 Michael Wessel
Michael WesselAn Iconic Computer & its Voice Synthesizer
Updates:
- 2021/10: Talker/80 in Germany! Great video by "The Homecomputerguy" who took his Talker/80 to the "Classic Computing 2021" fair in Vöhringen! Thanks for the great video and for demoing Talker/80!
- Winner of the 2020 TRS-80 Double-Do Competition!
Check out the December 2020 issue of Dusty's fabulous fanzine. As always, TRS8BIT is a great read and I am always looking forward to the next issue. Many thanks to Dusty and the Competition Committee for this great recognition and price.

- TrashTalk Live #8
- #SepTandy entry - DIY Talker/80 kit assembly for the Model III / Model 4!
About the Talker/80 Project
I am proud newbie owner of a Model 1 since January 2020. I always wanted to have one of these - a member of the 1977 Trinity that started the home computer revolution!
Well, after acquiring 2 untested Model 1 (one from Etsy, one from Ebay) for little money, both requiring 3 weeks of rather intense refurbishment work (including fixing the internal 5V power supply, replacing the 12V overvoltage protection Zener diode, replacing some bad RAM chips, upgrading to Level 2 1.3 ROMs to fix keyboard bouncing problems, getting the FreHD dual boot EPROMs installed, the flex keyboard cable replacement, removing some bad Alps keys, and so on), and the addition of an Extension Interface allowing me to connect my HxC and a real floppy drive to it, finally, after 2 months of work I had 2 fully functional, fully upgraded Model 1. Of course, I also had to install the Lower Chars mod. The Expansion Interface and its ability to display 64 characters per line on a sharp monochrome monitor, combined with the very good Alps keyboard in one of my machines, makes the Model 1 quite useful for text processing. IMHO it provides far better utility for business applications than the other early 8bit machines of that - and later - time; the exception maybe being the Amstrad CPC with its 80 characters per line and CP/M capabilities, but the CPC came almost 8 years later.
Being a fan and collector of vintage speech synthesizers (I must have one of the biggest collections in the world by now...) I REALLY wanted to add the TRS Voice Synthesizer to my setup. But they are scarce, and the last one I saw sold for over 400 $ on Ebay... I am crazy, but not that crazy. So, I thought, if I cannot get the real thing, then at least let's try to port my LambdaSpeak speech synthesizer for the Amstrad CPC to the Model 1. Both the TRS-80 Model 1 and the Amstrad CPC are Z80 machines, but the official vintage speech synthesizers used different chips.

The TRS Voice Synthesizer uses the Votrax SC-01 speech chip, which is unobtainable these days (and single vintage SC-01 chips, if they show up, sell for > 100 $). For LambdaSpeak, I had emulated the GI SP0256-AL2 vintage speech chip - this chip was being used in the "official" CPC speech synthesizer, the Amstrad SSA-1 and the DKtronics synthesizer. I emulated the SP0256-AL2 using DECtalk, by means of a "SP0256-AL2 allophone to DECtalk on the fly phoneme mapping". This works surprisingly well for the SP0, and produces better and more understandable speech than the original. Now, I figured I could do the same "on the fly phoneme mapping" for the Votrax SC-01 and hence implement a TRS Voice Synthesizer emulation. And at the same time, also emulate the other popular historic TRS-80 speech synthesizer, the VS-100 from Alpha Products.

Now, for LambdaSpeak the SP0256-AL2 emulation was a bit easier to achieve, given that I have the original SP0256-AL2 (and Amstrad SSA-1 speech synth that uses it) at hand. But I never even saw a Votrax SC-01. Not even from the distance. But I have the TRS Voice Synthesizer Software, and the VS-100 software. Thanks to the guys on the Vintage Computer Forum, I got some technical information regarding the SC-01 phoneme set, and the mapping of the TRS Voice Synthesizer "ASCII phoneme character set" (a TRS invention) to the SC-01 phonemes. Now I only needed to figure out how to map the SC-01 phonemes to DECtalk phonemes, which required a bit of trial an error.
