 Yann Guidon / YGDES
Yann Guidon / YGDESAfter I solved the weird issues of logChasing a "unexpected feature" in GHDL, it's time to put the lessons to practice and implement that huge fat ugly LFSR. It's not meant to be useful, beyond the unrolling of many, many LFSR stages and see how your computer and my code behave. So I created test6_bigLFSR/ in the project.
The LFSR's poly is finally chosen, thanks to https://users.ece.cmu.edu/~koopman/lfsr/index.html which contains a huge collection of primitives. For 32 bits, I downloaded 32.dat.gz (186MB) which expands to 600MB. It's huge but practical because you can grep all you want inside it :-) The densest poly is 0xFFFFFFFA, which is also the last. It contains 29 continuous XORs, which makes coding easy !
For a quick test, I wrote lfsr.c which helps visualise the behaviour. The code kernel is a 2-steps dance, with rotation followed by selective XORing.
U32 lfsr() {
U32 u=LFSR_reg;
if (LFSR_reg & 1)
u ^= LFSR_POLY;
LFSR_reg = (u >> 1) | (u << 31);
return LFSR_reg;
}
To help put this code in perspective, I also created a small LSFR with circuitjs using a 5-tap with another ultra-dense poly 0x1E.

One of the subtleties of LFSR poly notation is that the MSB (which is always 1) describes the link from the LSB to the MSB and does not imply a XOR gate.
Unrolling the LFSR is pretty easy witch copy-paste. It is however crucial to keep the connections accurate.

Each column of XOR2s has their own 5 signals so all is fine and should work. However we have seen already that GHDL has some issues with massive assignations, a shortcut is necessary. It's easy to spot when we move the wires around : there is no need to copy a stage to the other, just get the value from the appropriate previous stage directly.
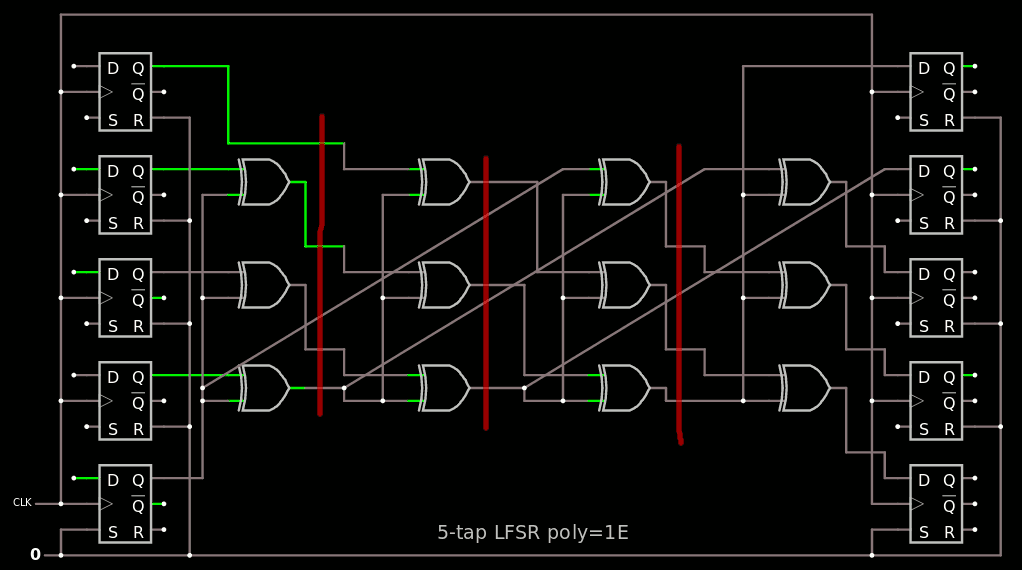
Still 5 wires between each stage but only 3 need to be stored, the others are retrieved "from the past". From there the rule is obvious : the benchmark needs only as many storage elements as there are XOR gates, which is 29 for the 0xFFFFFFFA poly. The new issue now is that the 0x1E poly is not totally like 0xF...A : there is one bit of difference. I will now illustrate it with a reduced version 0xFA and extrapolate from there. Here it is with circuitjs:
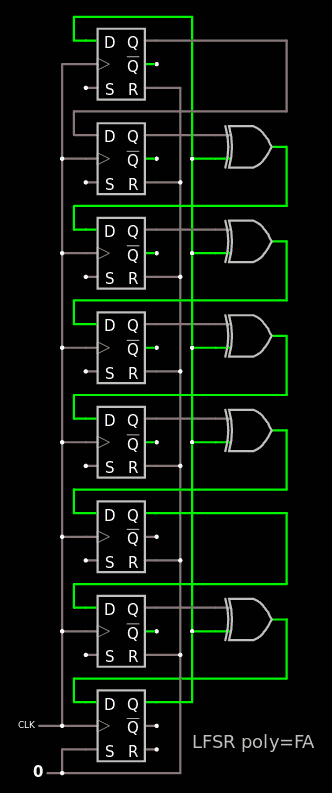
By coincidence, 0xFA is also a primitive poly so it also provides a 255-cycles loop, just try it ! The 32-bits implementation will simply add 6×4 consecutive XORs to the circuit.
