Goal
The goal of this task was to evaluate how simple a sensor array would be needed to reach object recognition on the MNIST database to a commercial level accuracy.
According to this site, commercial OCR systems have an accuracy of 75% or higher on manuscripts. Maybe on numbers they do better but we'll keep this number as our benchmark.
So there are two ways to test the minimum pixel density needed o identify the MNIST database with 75% accuracy:
1. Grab a handful of sensors, test them against the same algorithm and benchmark them. Time consuming and beyond my budget and time allowance.
2. Try and train a simple object recognition algorithm with a database that reduces in pixel density. Now, that's up my beach.
The algorithm of choice was an easy sell. Since I'm focusing on the lowest denominator, decision trees it is.
Experimental
The database was obviously the MNIST database, the model was a standard decision tree with the standard parameters included with the rpart package in R.
The database was loaded using the code from Kory Beckers GIT project page https://gist.github.com/primaryobjects/b0c8333834debbc15be4 and the matrix containing the data was transformed by averaging neighboring cells as below. Code snippets can be found in the last section. Full code to be uploaded as files.
This is the original 28 x 28 matrix image showing a zero.
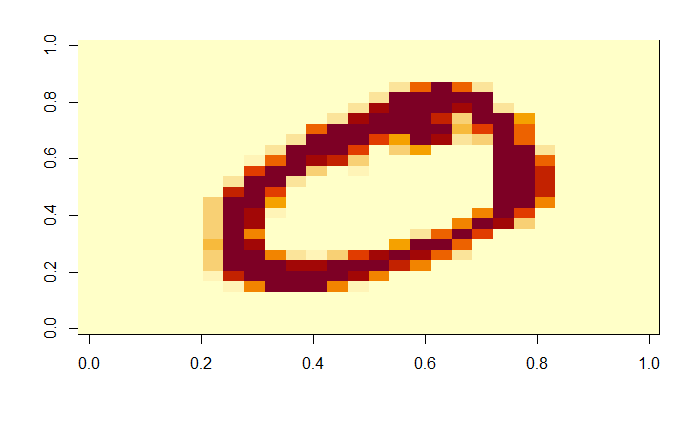
By applying a factor of 2, the matrix becomes a 14x14. Still quite OK.
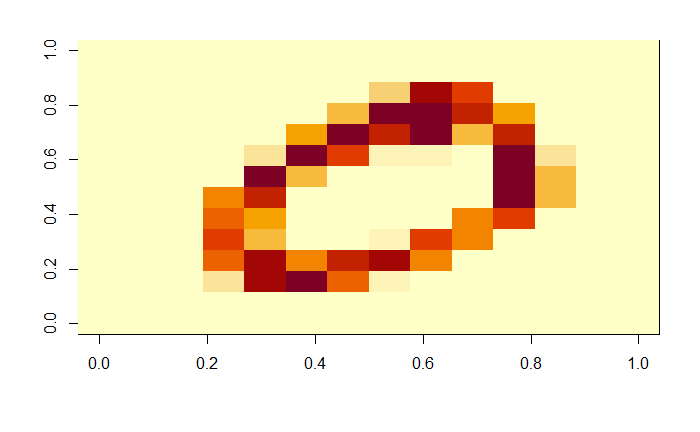
By applying a factor of 4, the matrix became a 7x7 matrix. We humans could have still told this used to be a zero, if you made an effort.
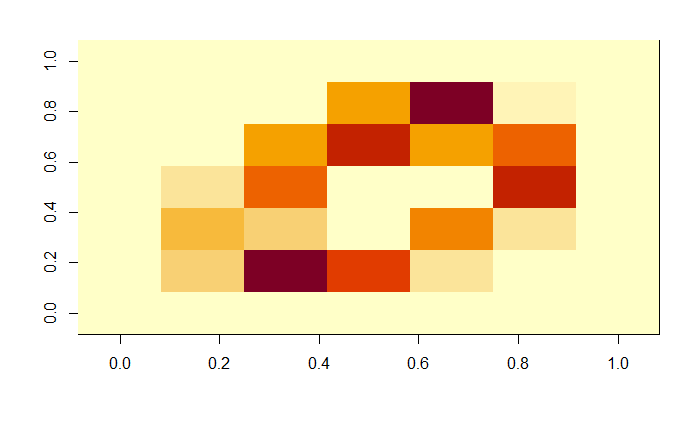 Now what happens when the matrix is reduced by a factor of 7? Is the zero still recognizable? It's really a hard call. It may as well be a one at an angle, or a four. I chose to keep an open mind since I didn't really know how far the algorithm could see things that I couldn't.