The SC-01 Phonemes are documented in the Votrax datasheet, and here are the "ASCII" TRS Voice Synthesizer phonemes for some of them - thanks a lot to "Joe Zwerko" (I guess this is not his real name) from the Vintage Computer Forum for providing this scan:
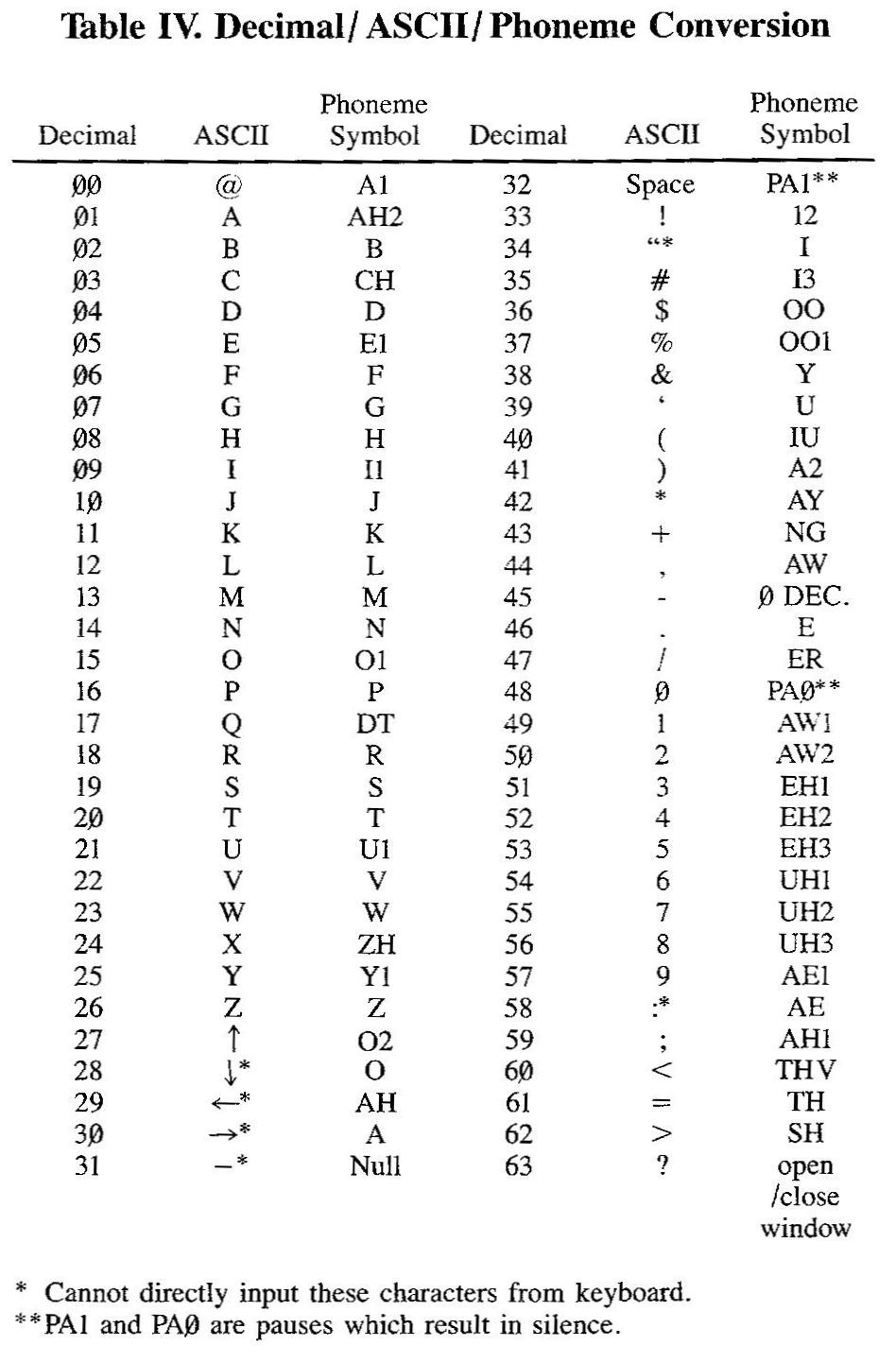
So, roughly, this SC-01 Phoneme mapping to DECtalk ARPABET goes as follows:
void init_allophones(void) {
// VOTRAX SC01 -> ARPABET (DECTALK)
sc01_map[0x00] = "ih"; // EH3 jackEt
sc01_len[0x00] = 59;
sc01_map[0x01] = "eh"; // EH2 Enlist
sc01_len[0x01] = 71;
sc01_map[0x02] = "eh"; // EH1 hEAvy
sc01_len[0x02] = 121;
sc01_map[0x03] = "_"; // PA0 Pause
//sc01_map[0x03] = ""; // PA0 Pause
sc01_len[0x03] = 47;
sc01_map[0x04] = "t"; // DT buTTer
sc01_len[0x04] = 47;
sc01_map[0x05] = "ey"; // A2 mAde
sc01_len[0x05] = 71;
sc01_map[0x06] = "ey"; // A1 mAde
sc01_len[0x06] = 103;
sc01_map[0x07] = "zh"; // ZH aZure
sc01_len[0x07] = 90;
sc01_map[0x08] = "aa"; // AH2 hOnest
sc01_len[0x08] = 71;
sc01_map[0x09] = "ah"; // I3 inhibIt
sc01_len[0x09] = 55;
sc01_map[0x0a] = "ih"; // I2 Inhibit
sc01_len[0x0a] = 80;
sc01_map[0x0b] = "ih"; // I1 InhIbit
sc01_len[0x0b] = 121;
sc01_map[0x0c] = "m"; // M Mat
sc01_len[0x0c] = 103;
sc01_map[0x0d] = "n"; // N suN
