 Yann Guidon / YGDES
Yann Guidon / YGDESThis project documents the design and implementation of a string format that is flexible and
- efficient in code space
- efficient in data space
- efficient in code execution
This is in part due to
- its flexible implementation that instantiates the required features only
- a definition that is adapted to static and dynamic processing
- compatibility with POSIX's ASCIIZ format (that can be disabled)
- code and data that can be accessed at any level of abstraction.
Unicode is supported as UTF-8 byte sequences in types 3/F3 lists, and as integer code points in type UP.
This makes it suitable from basic, barebone utilities to more elaborate applications.
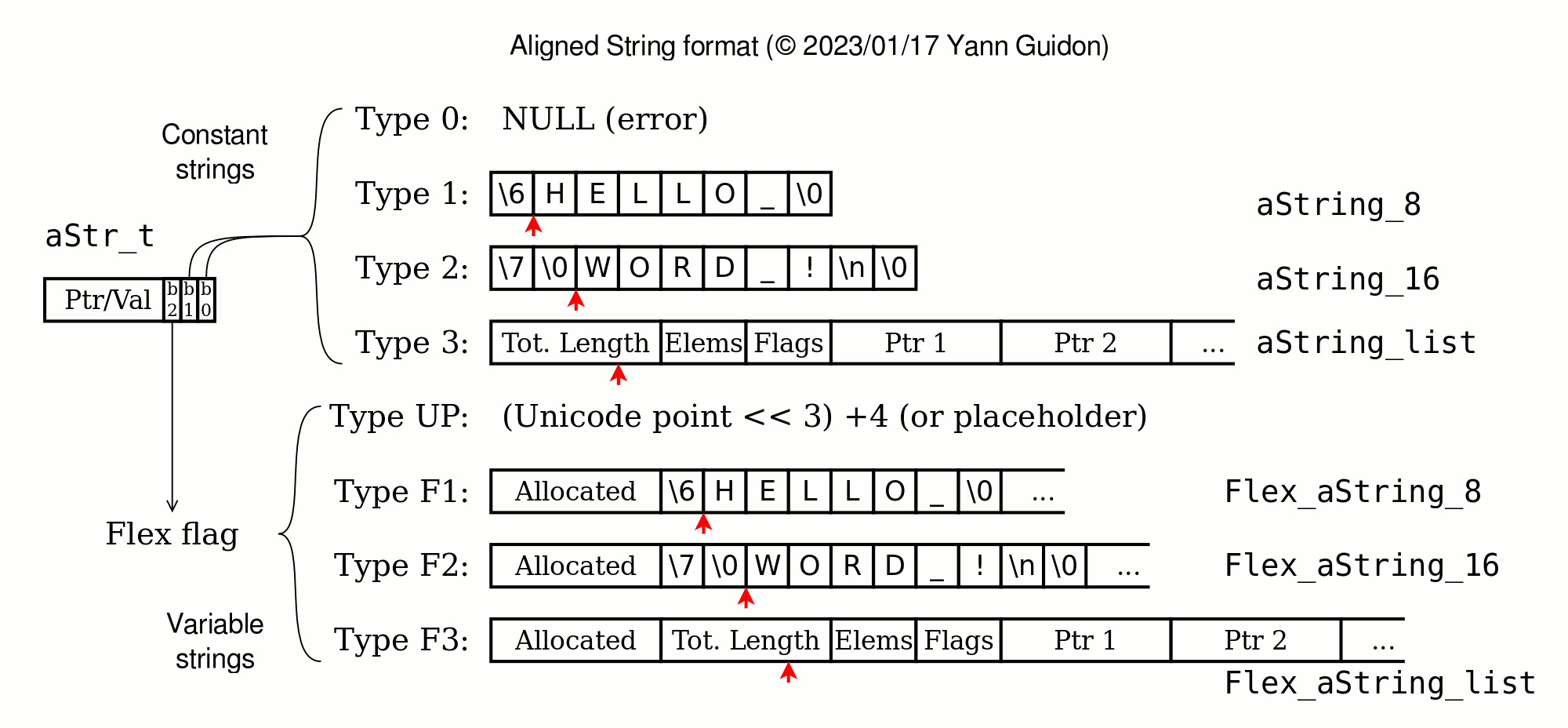
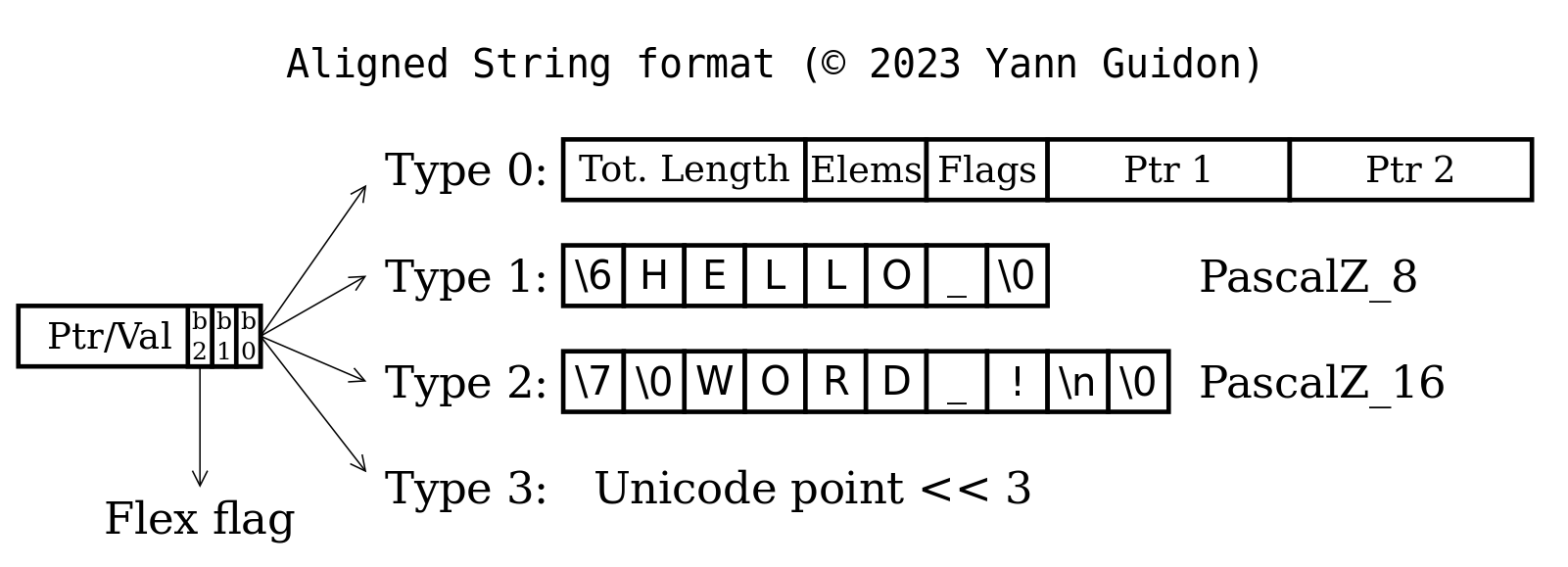
To define constant strings, the basic structure is defined as:
typedef struct {
uint8_t len __attribute__ ((aligned (4)));
char text[];
} aString_8;
A variant (with bit 0 of the pointer set) adds another field to keep the allocated size, helping to perform variable-sized operations:
// Same as above but with an extra 32-bit size field:
typedef struct {
uint32_t allocated __attribute__ ((aligned (8)));
uint8_t len;
char text[];
} Flex_aString_8;
The same goes for the 16-bit version (types 2 and F2) and the lists (types 3 and F3 ).
-o-O-0-O-o-
Logs:
1. Dealing with re-alignment and 2 string types only
2. Context
3. 2023 : a new version
4. Evolution...
5. Merge works
6. Holding back a bit
7. More food for thoughts
8. Article !
9. Another possible extension
10. More than an error
11. Fuzzing and safety
.







 agp.cooper
agp.cooper
 Ken Yap
Ken Yap
 Keith
Keith
 Andrey Kalmatskiy
Andrey Kalmatskiy
https://hackaday.com/2023/02/10/modernizing-c-arrays-for-greater-memory-safety/
https://developers.redhat.com/articles/2022/09/29/benefits-limitations-flexible-array-members#nonconforming_compiler_extensions
https://people.kernel.org/kees/bounded-flexible-arrays-in-c