Now what happens when the matrix is reduced by a factor of 7? Is the zero still recognizable? It's really a hard call. It may as well be a one at an angle, or a four. I chose to keep an open mind since I didn't really know how far the algorithm could see things that I couldn't.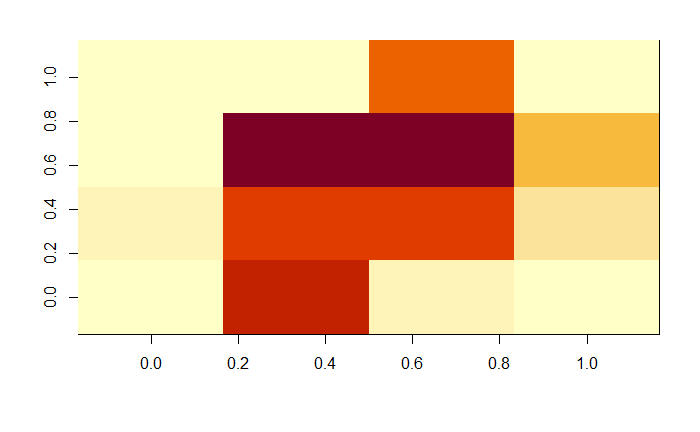
Finally, the last factor was 14, i.e. the initial 28x28 matrix was averaged to a 2x2. This would be a really poor sensor, but I needed to find the point at which the model couldn't tell the numbers apart and then start going up in pixel density.
Modelling
Once the matrix datasets were ready, it was time to see how the lower resolution pictures fared versus the full resolution database when pitched against the standard decision trees using a 10000 record training set.
So, the images could be simplified and the number of pixels reduced by averaging them. The decision tree model had already shown a piss poor accuracy for starters. Less pixels might not affect it much. So let's see how they fared.
As a reference, the full 28x28 matrix with the standard decision tree had the following results:
Overall model accuracy (defined as the sum of the confusion matrix diagonal divided by the total number of tests)
0.6352264
Individual digit accuracy (Obtained by dividing the number of times the number was correctly identified versus the number of times the model thought it recognized the number)
0 1 2 3 4 5 6 7 8 9
0.8389423 0.7935780 0.5443038 0.5704057 0.7194805 0.4305556 0.4661654 0.7780430 0.6292428 0.5324675
That is to say, 63% of the times it got the number right. Some digits like 0, 1, 7 and 4 fared quite well, whereas the other ones didn't really make the cut. Let's keep an open mind nevertheless, a monkey pulling bananas hanging on strings would have gotten 10%. The model is doing something after all.
14 x 14 dataset
There was a clear improvement in classification for all digits with a marginal improvement for the overall accuracy, i.e. less pixels gave a better classification criteria.
This is the equivalent of going out to the pub and starting to see clearer after a few pints. I'm pretty sure our brains have decision trees and not neural networks.
Overall model accuracy
0.6667501
Individual digit accuracy
0 1 2 3 4 5 6 7 8 9
0.8689320 0.8491379 0.5525606 0.5892421 0.5493671 0.4624277 0.5859564 0.8186158 0.5795148 0.7304786
7 x 7 dataset
Accuracy was very similar to the full 28x28 matrix.
At this point things got interesting. I was not expecting the decision tree to fare very good at this stage. All in all, the model was extremely simple an the results not really that much worse than the original matrix. This is with a 2^4 reduction in information density.
Overall model accuracy
0.635977
Individual digit accuracy
0 1 2 3 4 5 6 7 8 9
0.6223278 0.8741573 0.4199475 0.6247031 0.6057441 0.4382353 0.6942529 0.6253102 0.6129032 0.7702020
4 x 4 dataset
The decision tree built with the default configuration was significantly simplified. We were still able to detect number 1 with three pixels and at an acceptable accuracy for something this simple.
The overall accuracy went down significantly at this point, which is not surprising. What was surprising was that the accuracy of the model was much better than whatever I was expecting it to achieve. If you've seen a picture of the variation in shape and angle of the MNIST database, you'd appreciate a decision tree that can tell the numbers apart 50% of the time with just 4 pixels by 4 pixels.
Overall model accuracy
0.5596698
Individual digit accuracy
0 1 2 3 4 5 6 7 8 9
0.5758294 0.7523148 0.4809160 0.3478261 0.4987893 0.2529762 0.7615572 0.7587007 0.5405405 0.5351759
Numbers 1, 3 and 7 could be identified successfully over 75% of the times. Honestly, at this pixel density, it all looked the same to me.
Now, in order to appreciate how simple this system is, attached below is the decision tree generated using the 4 x 4 matrix.
