-
Prototype 0b - close, but no cigar
10/01/2020 at 22:17 • 0 commentsShortly after my last log, I went ahead and wired up the 6502's NMI pin to a vsync-style pin in my video output circuit (actually marking the end of the visible reason rather than the actual sync pulse). I added some basic NMI handler code - the same as the IRQ/BRK handler, but simpler because there's no need to detect BRK vs IRQ, and no need to read the BRK instruction's argument byte - and tried it out.
It seemed to work first time, which I was satisfied by, but also not surprised because I kind of anticipated it - because the basic task switching was all done through software interrupts, it was pretty natural that it would also work from hardware interrupts.
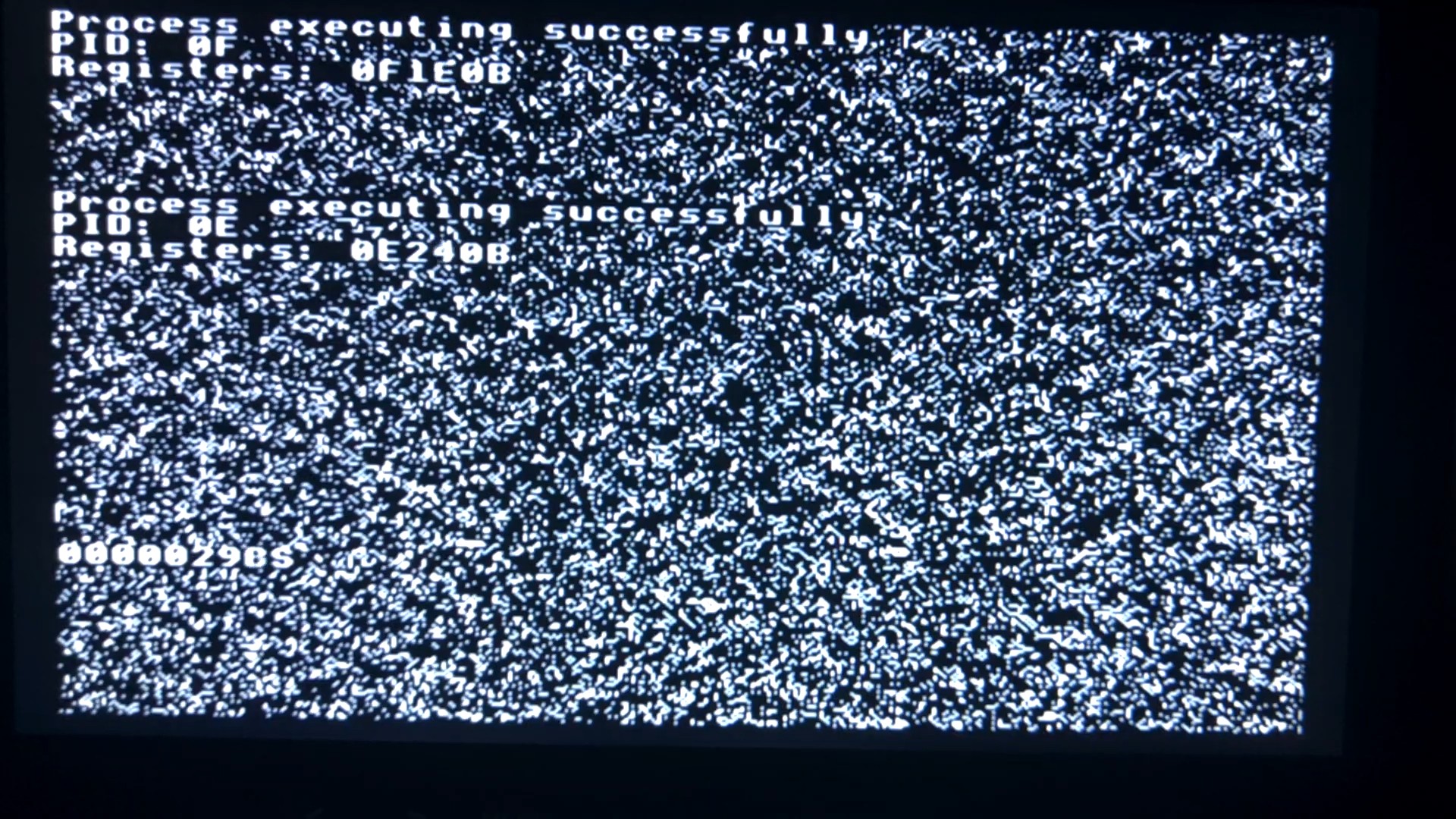
Here's a video of this in action, and a screenshot for quick reference:
![]()
What it's doing
The 32K of RAM is divided into eight pages. Four of the pages correspond to the area of RAM that the video circuit displays on the monitor. The RAM is not cleared on startup, hence the weird random background pattern you see.
