 Yann Guidon / YGDES
Yann Guidon / YGDESI know, I know, I should update my SW but if a 2017 build of GHDL misbehaves in significant ways, I wonder why it had waited so long to be apparent.
So I'm adding a new "loading" test to the self-check suite, because I want to know how many gates I can reasonably handle, and I get weird results. It seems that GHDL's memory allocation is exponential and this should not be so. So I sent a message to Tristan, who sounds curious, asks for a repro, and here I start to rewrite the test as a self-contained file for easy reproduction.
The test is simple : to exercise my simulator, I create an array of fixed std_logic_vector's, with a size defined by a generic. Then, I connect elements of one line to other elements of the next line. Finally I connect the first and last lines to an input and output port, so the circuit can be controlled and observed by external code.
The result will surprise you.
So let's define the test code.
-- ghdl_expo.vhdl
-- created lun. nov. 9 00:56:57 CET 2020 by Yann Guidon whygee@f-cpu.org
-- repro of "exponential memory allocation" bug
Library ieee;
use ieee.std_logic_1164.all;
entity xor2 is
port (A, B : in std_logic;
Y : out std_logic);
end xor2;
architecture simple of xor2 is
begin
Y <= A xor B;
end simple;
--------------------------------
Library ieee;
use ieee.std_logic_1164.all;
Library work;
use work.all;
entity ghdl_expo is
generic (
test_nr : integer := 0;
layers : positive := 10
);
port(
A : in std_logic_vector(31 downto 0) ;
Y : out std_logic_vector(31 downto 0));
end ghdl_expo;
architecture unrolled of ghdl_expo is
subtype SLV32 is std_logic_vector(31 downto 0);
type ArSLV32 is array (0 to layers) of SLV32;
signal AR32 : ArSLV32;
begin
AR32(0) <= A;
t1: if test_nr > 0 generate
l1: for l in 1 to layers generate
AR32(l)(0) <= AR32(l-1)(31);
t2: if test_nr > 1 generate
l2: for k in 0 to 30 generate
t3: if test_nr = 3 generate
x: entity xor2 port map(
A => AR32(l-1)(k), B=>AR32(l-1)(31),
Y => AR32(l)(k+1));
end generate;
t4: if test_nr = 4 generate
AR32(l)(k+1) <= AR32(l-1)(k) xor AR32(l-1)(31);
end generate;
t5: if test_nr = 5 generate
AR32(l)(k+1) <= AR32(l-1)(k);
end generate;
end generate;
end generate;
end generate;
end generate;
Y <= AR32(layers);
end unrolled;
There are 2 generics :
- test_nr selects the code path to test.
- layers selects the number of elements of the array.
And now let's run it :
rm -f *.o *.cf ghdl_expo log*.txt
ghdl -a ghdl_expo.vhdl &&
ghdl -e ghdl_expo &&
# first test, doing nothing but allocation.
( for i in $(seq 2 2 100 )
do
echo -n $[i]000
( /usr/bin/time ./ghdl_expo -glayers=$[i]000 ) 2>&1 |
grep elapsed |sed 's/max.*//'|
sed 's/.*0[:]/ /'| sed 's/elapsed.*avgdata//'
done ) | tee log1.txt
The result (time and size) are logged into log1.txt, which gnuplot will happily display :
set xlabel 'size (K vectors)' set ylabel 'seconds' set yr [0:1.5] set y2label 'kBytes' set y2r [0:800000] plot "log1.txt" using 1:2 title "time (s)" w lines, "log1.txt" using 1:3 axes x1y2 title "allocated memory (kB)" w lines
And the result is quite as expected : linear.