sc01_len[0x0d] = 80;
sc01_map[0x0e] = "b"; // B Bag
sc01_len[0x0e] = 71;
sc01_map[0x0f] = "v"; // V Van
sc01_len[0x0f] = 71;
sc01_map[0x10] = "ch"; // CH* CHip, T must precede CD to produce CH sound
sc01_len[0x10] = 71;
sc01_map[0x11] = "sh"; // SH SHop
sc01_len[0x11] = 121;
sc01_map[0x12] = "z"; // Z Zoo
sc01_len[0x12] = 71;
sc01_map[0x13] = "ao"; // AW1 lAWful
sc01_len[0x13] = 146;
sc01_map[0x14] = "nx"; // NG thiNG // ng ??
sc01_len[0x14] = 121;
sc01_map[0x15] = "aa"; // AH1 FAther
sc01_len[0x15] = 146;
sc01_map[0x16] = "uh"; // OO1 lOOking
sc01_len[0x16] = 103;
sc01_map[0x17] = "uh"; // OO bOOk
sc01_len[0x17] = 185;
sc01_map[0x18] = "ll"; // L Land
sc01_len[0x18] = 103;
sc01_map[0x19] = "k"; // K triCK
sc01_len[0x19] = 80;
sc01_map[0x1a] = "jh"; // J Judge, D must precede J to produce J sound
sc01_len[0x1a] = 47;
sc01_map[0x1b] = "hx"; // H Hello // hh ??
sc01_len[0x1b] = 71;
sc01_map[0x1c] = "g"; // G Get
sc01_len[0x1c] = 71;
sc01_map[0x1d] = "f"; // F Fast
sc01_len[0x1d] = 103;
sc01_map[0x1e] = "d"; // D paiD
sc01_len[0x1e] = 55;
sc01_map[0x1f] = "s"; // S paSS
sc01_len[0x1f] = 90;
sc01_map[0x20] = "ey"; // A dAY
sc01_len[0x20] = 185;
sc01_map[0x21] = "ey"; // AY dAY
sc01_len[0x21] = 65;
sc01_map[0x22] = "yx"; // Y1 Yard // y ?