The supervisor takes page 7 (the bottom quarter of the screen) for its own video output, and displays a counter showing the number of context switches that have occurred. It also takes page 1 to use for its zero page, stack, and general memory.
Then it spawns two instances of a test program. Each gets a page of non-video memory (page 2 and page 3) for stack and general use, plus a page of video memory (pages 4 and 5). These processes just show their process ID, then sit in a tight loop printing their register contents onto the screen. The NMIs interrupt them and the supervisor schedules a new process to run, using a least-recently-used queue.
So what's the problem?
This works fine in most cases, but due to the fact that NMIs are non-maskable, I really need to ensure that all my code - including all the supervisor code - is OK to be interrupted. Easier said than done! Let's go through some of the issues and resolutions:
1. My NMI and IRQ handlers were not reentrant
As I was initially just writing a BRK handler, I didn't make it support being re-entered - the supervisor will never call BRK itself anyway. It's much simpler and more efficient to save the registers to fixed memory locations than to push them onto the stack. Still, with hardware interrupts a possibility, this code needed to use the stack instead.
As a technical detail, it's still the case that neither the NMI handler nor the BRK handler will actually get re-entered while they're already running. The supervisor indeed never issues a BRK, and the NMI is triggered at a low enough frequency by hardware that it will never trigger quickly enough to catch the supervisor before it's handed control back to a user process. However, the critical case that can occur is when a BRK is executing, and the NMI fires. That's the case that needs to be guarded against. So it would be sufficient to just make one or the other be reentrant.
2. NMI can occur while the supervisor itself is active
As it's possible for an NMI to occur while a BRK is being handled, the NMI handler needs to cope with interrupting the supervisor. The general behaviour needs to be different, because the supervisor is not currently activated like a normal user process. In fact, given a way to detect that the supervisor is running, the easiest thing to do is just exit the NMI as quickly as possible without doing any damage. The only purpose of the NMI is to forcefully interrupt user processes.
The difficulty is reliably detecting that it was the supervisor rather than a user process that was interrupted. At the hardware level, I didn't build in a way to read back from the PID register. I tried shadowing it in software, but this was futile because it's not possible to update the shadow and the actual PID simultaneously. There will always be a gap where they don't match, and an NMI in that gap is impossible to handle cleanly.
3. NMI pushes data to the stack
The first thing NMI does is push the flags to the stack, followed by a return address. This means that, at all times, it's important that the stack pointer is valid and nothing important is stored below it. Sure, that seems a reasonable assumption... but when switching tasks, I need to adjust the stack pointer to match wherever the new process's (or supervisor's) stack pointer is meant to be, and I can't do that atomically in the same instruction that changes the PID register - it has to come either before it, or after it.
If I adjust the stack pointer before setting the PID register to a user process, then an NMI in the meantime would corrupt part of the supervisor's stack, as for one instruction the stack pointer would have the user process's SP value while the PID register is still set for the supervisor. On the other hand, if I set the PID first, then there will be a moment when an NMI would corrupt the user process's stack, as the supervisor's stack pointer would still be set in SP and the NMI would push flags etc to the wrong location in the user's stack.
Similar concerns apply when setting the PID back to the supervisor PID - the stack pointer can't be changed simultaneously with the PID register, and this can lead to corruption.
It's possible to work around some specific instances of this issue, e.g. when the supervisor's stack doesn't actually contain any precious data, but in general I think this issue can't be solved in software.
Solutions
So overall there are some pretty big flaws there. It's only in rare cases that they'd actually happen, but they can't just be ignored.