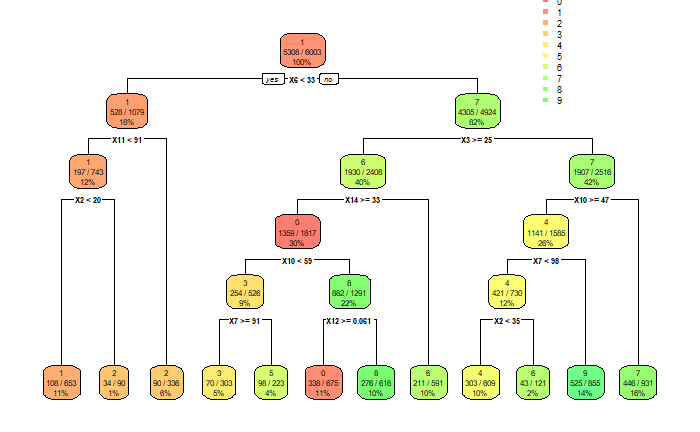
In order to properly classify the number 1, I'd need 3 pixels. For number 7, I'd need two extra pixels. For number 6, another three pixels on top of the two needed to identify number 7. That's a total of 8 pixels in order to identify 3 digits with a 75% accuracy. Now, that is really cool.
Just for reference, this is what a 4x4 zero looked like:I didn't even bother with the 2x2. I was already happy.
Prototyping
So now, before I turned this onto a product I could sell, I needed to prototype it. My go-to prototyping tool was an Arduino Uno. As pixel sensors I settled for LDRs. The reason for this was I had nothing else laying around.
In the Arduino there are only 6 analog inputs so the decision tree had to be simplified even further. For this, we could try and adjust the complexity parameter (cp, see https://www.rdocumentation.org/packages/rpart/versions/4.1-15/topics/rpart for details) in the decision tree in order to get a more palatable solution with 6 or less splits.
Since there was no single solution that could give me a good number of splits with an acceptable accuracy result for all the digits, I decided to compromise and settle for only some digits instead. This was a proof of concept after all.
With a low enough complexity parameter I could get a decision tree that would allow me to identify 3 numbers with an accuracy of over 70% with only 5 pixels, in my 4x4 simplified array.
So now it came to building the prototype. So whilst I tried to gather my pixel sensors, I realized that I only had 3 LDRs. Well, time to compromise again. If I reduced the complexity parameter even further, the decision tree became incredibly dumb. I then tried to train the model with a larger dataset. This gave me the decision tree shown below. With 3 pixels I could identify three numbers with an acceptable accuracy.
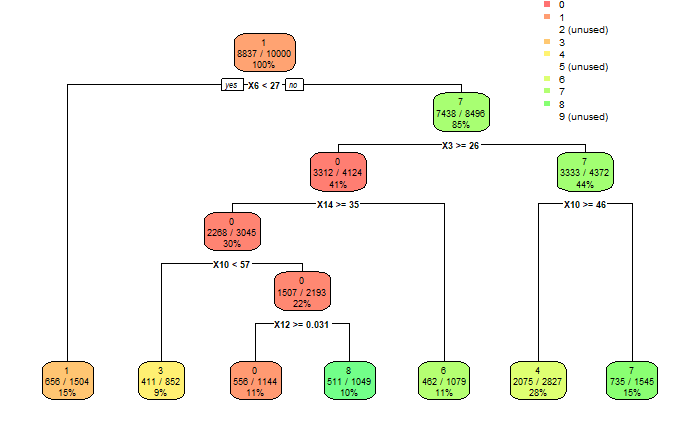
The decision tree is nevertheless ignoring numbers 2, 5 and 9. Don't let "perfect" be the enemy of "some of it works".
The confusion matrix for the above model is attached below.
0 1 2 3 4 5 6 7 8 9 0 911 1 1 0 204 0 59 30 0 0 1 35 1013 33 0 68 0 66 141 0 0 2 275 136 413 0 196 0 136 14 0 0 3 656 35 153 0 177 0 32 183 0 0 4 16 39 0 0 929 0 118 61 0 0 5 509 18 1 0 387 0 84 113 0 0 6 124 24 5 0 268 0 757 2 0 0 7 16 25 20 0 286 0 3 874 0 0 8 696 36 1 0 241 0 143 22 0 0 9 60 4 0 0 882 0 48 218 0 0
The overall accuracy of the model is just over 40%, well shy of the 75% target, but its objective is to validate the concept.
The best accuracy for the individual digits is for numbers 1, 4 and 7, with 60%, 24% and 43% respectively.
Conclusion
The goal of this task was successfully achieved.
- We have a minimum sensor requirement.
- We have a minimum model.
- We have a prototyping platform.
- I have a newly found respect for decision trees.
Next, the Minimum model.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.