atltvhead
atltvhead-
OBS Gesture Control
09/01/2020 at 17:48 • 0 commentsThis is more of an add-on type of feature. For live streaming, I use OBS with the websockets plugin and lorianboard as a scene controller. Lorianboard is pretty awesome including features that allow you to trigger multiple sounds, scenes, and sub-menu controls. At its most complicated, it can even create a simple state machine control over obs based on twitch chat, channel points, and other non twitch related triggers.
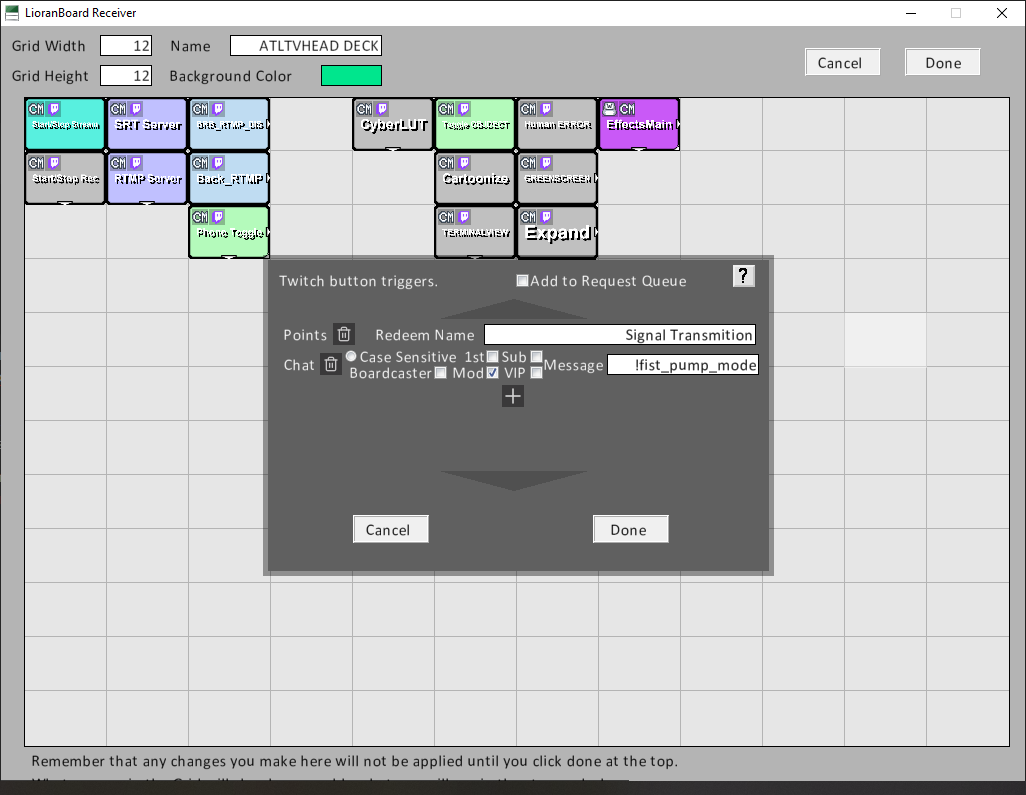
Since my gestures already trigger a chat message: !wave_mode !random_motion_mode !speed_mode !fist_pump_mode. It is rather easy to trigger a button in lorianboard. While editing a deck, choose a button and select Edit Twitch Triggers.
![]() Click the plus and add chat command, type in the command and the role associated. You are done. With triggering the effect.
Click the plus and add chat command, type in the command and the role associated. You are done. With triggering the effect. ![]()
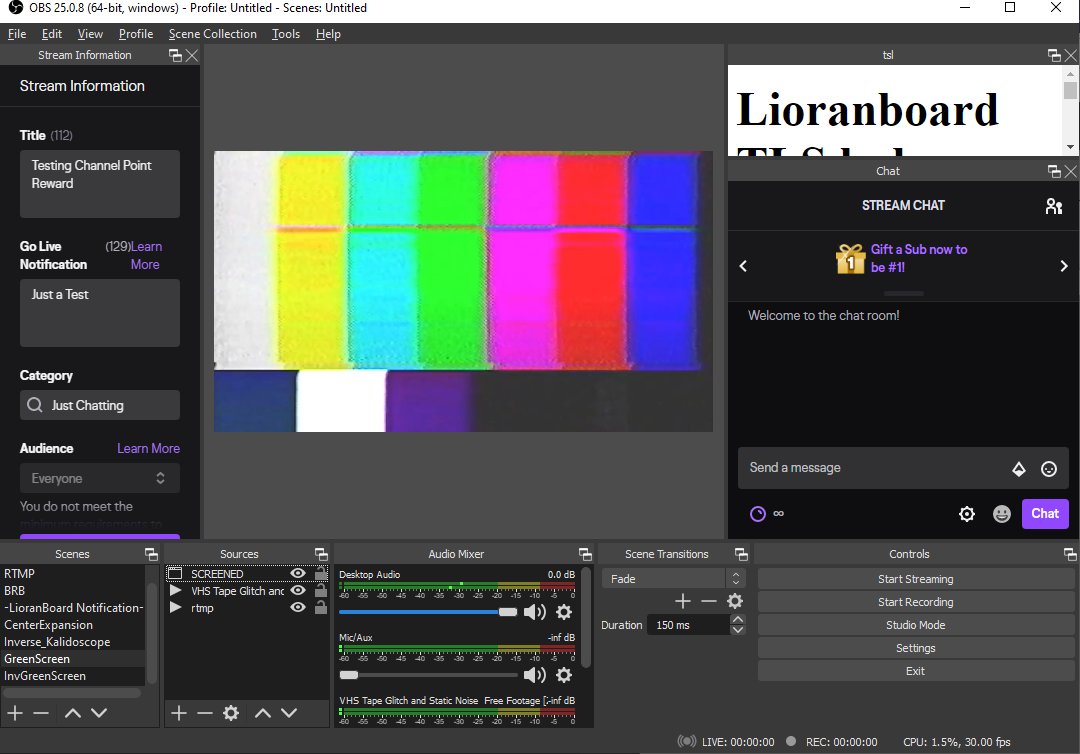
Coding the effect itself is a little more complicated.In OBS, create a scene for you to change to. Add in whatever sources you'd like.
![]()
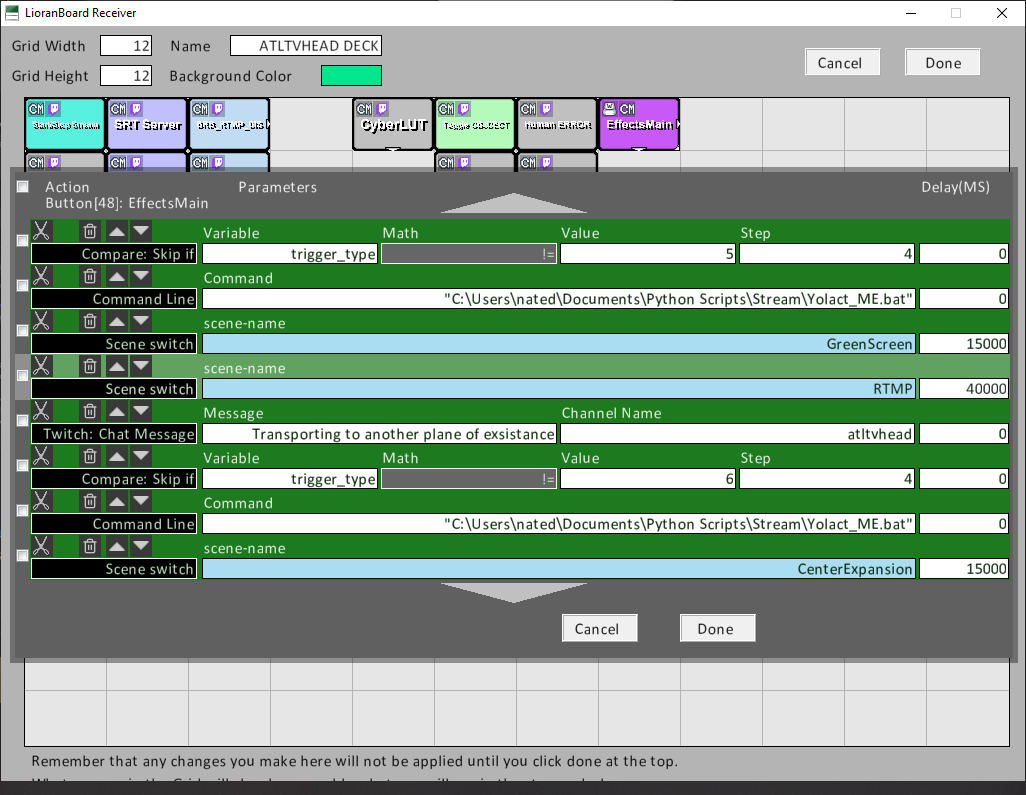
For me, I recreated a green screen effect using machine learning and the yolact algorithm. So I included the source window generated from python and yolact. I also rewrote part of yolact to display only the objects detected or the inverse. I also provided a glitchy vhs background. Back In Lorianboard I created a button with a "stack" or queue for effects. It looks like the following. An if statement with variable to the corresponding effect, a bash script executed by lorianboard, and scene changing commands based on timers.