sc01_len[0x22] = 80;
sc01_map[0x23] = "ah"; // UH3 missIOn
sc01_len[0x23] = 47;
sc01_map[0x24] = "aa"; // AH mOp
sc01_len[0x24] = 250;
sc01_map[0x25] = "p"; // P Past
sc01_len[0x25] = 103;
sc01_map[0x26] = "ow"; // O cOld
sc01_len[0x26] = 185;
sc01_map[0x27] = "ih"; // I pIn
sc01_len[0x27] = 185;
sc01_map[0x28] = "uw"; // U mOve
sc01_len[0x28] = 185;
sc01_map[0x29] = "iy"; // Y anY
sc01_len[0x29] = 103;
sc01_map[0x2a] = "t"; // T Tap
sc01_len[0x2a] = 71;
sc01_map[0x2b] = "r"; // R Red
sc01_len[0x2b] = 90;
sc01_map[0x2c] = "iy"; // E mEEt
sc01_len[0x2c] = 185;
sc01_map[0x2d] = "w"; // W Win
sc01_len[0x2d] = 80;
sc01_map[0x2e] = "ae"; // AE dAd
sc01_len[0x2e] = 185;
sc01_map[0x2f] = "ae"; // AE1 After
sc01_len[0x2f] = 103;
sc01_map[0x30] = "ao"; // AW2 sAlty
sc01_len[0x30] = 90;
sc01_map[0x31] = "ah"; // UH2 About
sc01_len[0x31] = 71;
sc01_map[0x32] = "ah"; // UH1 Uncle
sc01_len[0x32] = 103;
sc01_map[0x33] = "ah"; // UH3 cUp
sc01_len[0x33] = 185;
sc01_map[0x34] = "ao"; // O2 fOr
sc01_len[0x34] = 80;
sc01_map[0x35] = "ao"; // O1 abOArd
sc01_len[0x35] = 121;
sc01_map[0x36] = "yx"; // IU yOU
sc01_len[0x36] = 159;
sc01_map[0x37] = "uw"; // U1 yOU
sc01_len[0x37] = 90;
sc01_map[0x38] = "dh"; // THV THe
sc01_len[0x38] = 80;
sc01_map[0x39] = "th"; // TH THin
sc01_len[0x39] = 71;
sc01_map[0x3a] = "er"; // ER bIrd
sc01_len[0x3a] = 146;
sc01_map[0x3b] = "eh"; // EH gEt
sc01_len[0x3b] = 185;
sc01_map[0x3c] = "iy"; // E1 bE
sc01_len[0x3c] = 121;
sc01_map[0x3d] = "ao"; // AW cAll
sc01_len[0x3d] = 250;
//sc01_map[0x3e] = "_"; // PA1 = no sound
sc01_map[0x3e] = "_"; // PA1 = no sound
sc01_len[0x3e] = 185;
sc01_map[0x3f] = "_"; // STOP = no sound
sc01_len[0x3f] = 47;
// RS TRS80 Voice Synthesizer
// codes 00 to 31
trs_to_sc01_map['@'] = 0x06; // A1
trs_to_sc01_map['A'] = 0x08; // A2
trs_to_sc01_map['B'] = 0x0e; // B
trs_to_sc01_map['C'] = 0x10; // CH
trs_to_sc01_map['D'] = 0x1e; // D
trs_to_sc01_map['E'] = 0x3c; // E1
trs_to_sc01_map['F'] = 0x1d; // F
trs_to_sc01_map['G'] = 0x1c; // G
trs_to_sc01_map['H'] = 0x1b; // H
trs_to_sc01_map['I'] = 0x0b; // I1
trs_to_sc01_map['J'] = 0x1a; // J
trs_to_sc01_map['K'] = 0x19; // K
trs_to_sc01_map['L'] = 0x18; // L
trs_to_sc01_map['M'] = 0x0c; // M
trs_to_sc01_map['N'] = 0x0d; // N
trs_to_sc01_map['O'] = 0x35; // O1
trs_to_sc01_map['P'] = 0x25; // P
trs_to_sc01_map['Q'] = 0x38; // DH
trs_to_sc01_map['R'] = 0x2b; // R
trs_to_sc01_map['S'] = 0x1f; // S
trs_to_sc01_map['T'] = 0x2a; // T
trs_to_sc01_map['U'] = 0x37; // U1
trs_to_sc01_map['V'] = 0x0f; // V
trs_to_sc01_map['W'] = 0x2d; // W
trs_to_sc01_map['X'] = 0x07; // ZH
// trs_to_sc01_map['Y'] = 0x22; // Y1
trs_to_sc01_map['Y'] = 0x29; // Y - corrected by MW
trs_to_sc01_map['Z'] = 0x12; // Z
trs_to_sc01_map['['] = 0x34; // O2
trs_to_sc01_map['\\'] = 0x26; // O
trs_to_sc01_map[']'] = 0x31; // AH
trs_to_sc01_map['^'] = 0x20; // A
trs_to_sc01_map['_'] = 0x03; // NULL (PA0?)