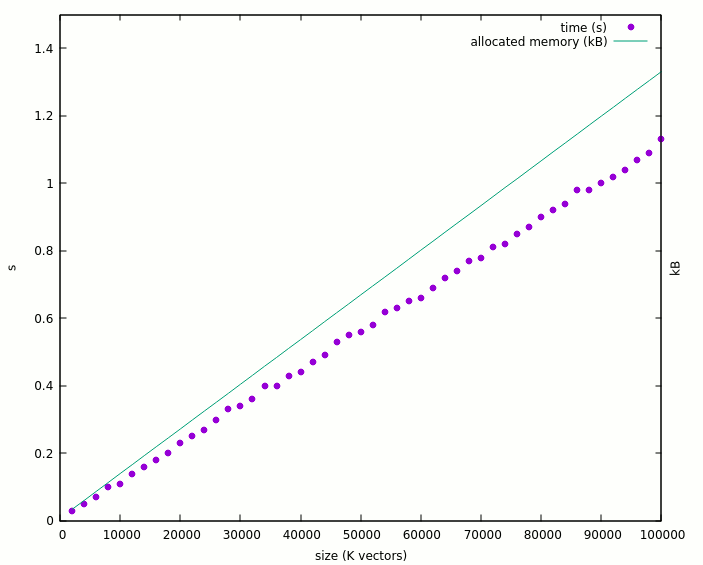
The curve starts at a bit less than 4MB for the naked program, which allocated 10 lines of 32 std_logic. Nothing to say here.
I would object that I expected better than 1.13 seconds to allocate 100K lines, which should occupy 3.2MB for themselves (so less than 8MB total). Instead the program eats 710MB ! This means a puzzling expansion factor > 200 ! Anyway, I'm grateful it works so far.
Now, I activate the test 1:
( for i in $(seq 2 2 100 )
do
echo -n $[i]00
( /usr/bin/time ./ghdl_expo -gtest_nr=1 -glayers=$[i]00 ) 2>&1 |
grep elapsed |sed 's/max.*//'| sed 's/.*0[:]/ /' |
sed 's/elapsed.*avgdata//'
done ) | tee log2.txt
The result looks different :
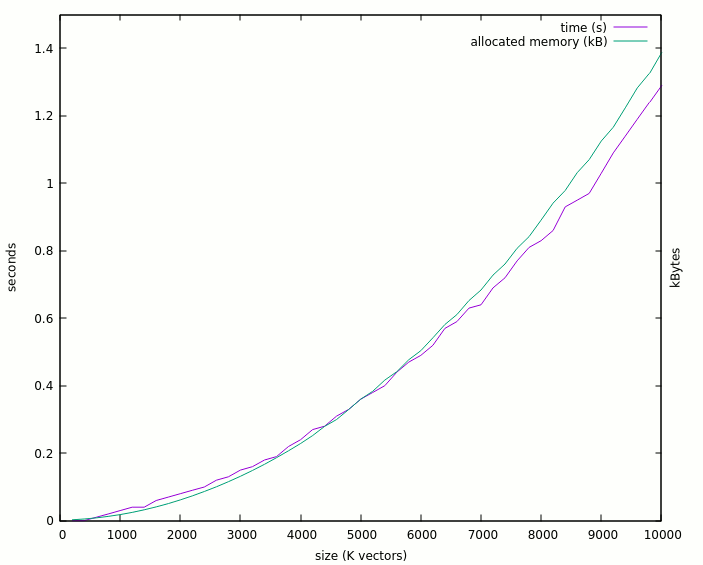
Notice that I have reduced the number of elements by 10 and the max. run time is similar. Worse : the 10K vectors now use 3.2GB ! The expansion ratio has gone to 100K ! Why would a single std_logic waste 100K bytes ?
Remember that all it does is scan the array and connects one bit from one line to another bit from another line:
AR32(l)(0) <= AR32(l-1)(31);
This might be the core of the issue...
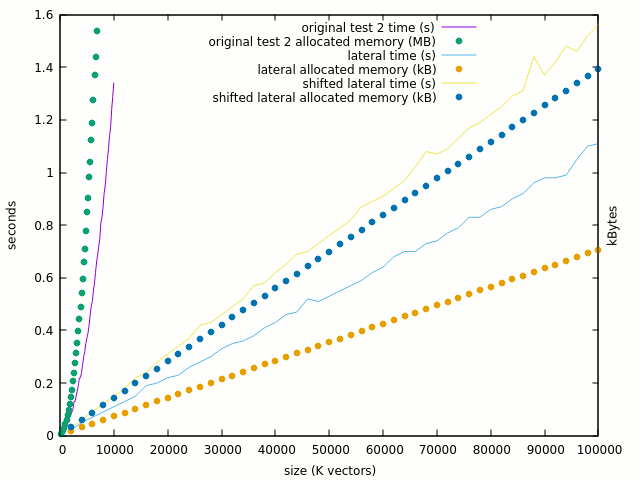
Test 2 adds another inner generate loop with nothing inside. The result is almost identical (<1%).
