 rossumur
rossumur
See it in action on YouTube. Source code at https://github.com/rossumur/SAM2600
A Brief History of Speech Synthesis
While mechanical speech synthesis dates back to the 18th century, the first successful attempt based on electronics was ‘An Electrical Analogue of the Vocal Organs’ by John Q. Stewart in 1922. It was capable of saying such interesting things as mama, anna, wow-wow, and yi-yi.
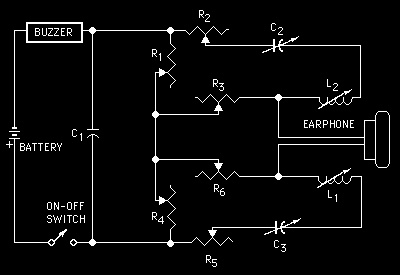
His circuit consisted of a buzzer to simulate the vocal cords and a pair of oscillators to simulate the resonance of the mouth and throat. By varying the capacitance, resistance and inductance of the circuit he could produce a series of vowel-like sounds; probably the very first example of circuit bending. I would love to see someone recreate this and learn how to play it.
These resonance frequencies are known as formants. The human vocal tract has lots of potential for complicated resonances in the mouth, throat, nasal cavities etc. The mouth formant (f1) and throat format (f2) are critical to creating sounds that are recognizable as speech. The ratio on f1 to f2 define the sound of various vowels.
The overall pitch or fundamental frequency of speech comes from oscillations of the vocal cords: the buzzer in this model. Expressive speech depends a lot on correct modulation of pitch. This fundamental frequency is typically known as f0.
The Vocoder
The first device capable of general speech was introduced to the world in 1939. The Bell Telephone Laboratory’s Voder imitated the human vocal tract and when played by a trained operator could produce recognizable, albeit creepy, speech.

The Voder made its first public appearance in 1939 at the New York World’s Fair.
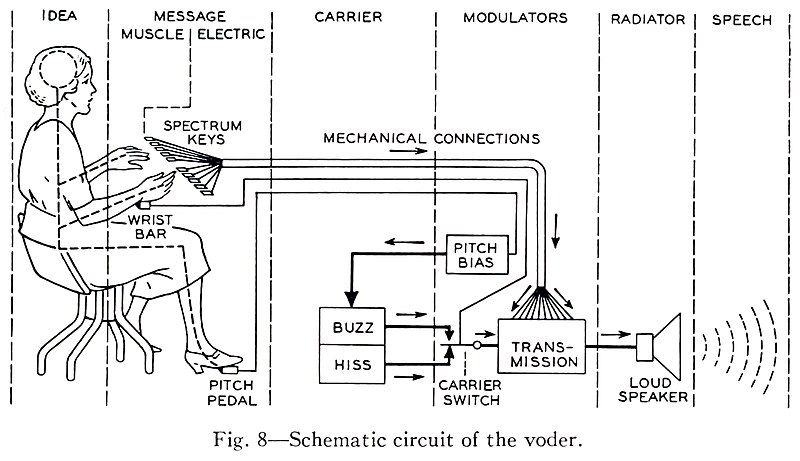
The Voder performed speech synthesis by emulating some of the behavior of the human vocal tract. It selectively fed two basic sounds, a buzz and a hiss, though a series of 10 bandpass filters. By selecting the buzzing source the machine could produce voiced vowels and nasal sounds, voiceless and fricative sounds were produced by filtering the hissing noise.
If a keyboard and pedals could be used to produce speech then so could a low bitrate digital signal. Homer Dudley, Voders creator, with the help of Alan Turing went on to contribute to SIGSALY, a compressed and encrypted speech system that successfully secured communications between the likes of Churchill and Roosevelt during the war.
Daisy
In 1961, physicist John Larry Kelly, Jr used an IBM 704 computer sing the song “Daisy”. This demo inspired one of the greatest moments in all of cinema when Arthur C. Clarke, who was visiting the lab at the time, decided that a certain HAL 9000 would serenade Dave Bowman whilst being lobotomized.

“My instructor was Mr. Langley, and he taught me to sing a song. If you’d like to hear it I can sing it for you.”
Talking Chips
By the 70s companies like Votrax were producing discrete logic speech synthesizers and text-to-speech algorithms. The United States Naval Research Laboratory, or “NRL” text-to-phoneme algorithm was developed by a collaboration between Votrax and the NRL in 1973. “Automatic Translation of English Text to Phonetics by Means of Letter-to-Sound Rules” allowed translation from arbitrary text to phonemes, the smallest units of sound in a word that makes a difference in its pronunciation and meaning. Phonetic alphabets such as ARPABET are used as a common representation of speech to program these devices.
By the end of the 70s and early 80s a variety of integrated circuit speech synthesizers have emerged. The Texas Instruments’ LPC speech chip family bring the Speak and Spell to life but early versions could only play back a fixed set of words.
The Votrax SC-01, famous for its use in the arcade games like Gorf, Wizard of Wor, Q-bert (where Q-bert would swear with random phonemes) was one of the first affordable simple formant synthesizers that could produce arbitrary speech; phoneme input was rendered into...
Read more »

 Dan Julio
Dan Julio
 Victor Serrano
Victor Serrano
 glgorman
glgorman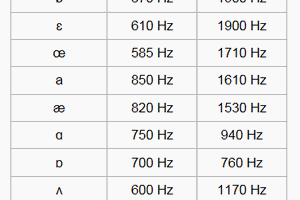
 Greg Kennedy
Greg Kennedy
It seems to me that if you want, you could make a cartridge full of SRAM instead of ROM and then feed it both the program and a bank where the precalculated sounds are stored as well as a routine for the 2600 to detect when there's new data and fetch it for playing.