What can we do about them? Here are the main mitigations I've considered:
1. Mask the NMIs somehow
Maybe I can OR the NMI signal with a masking signal that I can control, allowing the supervisor to block NMIs at critical times. This would operate much like the SEI instruction for regular IRQs, but would be done in a way that user processes won't (in the long term) be able to access.
One interesting option is to mask them whenever the PID is set to zero. This would ensure that the supervisor is not interrupted except possibly at times when it has temporarily set a user PID (e.g. to write to the page table), and in those cases I could take necessary precautions.
2. Drive the NMIs from a controllable timer
This is kind of similar in effect - rather than interrupting at 50Hz, I could wire the NMI up to a resettable timer, e.g. using a 6522. Then I could make it so that the timer gets reset on BRK, before fully entering the supervisor. The only purpose of the NMI is to ensure that user processes yield from time to time, and so long as they're calling BRK occasionally, there's no need to interrupt them further. If they're not, then the NMI will do its job.
3. Use IRQ instead of NMI
This would ensure that the supervisor never gets interrupted, or at least allow me to control at what points it can get interrupted. The reason I didn't do it this way in the first place is that user processes can very well set the interrupt-disable flag themselves and never have to yield, and there's no good way to prevent that - it's much harder to guard against than the other protection measures I'm planning to take in later prototypes.
That said, though it's lower on the priority list, I do have a requirement listed to be able to forcibly terminate processes that are not yielding, and this would be necessary even with NMIs for cases where an illegal instruction has been executed. So I might be willing to overlook this aspect of "bad behaviour" for now, and deal with it later on.
4. Change the PID/pagetable architecture
Part of the problem here is the way the PID needs to be set in order to configure the pagetable. It already makes some aspects of memory protection harder, so might be something to change.
If the supervisor didn't need to temporarily set the PID to write to the page table, then the only cases where it would need to write to the PID would be on resuming a user process, and in the interrupt handler when one is interrupted. In these cases the supervisor's stack is not precious, so the SP atomicity issue goes away.
Combined with an interface to read the PID, this could also allow the NMI handler to reliably detect when it's interrupting the supervisor, and stop. So it would seem possible that it could solve all the issues above.
Next steps
The whole point of the prototyping process is to uncover these kinds of issues, so it's doing its job. The issues can all be fixed, but I haven't yet thought through what the right fixes are going to be. I might fix them in a revised Prototype 0b (maybe 0c?), or I might just learn from the problems and factor solutions into Prototype 1. It's possible that some of the techniques to implement memory protection in Prototype 1 will help with these issues, or force certain solutions. We'll have to wait and see!
-
Prototyping Roadmap
09/27/2020 at 18:17 • 0 commentsLast weekend I thought quite a way ahead, in terms of where the architecture needs to end up, and wrote up the basic requirements I have for this project, which you can find in the project's Details section.
There are still a lot of open questions about the designs I sketched out last time - in some respects they don't fully achieve what I wanted, but they're already getting complex and I don't want to overthink them at this stage. Instead I want to plan some steps along the way to getting to a point where I can make better decisions about those designs from experience based on earlier prototypes.
Roadmap
So here's the initial roadmap. I'm only planning the first few stages - later stages are subject to change as I go through:
- Base computer - start from a working base and extend from there
- Prototype 0a - adding paging and cooperative multitasking, but without expanding to more RAM, and without memory protection yet
- Prototype 0b - adding pre-emptive multitasking (unless I decide to defer that)
- Prototype 1 - adding simple memory protection so processes can't interfere with the page table
- Take stock and make a better plan for the next steps
---------- more ----------When I get to (5), it's likely that I'll have discovered some major architectural changes I'd like to make. But aside from that, I would expect to work through some higher-priority features, such as:
- Critical API refactoring
- Add more RAM - I have 512K on hand for this
- Move decoding to after the page table
- Use a PLD for the decoder if I haven't already
- Add R/W/X permissions, may need to expand the page table output width to 16 bits
There are also some lower priority features that I'd probably go on to after that:
- Non-critical API refactoring
- Software features - IPC, semaphores, etc
- Recovering from locked-up processes (e.g. illegal instructions)
- Multithreading
This is just a rough list though and again I'm not thinking too carefully about the order of things that far ahead.