Unrolling is very similar. The critical part is to get the connections "right". Fortunately, the only difference is the absence of a XOR just above the LSB, which is translated by sending the result to the cycle after the current cycle. The resulting circuit is :
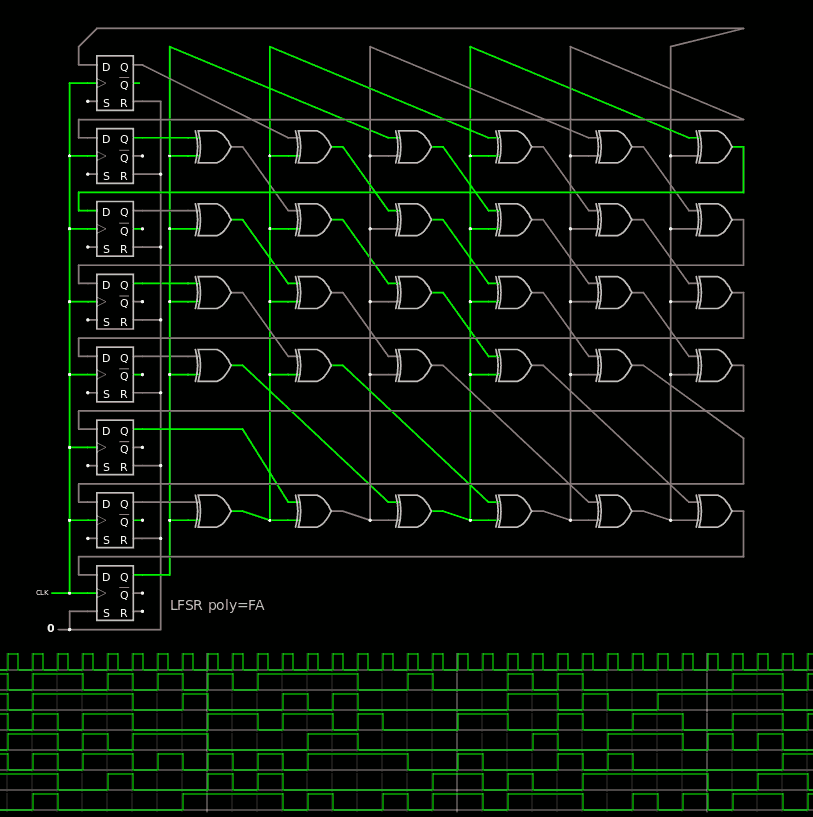
Note: there are 2×3=6 stages, while the LFSR has a period of 255=3×5×17 so the resulting circuit still has a period of 255. Not that it matters but 1) it's good to know in case you encounter this situation 2) it motivates me and brings challenging practical constraints into the benchmark :-)
So all there is to do now is to add as many taps as necessary to get back to 0xFFFFFFFA. Oh, and also deal with the initial and final taps... So let's map the 32 taps to the 29-xor vector, called XOV, at time t:
- All gates receive one signal from XOV(t-1)(0)
- The other signal comes from t-1, t-2 and t-3:
- For XOV(t)(0) : XOV(t-2)(1)
- For XOV(t)(1 to 'last-1) : XOV(t-1)(2 to 'last)
- For XOV(t)('last) : XOV(t-3)(0)
This list of spatio-temporal links is illustrated below:
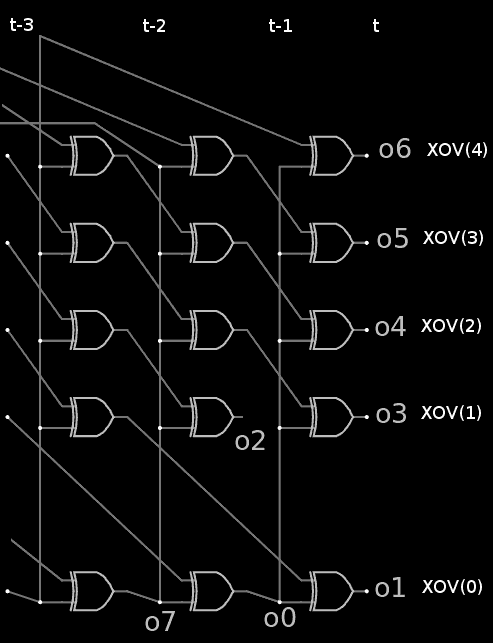
From the theory point of view, this shows how the Galois and Fibonacci structures are 2 ways to express the same thing or process:
- The Galois performs in parallel, all the elements are available for one point in time.
- The Fibonacci structure is serialised, with only one value changed but with visibility into the "past", the previous values.
The circuit described here is in the weird crossover region between these approaches. The above list shows how to wire the XOR gates and the outputs.
Connecting the inputs is a bit less trivial though.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.