// codes 32 to 62 (63 = "?" = OPEN/CLOSE WINDOW)
trs_to_sc01_map[' '] = 0x3e; // PA1
trs_to_sc01_map['!'] = 0x0a; // I2
trs_to_sc01_map['\"'] = 0x27; // I
trs_to_sc01_map['#'] = 0x09; // I3
trs_to_sc01_map['$'] = 0x17; // OO
trs_to_sc01_map['%'] = 0x16; // OO1
// trs_to_sc01_map['&'] = 0x29; // Y
trs_to_sc01_map['&'] = 0x22; // Y1 - corrected by MW
trs_to_sc01_map['\''] = 0x28; // U
trs_to_sc01_map['('] = 0x36; // IU
trs_to_sc01_map[')'] = 0x05; // A2
trs_to_sc01_map['*'] = 0x21; // AY
trs_to_sc01_map['+'] = 0x14; // NG
trs_to_sc01_map[','] = 0x3d; // AW
// ??? :
trs_to_sc01_map['-'] = 0x3f; // 0 DEC. ??? GUESSING STOP
trs_to_sc01_map['.'] = 0x2c; // E
trs_to_sc01_map['/'] = 0x3a; // ER
trs_to_sc01_map['0'] = 0x03; // PA0
trs_to_sc01_map['1'] = 0x13; // AW1
trs_to_sc01_map['2'] = 0x30; // AW2
trs_to_sc01_map['3'] = 0x02; // EH1
trs_to_sc01_map['4'] = 0x01; // EH2
trs_to_sc01_map['5'] = 0x00; // EH3
trs_to_sc01_map['6'] = 0x32; // UH1
trs_to_sc01_map['7'] = 0x31; // UH2
trs_to_sc01_map['8'] = 0x33; // UH3
trs_to_sc01_map['9'] = 0x2f; // AE1
trs_to_sc01_map[':'] = 0x2e; // AE
trs_to_sc01_map[';'] = 0x15; // AH1
trs_to_sc01_map['<'] = 0x38; // THV
trs_to_sc01_map['='] = 0x39; // TH
trs_to_sc01_map['>'] = 0x11; // SH
}
So, for the TRS Voice Synthesizer input ASCII character x, we do a
sc01_map[ trs_to_sc01_map[x] ]
to get the DECtalk "equivalent", and to the VS-100, we directly us
sc01_map[ x ]
Now, one problem with the approach is that DECtalk needs to buffer the phonemes first. It is very hard to utter phonemes in "real time" - the TRS Voice Synthesizer BASIC Demo Program has a part were it spells out the phonemes for different words. This is difficult to get right with this approach.
However, it should be easier to do this with a (much more) low-level speech chip like the SP0256-AL2. The given mappings can be a good starting point for a SP0-based TRS Voice Synthesizer. Maybe I'll add the SP0256-AL2 as a second speech chip in a second version of Talker/80, when I am going to support the Model 3 and Model 4 as well.
Making Hardware Extensions for the Model 1
The Model 1 expansion port is an interesting mess - unlike the CPC, where the signals are ordered neatly by group, the different signals are all over the place. Also, 5V are not obtainable from the connector, even though documented. I heard that it was a common hardware modification / "hack" performed by Radio Shack - when your Model 1 was upgraded for Level 2, they cut the 5V power supply trace from the connector! That must have to do something with the Expansion Interface. Anyhow. So, Talker/80 requires an external 5V power supply. No problem. But adds to the messiness of the system.

The TRS Voice Synthesizer uses an interesting approach to IO - it snoops writes to the Video RAM! When a "?" is detected in the (video) RAM address range $3FE0 .. $3FFF, it "opens" (and then, also "closes") the IO window to the synthesizer. Then, with the window being open, printable ASCII characters are mapped to SC-01 phonemes and uttered as long as the window is open. Also, the addresses don't matter, only the order of sequence in which phonemes are written. So this greatly simplifies the decoding process (any write in between the $3FE0 .. $3FFF range triggers the decoder and latches the byte).
Obviously, this (video) RAM snooping requires access to the WR ("RAM WRITE") signal on the expansion port. Even though some books (e.g., "Hardware Interfacing with the TRS-80" from Uffenbeck) claim that this signal is not being passed through by the Expansion Interface, this is actually incorrect - the RD and WR signals ARE available from the EI expansion port edge connector.
The VS-100 uses another IO method - the more standard, simple Z80 IOREQ Write / Read. The Model 1 has the IOREQ WR and IOREQ RD signals combined into "IN" and "OUT". And these are also passed through by the EI. So the VS-100 will work behind the EI as well. And that kind of IO is the same that is being used on the Amstrad CPC for LambdaSpeak, so easy to realize with my previous experience.
The Project
So, given that I have a whole box of GAL22V10B's pulled form old printers or something (I got 50 or so for 20 $ on Ebay at some point) sitting here waiting for a project, I decided to put them to work! One GAL for VS-100 and TRS Voice Synthesizer IO decoding (so, depending on the mode of Talker/80, it needs to snoop the RAM signals or do standard IO decoding), and another GAL22V10 to act as a databus latch and tri-state buffer that can also present some status byte to the TRS-80 via IOREQ READ ("RD" signal), because the VS-100 uses a status bit to indicate if it is still speaking, unlike the TRS Voice Synthesizer which doesn't give any status indication.