1. Base computer
First and foremost, I don't really want to build a fresh computer from scratch. I'd rather extend one of my existing ones, and I have a plan for how to do that.
I'll use my main homebrew computer, which was my own design from the ground up, and incorporates in particular a video output subsystem as well as a 6522 providing multiplexed I/O to an SD card reader, an LCD and some buttons, a digital tone generator, and an addressable latch because you never know what you can never have too much addressable I/O. It also has a debug port that will come in handy here.
Those modules aren't exactly necessary for this, but the video output will be good to provide a convincing demonstration that it's all working - because it provides a clean way to see output from several processes in parallel without needing any software semaphores etc - and the rest of the I/O is useful because I also want to explore ways in which the processes can be given selective access to I/O devices without completely breaking the protection layer.
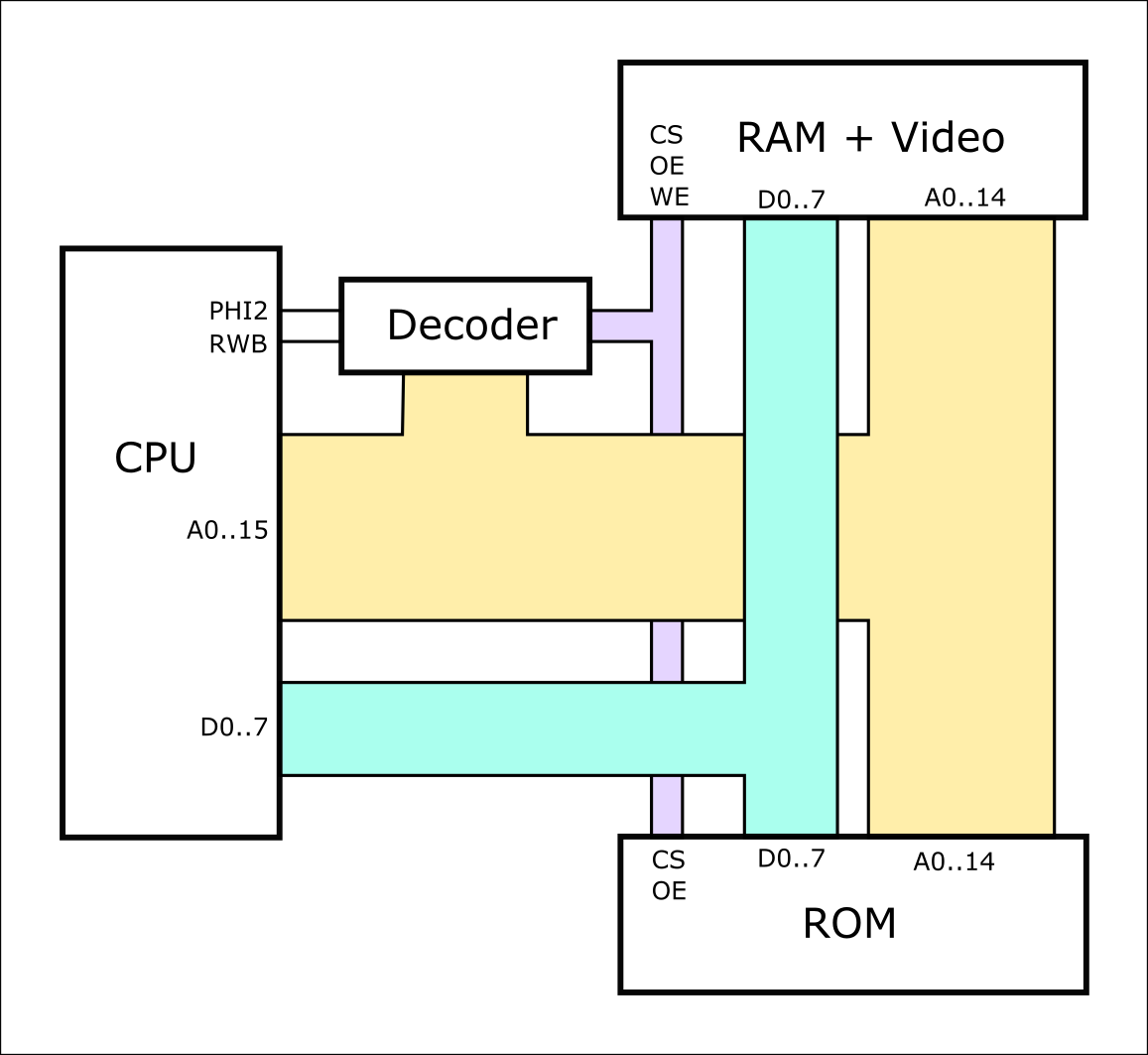
The basic architecture there is fairly standard, and I've uploaded a block diagram of it:
![]()
There's nothing unusual about this, except that I've lumped the video decoder into the "RAM" box, because the CPU's view of it is just like normal RAM - all the CPU's RAM is actually inside the video circuit. I didn't draw the I/O on here either, but it's just more of the same.
2. Prototype 0a
Next up, what's are the minimal changes I can make here, to achieve Prototype 0a? All I want to do for this is add process-based memory paging, so that two independent processes can coexist and run cooperatively without fighting for memory.
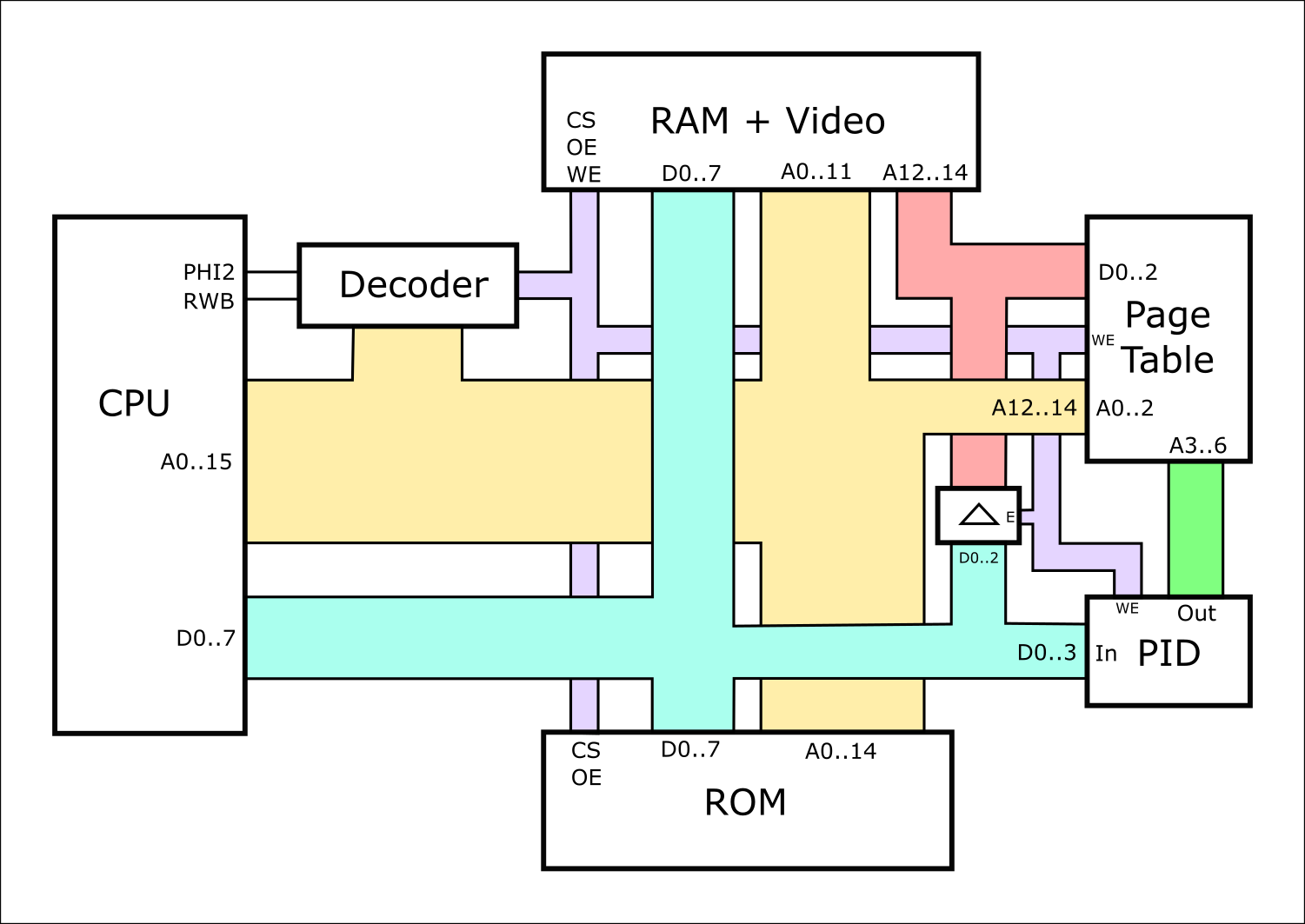
Two key components are a hardware notion of "process ID" or "PID", and a page table for tracking which physical RAM locations are used by which logical addresses, for each process. Initially I'm locating the page table in a separate RAM chip for reasons I'll explain below. Here's the updated block diagram:
![]()
The changes are all on the right hand side. Instead of routing A12..14 through to the RAM, they go into the address pins on the Page Table (PT). Then the PT's data pins drive the RAM's A12..14 lines. So the actual physical RAM address is remapped by the PT.