Test 3 adds one entity for each std_logic of the array, and the result is nice : there is only a linear and reasonable increase in time and space. There is a larger increase of runtime than space (due to initialisation ?) but it looks legit.
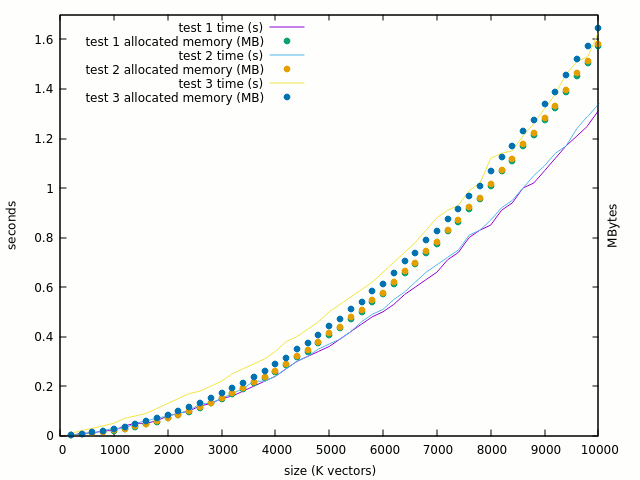
If mapping tons of entities is good, then why the exponential curve ?
Here are the comparative plots of test3 with and without the single bit assignation :

The curve is clearly linearised when the "<=" is removed and 100K gates looks reasonable. But where do the problems arise ? It should not be in the XOR computation itself, so let's try test #4 which computes the XOR in place. The thing gets totally mad :
- 100: 0.01s, 16MB
- 1000: 0.43s, 1GB
- 3000: 3.44s, 9GB !
Going from 100 to 3K is a factor of 30 but the memory & runtime ratio is >560 ! Given my computer's "reasonable" 16GB space, it's a very concerning problem. The curve is crazy :
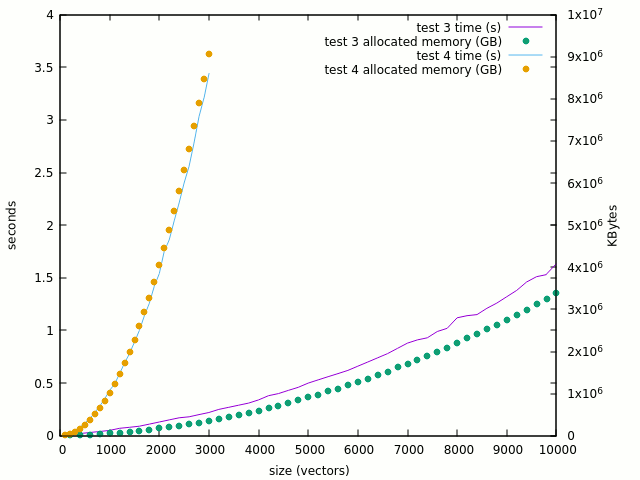
The number of single-bit assignations has been multiplied by 32 and the reads of single bits multiplied by 64. So this looks like the culprit.
The last test (5) tries to see what happens when XOR is removed but assignation is kept. The result is very very close to the previous test:
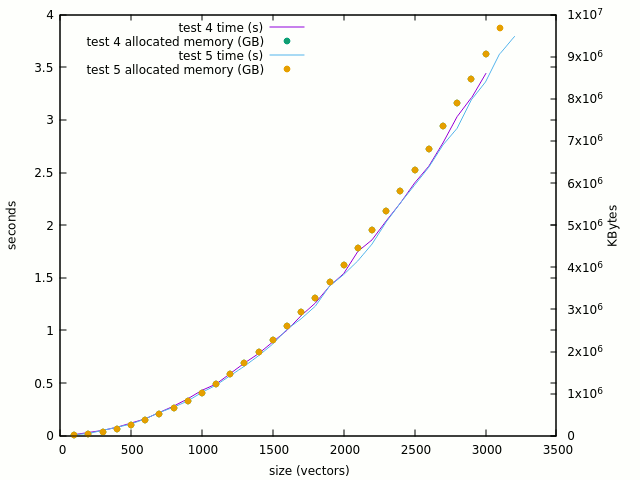
This hints at the problem's cause : writing to a given bit of a 2D array has a high cost, but I don't see why.