The rest was then mostly software / firmware programming work. I was able to reuse 80% or so of the old LambdaSpeak firmware - and I continue to use the Atmega 644-20PU (20 Mhz clock) and the "Text2Speech Click Board" from Mikroelektronika which hosts the Epson S1V30120 speech chip, running the DECtalk firmware.
I also added a simple op-amp for audio mixing of the TRS-80 Model 1 "cassette port sound" with the spech signal, and added a 5$ amplifier board to connect a speaker to it. This little audio amplifier is amazing for that price, and if I added a LM386 it would actually be more expensive and sound worse, so I just bought a whole bunch of these - highly recommended:
I also added an expansion port passthrough edge connector, because not everybody has the rare Expansion Interface, and Model 1 owners without are not losing the port if Talker/80 is connected directly to the Model 1. For example, the popular Quinterface can be connected to Talker/80's edge connector.
A PCB was made with KiCAD, and OSH Park produced the PCB prototypes in the usual perfect quality. After fixing some bugs and iterations, I now have PCB revision 3, and I am happy with it. I will probably produce a small batch for other enthusiasts. And also make the firmware open source, so others can build it themselves. However, GAL22V10 programming is not easy these days - the popular MiniPRO TL866 programmer doesn't do it. At least mine doesn't. I needed to get another programmer for the GAL22V10B's - the Genius G540 Programmer does the trick for me. Good luck!
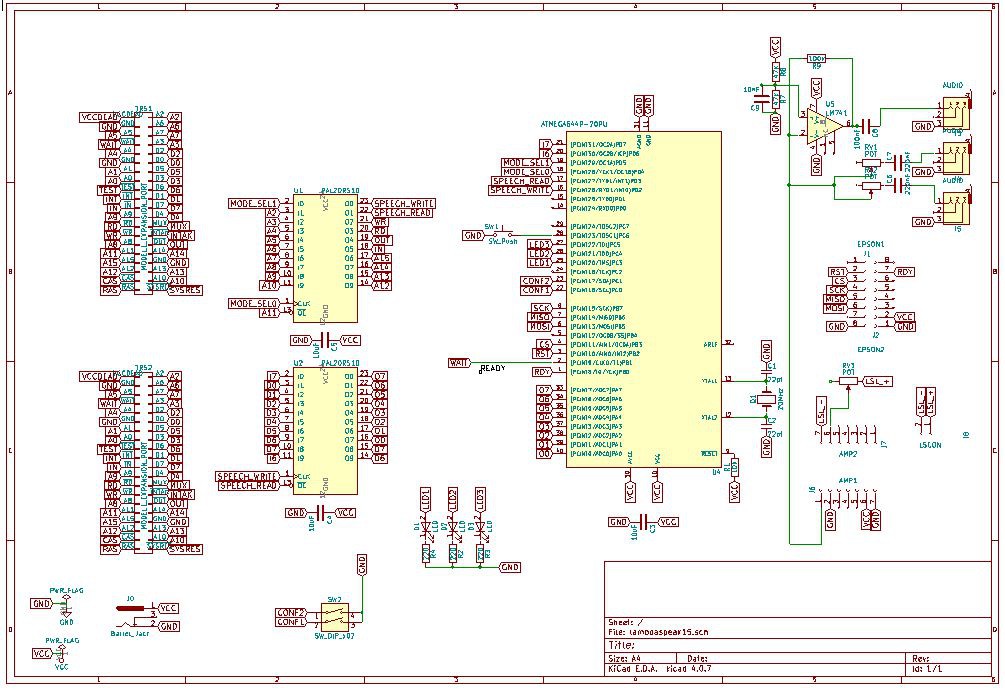
Schematics:
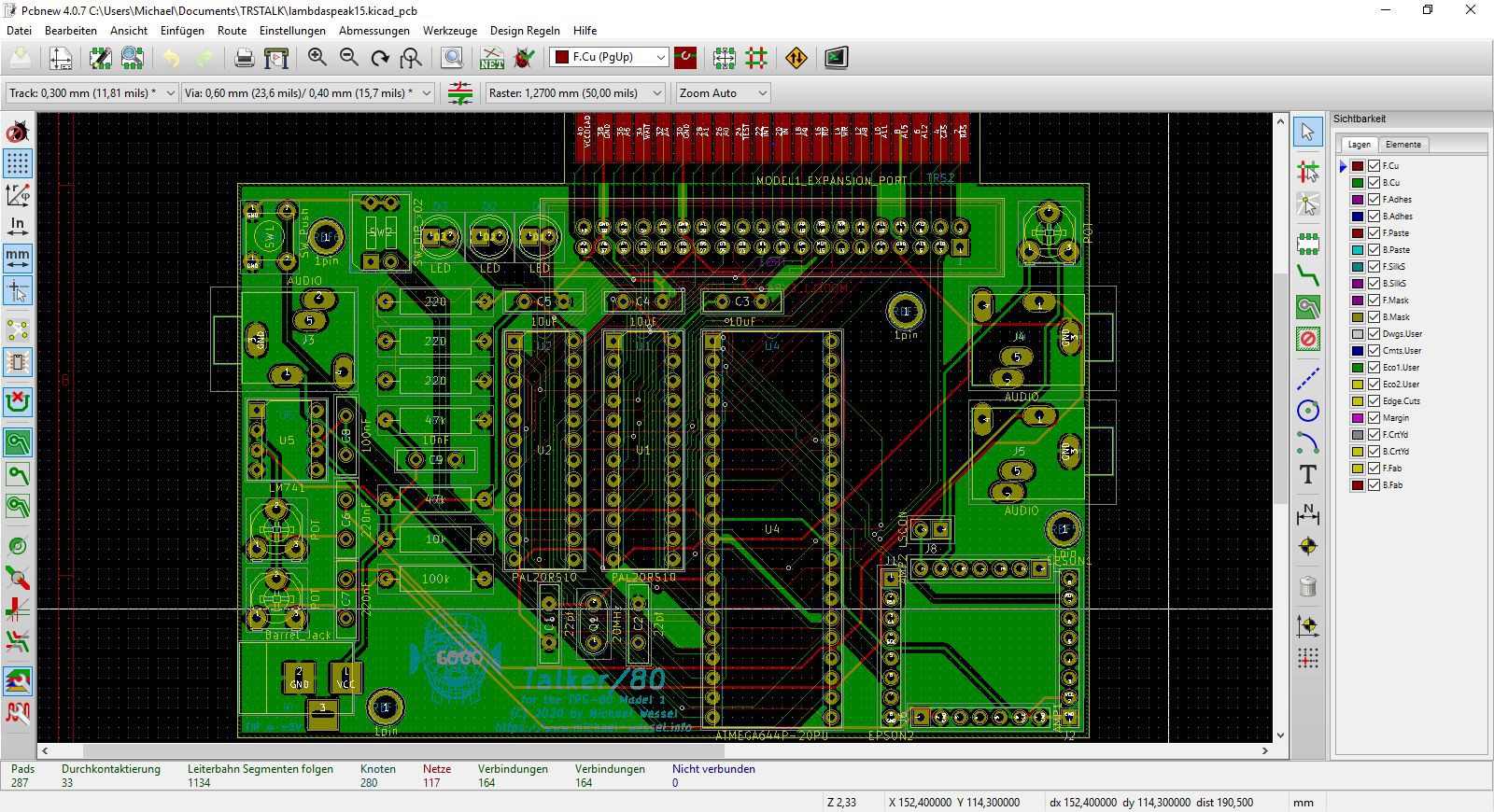
PCB:
 3D Model:
3D Model: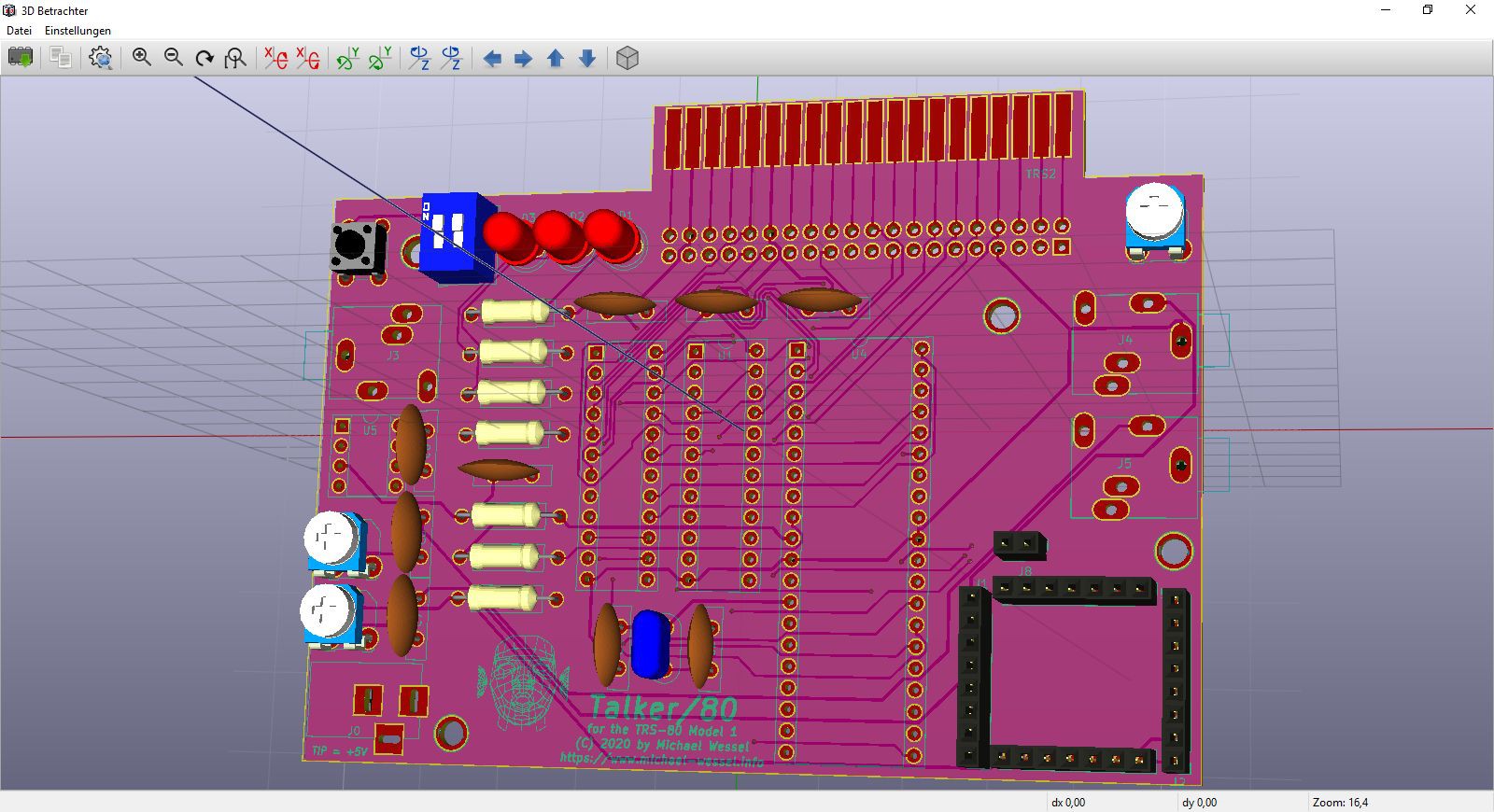
Outlook
So, what's left to do? Some more tweaks to the firmware, and then I am going to make a few available to other TRS-80 Model 1 enthusiasts. At some point, I will also make a version for the Model 3 / Model 4. I have a prestine and fully upgraded Model 4 non-GA sitting here which is dying to get a voice as well!
Some videos - it all started with a breadboard:
The first PCB arrived - that required some fixes (i.e., I got the audio jack pinout wrong, and added the power amplifier by hand):
Final PCB version with audio amplifier soldered in properly rather than "hot glued and hand wired on top"; optimized PCB layout for controls, and first demo of TRS Voice Synthesizer emulation. Still has some imperfections and glitches:
Firmware update - now with VS-100 Emulation Mode, and improved TRS Voice Synthesizer Emulation. Also demonstrates some other DECtalk features, such as: signing, different voices, different speak rates, etc.
"Talking Eliza" with Talker/80:
And here the final demo video - these are the BASIC demo programs that are on the Talker/80 JV3 disk image. Demonstrates Spanish Speaking, DECtalk singing, and the Jeff Shrager version of Eliza from "Creative Computing", which I augmented with Talker/80 speech - not that this sounds a bit better than the "TRS Talking Eliza" shown above, mostly because it is using DECtalk and not the TRS Voice Synthesizer (Emulation):
Here are pictures of a first little batch that I have made:

