 Gonçalo Nespral
Gonçalo NespralNeural Networks, Briefly
For those who don't know, neural networks are a machine learning model with a structure loosely based on the human brain, whose aim is to approximate a function which maps a set of inputs, to a set of outputs. They can be used to solve all kinds of problems, without being explicitly programmed with rules to follow. In a simple feed-forward neural network, data is fed into the network. This data then passes through multiple layers, where it is multiplied by many weights. Once it reaches the final layer, a result is produced. To help visualize this, it is often easier to look at an example:
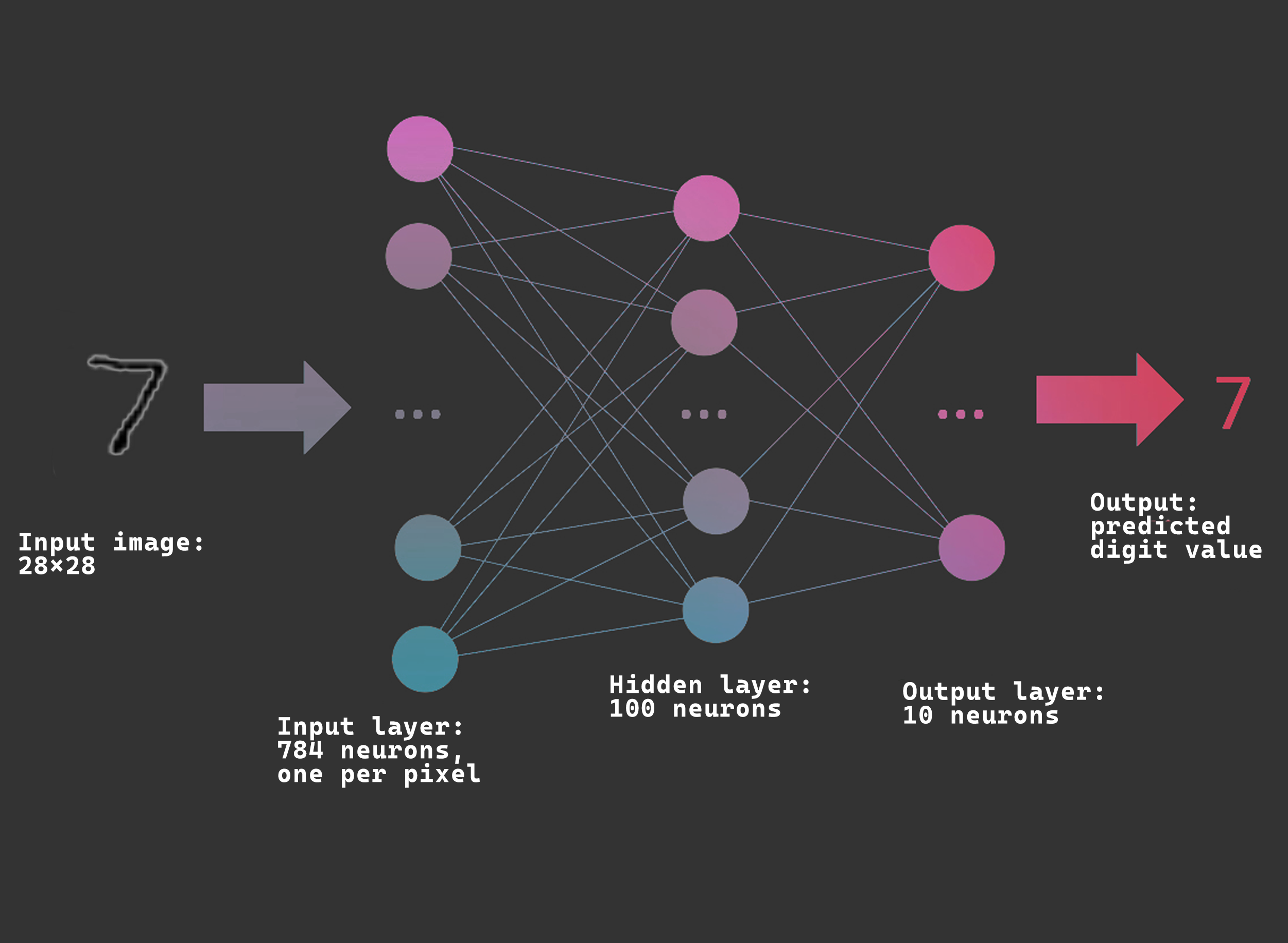
An easy way to think about how the output is produced to imagine the image of a seven being converted into a 28x28 matrix. Every element in the matrix corresponds to a pixel in the original image, and its value depends on the brightness of the pixel (a 0 would be a completely black pixel, 255 would be a white pixel). Once this matrix is created, it is fed into the input layer, where it is multiplied by a matrix of weights which alter the data (a set of weights for each node). This happens with every layer in the network until we reach the final layer. The output is a value which tells us that the input was a seven.
However, we cant just create a neural network and expect it to work immediately: it has to be trained first. This is typically done using massive labelled datasets. For the example above, a good dataset to use would be MNIST, which contains thousands of images of handwritten digits.
First, we generate our network. The weights for each layer are initialized randomly, meaning that the output of the network will most likely be incorrect at first. Then, an image is fed into the input layer, and once a forward pass is completed an output is produced. This is evaluated, and an error value is calculated (this tells us how far off our output was from the correct value). The error value is then used in a process called backpropagation to carefully adjust the weights in the network. This corrects the output of the network for future predictions. As this happens repeatedly, the network becomes better at recognizing handwritten digits, and the error value decreases. The process of training machine learning models (optimization) is very resource expensive and can take many hours, if not days, even on powerful hardware.
The math behind backpropagation gets very complex, and can easily overwhelm someone just getting into machine learning (like me). But we don't always have to go through the complexity of backpropagation to train our models. If we look at nature, we can see that natural selection has worked wonders for many organisms, and we can apply the basic concept behind this process into our machine learning algorithms. This is called neuroevolution, and offers many advantages over using backpropagation, most importantly its robustness, and how efficiently models can be trained.
Neuroevolution
In neuroevolution, instead of optimizing by looking at a single neural network, we create a population of networks, each with different weights. We allow the networks to make predictions and we evaluate the fitness of each network (how good they are at predicting). We can then take the weights from the best performing networks, and create a new generation of networks based on the parent weights. This is similar to natural selection since we are allowing the "genes" of the fittest networks to become more prevalent in future generations.
My Project
My main goal for this project is to simulate natural selection, by creating a digital environment for sprites (organisms) to interact with. The whole project is written in python, and the machine learning is mostly done with the help of tensorflow and numpy.
BUILDING THE ENVIRONMENT
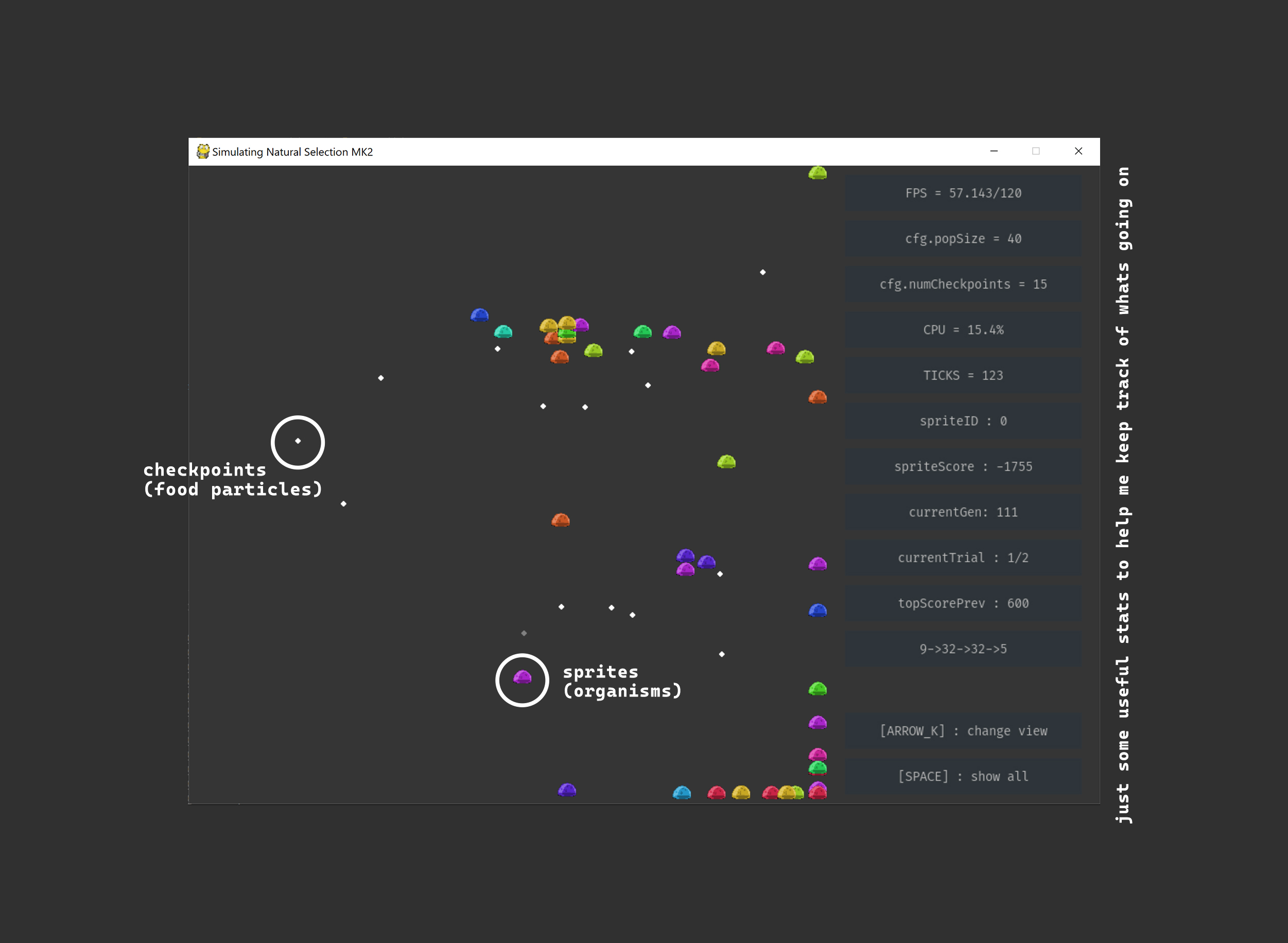
To create the environment and its physics, I used pygame. Sprites are allowed to move around the environment, and can collect checkpoints (food particles). The...

 Foxmjay
Foxmjay
 Nick Bild
Nick Bild
 Nyeli Kratz
Nyeli Kratz
 Sumit
Sumit