The first lesson is that arrays may not be the right place to put temporary data, but they are necessary when using for...generate loops because it's impossible to create signals dynamically with VHDL. So my test must use another approach...
FOR-GENERATE allows the creation of local signals but they are not visible to other iterations so I'm screwed. Arrays looked like the natural, logical solution but it stabs me in the back.
Update :
Tristan examined the situation. He noticed an avalanche of malloc() of small values and there are potential easy fixes for this.
Meanwhile, I must change my approach to work around this. One easy solution would be to "lateralise" the system, working in variable columns and not in small fixed rows. Mapping entities does not hit the pathological case so it should be fine.
__________________________________________________________________________
Here is the new code :
architecture lateral of ghdl_expo is
subtype SLV is std_logic_vector(layers downto 0);
type ArSLV32 is array (31 downto 0) of SLV;
signal AR32 : ArSLV32;
begin
-- connect the inputs and outputs :
l0: for o in 31 downto 0 generate
AR32(o)(0) <= A(o);
Y(o) <= AR32(o)(layers);
end generate;
...
And apparently, there is no significant difference between the initial and the lateral versions:
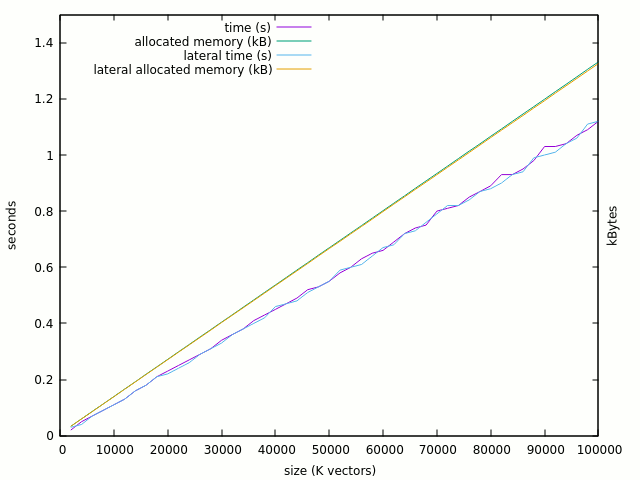
And there is still the same 706MB allocation, with >220 expansion ratio. Is there one malloc per single element ?
Enabling the test #1:
t1: if test_nr > 0 generate
l1: for l in 1 to layers generate
AR32(l)(layers downto 1) <= AR32(l)(layers-1 downto 0);
end generate;
end generate;
This is functionally identical to the first version but here I assign vectors to vectors, and not elements to elements.
The behaviour is still linear : RAM doubled (fair enough) and time increased by 30%. Notice that we didn't even simulate anything yet, it might count the initialisation time after elaboration.
100K vectors (3.2M std_logic) now use 1.4GB but it's 20x better than the first version. I can extrapolate that I can simulate up to 32M elements with 16GB of RAM:
1000 00.02 18540 10000 00.15 143832 100000 01.48 1394652 1000000 14.25 13903172
Anything more and the HDD swaps. The ratio is "only" 437 though but 30M gates is serious enough.
____________________________________________________________
Now let's apply the lessons learned and implement a "big mess of gates":
t2: if test_nr = 2 generate
l2: for l in 1 to layers generate
-- wrap around
w: entity xor2 port map(
A => AR32(l-1)(0), B=>AR32(l-1)(31),
Y => AR32(l)(31));
l22: for o in 31 downto 0 generate
x: entity xor2 port map(
A => AR32(l-1)(o), B=>AR32(l-1)(o-1),
Y => AR32(l)(o-1));
end generate;
end generate;
end generate;
As hinted before, entities use less memory :
1000 00.06 11688 10000 00.08 75328 100000 00.71 711704 1000000 06.83 7074936 2000000 13.51 14145228
The behaviour is linear too, and with 14GB I can describe 2M*32=64M gates ! We can also estimate the speed at 4M gates/second.
Notes:
- No actual simulation is taking place, it's only the elaboration + time=0 cost.
- No extra lib is used, there is nothing else at all, and this does not estimate the impact of the LibreGates library, I was only searching for a baseline and a rough idea of GHDL's behaviour to estimate the impact of my added code.
I hope this log could help others in the same situation :-)
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.