 Drass
DrassTeam C74 is once again on hand and the objective is to build a next generation TTL 6502 with the highest clock-rate we can muster. The focus will be on reducing the cycle-time while keeping CPI fixed. The over-arching goal as always is to learn and to have fun. This project promises ample opportunity for both, so we'll buckle-up and get ready for a bumpy ride!
The effort breaks down into a few key strategies:
1) Use faster hardware
2) Optimize critical circuits
3) Increase parallel processing
4) Manage signal integrity
Let's look briefly at each in turn.
Memory is a key area where faster hardware is essential. Both external memory and the microcode store will need to keep up with a faster clock-rate. Fortunately, access-time can be reduced almost at will using RAM. Hobby-friendly 10ns RAMs are readily available, and synch RAMs are even faster. The latter expect an addresses in advance of the cycle, and deliver in return access-times that are vanishingly small. It's safe to say memory is not likely to be a bottleneck in this design.
By the same token, there are also faster logic families available. The 3.3V LVC family, for example, has a good selection of parts at almost twice the speed of AC logic. The CBTLV family offers 3.3V variants of FET switches which can be very fast when deployed correctly. And then there is the AVC and AUC families. With near-nanosecond propagation delays, these families also feature variable impedance outputs which "provide great signal integrity without the need for external termination when driving traces of moderate length (less than 15 cm)". All-in-all, it's an embarrassment of riches when it comes to fast components.
But there are limitations also. For example, there is no equivalent to the 74AC283 Adder in these faster families, and FET switches are no faster with Select signals than their AC family cousins. Some careful design will be needed in critical circuits to capture the potential gains. ttlworks’ FET Switch Adder is a good example this, but there are others. The Decode, Flag Evaluation, and Branch Testing circuits are a few examples that are likely to land on the critical path.
Beyond specific optimizations, we'll need to look to increased concurrency. The C74-6502 divided its processing into two stages: the FETCH stage, and the everything-else-stage (aka EXECUTE). An obvious improvement is to split EXECUTE into shorter phases. As we discovered, pipelining can get very complicated very quickly, with multiple caches, hazard checks and branch prediction schemes. So we'll need to be careful lest the whole thing get out of hand. Thankfully, there are significant gains to be had with more TTL-friendly techniques. More on that later.
The final leg of the race is all about signal integrity. Trace geometry, stackup and clock management will all need careful attention. We are likely to need six layers boards, impedance controlled traces and a mixed-voltage supply. It's gonna be fun.
It was not until 1992 that DEC Alpha and HPPA RISC took the computer industry as whole beyond the 100MHz mark. Is it possible for a discrete-component 6502 to reach that same 100MHz milestone today? Well, we're gonna try to find out!







 spudfishScott
spudfishScott
 Brandon Reinhart
Brandon Reinhart
 Dave Collins
Dave Collins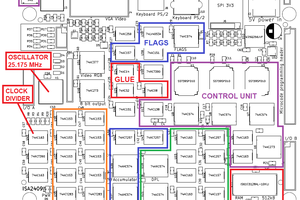
Lets talk about that FET carry chain. You last mentioned "74AUC2G53". I've been using SN74CBT3253 which are 4way transmission gates, and slower to switch, but less ohms. Similar capacitance.
Every slice of my carry has to slog past the combined capacitance of four TGs and a XOR at roughly 3.5pF each. Wondering: Should I have used a 2way TG to switch between propagate and replace? To skip past 7pF of unneeded generate and annihilate TGs when the propagate path is active.
Maybe 74AUP for XOR? Slower than AUC, but have 1pF inputs. I question how far can the unbuffered carry chain be stretched before it demands some help? Momentarally forgetting your objectives are 6502, I had something wider in mind.