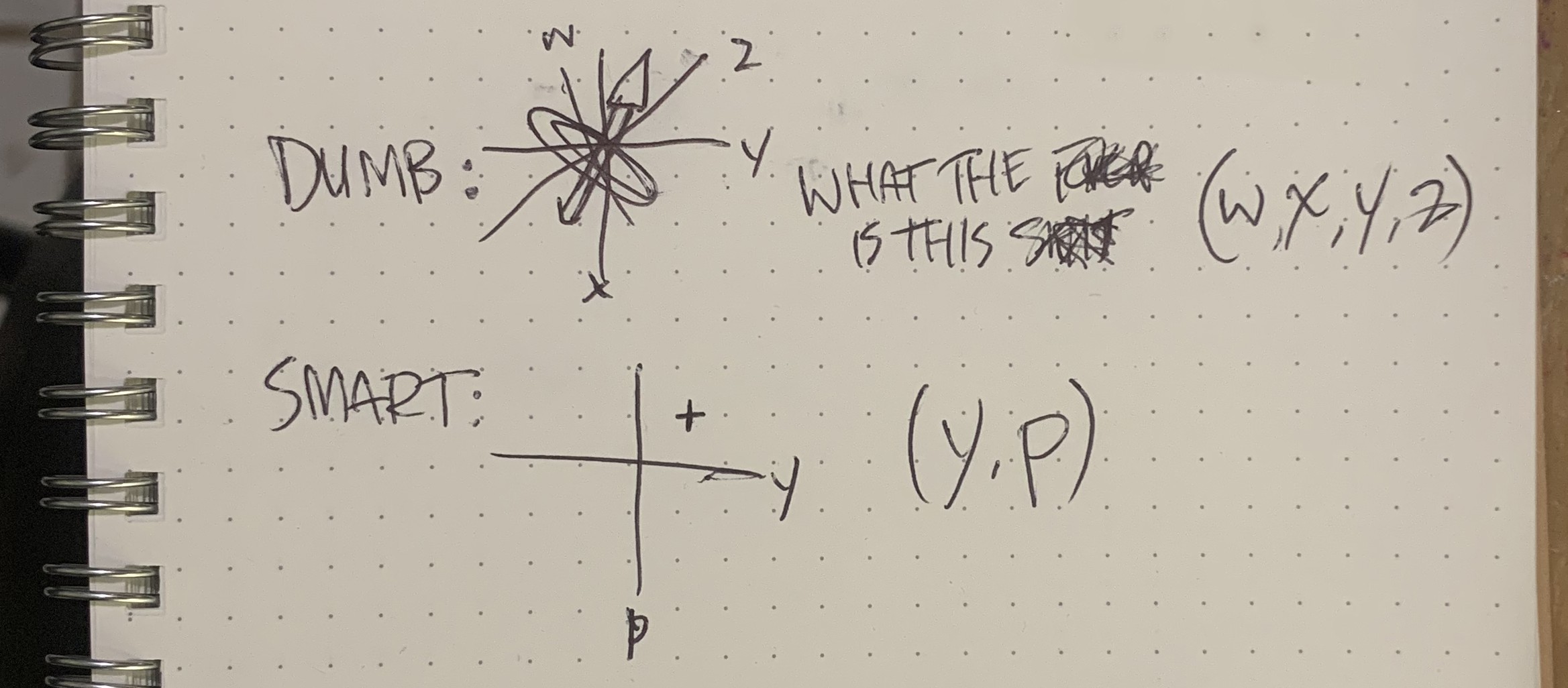
- Reproduce your hand in 3-D space
- Let you type on a virtual keyboard
- Use any cloud services at all
The project is still in a pretty rough state. The roadmap includes:
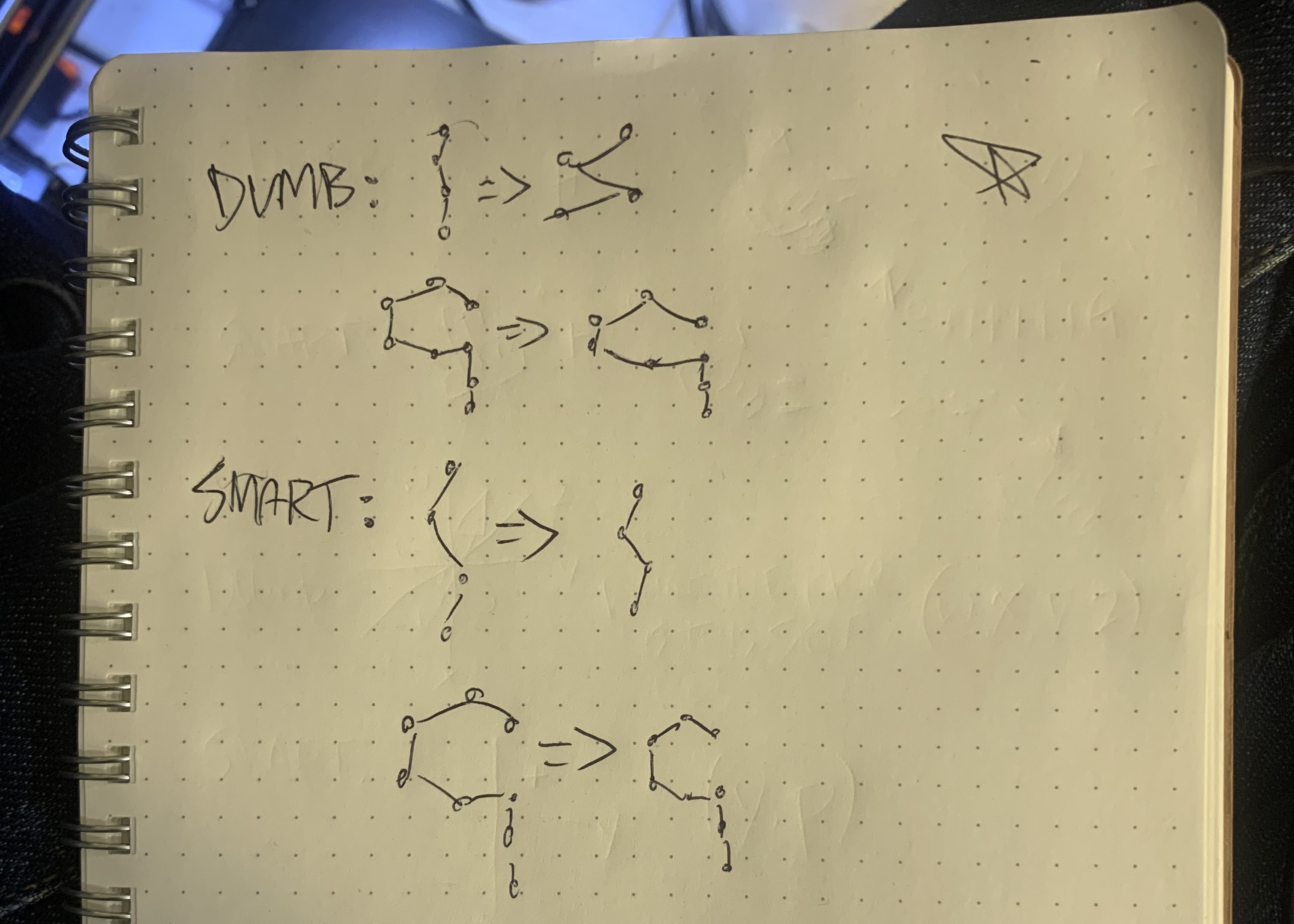
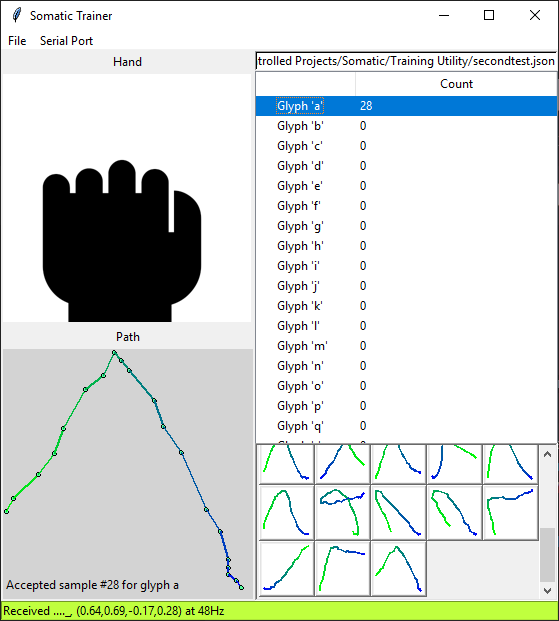
- Collect gesture samples
- Use artificial neural network to recognize letters
- Implement gyro mouse
- Lay out and fab circuit board
- Make case smaller
- Replace on/off Hall sensors with continuous sensors
The Somatic project is MIT licensed, copyright 2019 Zack Freedman and Voidstar Lab.



 Davide Cagnoni
Davide Cagnoni
 ahartman
ahartman
 shager
shager
 Jacob Sayles
Jacob Sayles
This project is very interesting and beautiful. I am also working on a similar project. I have a question. Why do I need four fingers just as a keyboard and mouse? I think one finger is enough.