![]()
The bash script runs my yolact python file with line arguments.
python eval.py --trained_model=weights/yolact_resnet50_54_800000.pth --score_threshold=0.15 --top_k=15 --video_multiframe=20 --greenscreen=True --video="rtmp://192.168.1.202/live/test"Notice my video is actually an rtmp video stream. I have an nginx-rtmp video server running in a docker container, which my phone broadcasts to using Larix broadcaster.
But Anyways the EFFECTS! Let's check out what I have created so far.
![]()
Pretty good for AI.
Inspired by Squarepusher's Terminal Slam video and some others work to recreate it. I tried my own varient.
-
Smaller Time Window
08/11/2020 at 19:09 • 0 commentsI shrank the time window in which a gesture can be preformed from 3 to about 1.4-1.5 seconds. It is working well and feels much more fluid than the original. There is still a little room for optimization on gesture timing, but I am happy with its current state.
This time when comparing models, the 2nd and 3rd cnn were better trained than the first. However, the larger, 2nd model preformed better than smaller 3rd one. I proceeded with using cnn_model2_half.h5
Some improvements need to be made when using pandas however. Since the dataframes memory is not released each gesture sampling will consume more and more memory. Once solution is to use the multi processing library to run the gesture sampling as in a separate process. When a processes completes it returns its memory to the operating system. This should allow for true continuous gesture reads without filling up the memory on the raspberry pi.Still working towards deployment on the esp32, but just making sure there is plenty of room for other bits of code and processing.
The files have been update are reflected in the GitHub. -
New Control Scheme
07/24/2020 at 19:58 • 0 commentsUsing both Gesture modes, and channel commands the following animations are broken up in equation style.
Gesture A + command "1" = Animation A![]()
Gesture Recognition Wearable
Using Machine Learning to simplify Twitch Chat interface for my tvhead and OBS Scene Control
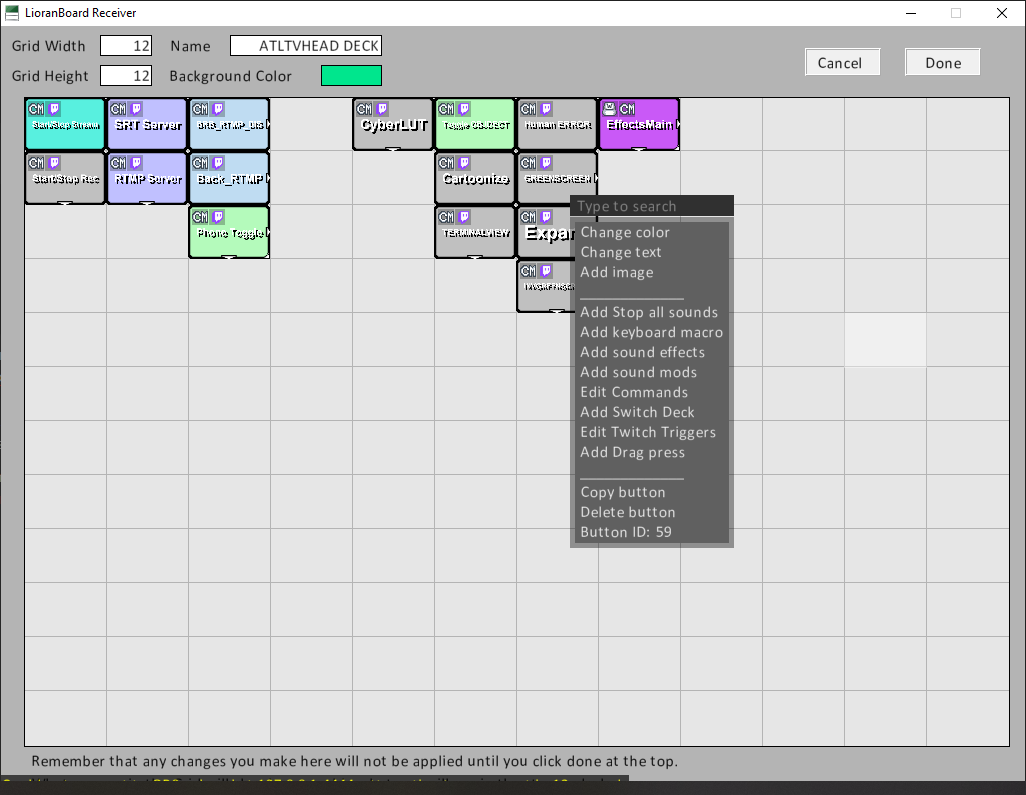 Click the plus and add chat command, type in the command and the role associated. You are done. With triggering the effect.
Click the plus and add chat command, type in the command and the role associated. You are done. With triggering the effect.