In addition there's an 8-bit register to store the Process ID (PID). This also feeds into the address lines of the PT, meaning that each process has its own distinct mapping of A12..A14 values.
Writing to the PID and the PT
The PID can be written from the data bus, under control of an I/O enable line from the decoder; and the PT can also be written based on another decoder line which controls the PT's Write Enable pin and also the Enable pin of a bus buffer or transceiver, allowing the data bus to write through to the PT's data pins. I'm actually just using resistors for this at the moment, to save putting a transceiver in - so that the short bus from the PT to the RAM will be driven weakly by the data bus any time the PT itself isn't driving it - but that's very lazy of me.
This general mechanism of writing to the PT is simple in hardware, but complex in software for two reasons. Firstly, I normally use A12..14 as part of the decoding process - when A15 is set - to choose whether ROM or I/O is being accessed. But when writing to the PT, it requires A12..14 to choose which PT entry to write - so I need to use some other address bits to actually enable the PT write in the decoder. Ultimately I use A15 && A11, and the addresses I end up writing to are $8FFF, $9FFF, $AFFF, etc - to write entries for page 0, page 1, page 2, etc. Not very tidy! These writes conflict with ROM a lot of the time, and other I/O devices some of the time, so it's important that those devices that are conflicted with are themselves read-only. For now I'm OK with this but I'll need to update the decoder soon as it's not really sustainable like this.
The second complexity is that when we write to the PT for a user process, the actual write needs to occur with the PID set to the target process's ID. In this state, any RAM accesses will be mapped according to the user's memory map, not the supervisor's. This means that we can't access the supervisor's zero page, stack, etc. until the write is done. But writing to an arbitrary location spread across the high half of the memory map is only possible if you do it indirectly via an address stored in zero page. So we need to reserve a few bytes of zero page in the user's memory map for OS use. It's ugly because in general we don't need to do this - the supervisor has its own, separate zero page, and user processes don't need to reserve any.
In the long term I am going redesign the hardware to solve both these problems - it will probably involve some encoders on the PT's address inputs to allow the supervisor to inject any data it wants there, rather than having to rig the PID and A12..14 to the correct values. It can be triggered by the same signal as the (missing) data bus transceiver. But for now I can just about get away with not doing this yet, and the idea of this first prototype was to make the hardware changes as simple as possible, and make up for any issues in software.
Software
On the software side, I branched my regular 6502 code repo and hacked some new functionality into the OS code as a proof of concept. On startup it immediately sets the PID to zero and maps logical page zero to physical page one, by writing a 1 to $8FFF. This is to ensure that the supervisor has some RAM, and in particular a stack.
It then proceeds to create two processes, each with its own separate logical page zero, and with its logical page 4 mapped to different areas in video RAM. I picked page 4 because that's where the start of video RAM normally is on my computer, and so all the text output routines etc are happy to write there. But at the physical level, one maps to page 4 and the other to page 6, so the two processes end up writing to different parts of the screen.
The processes are then added to a "run queue" - a list of processes that can be executed - and a very basic scheduler hands over control to one of the processes, mostly by setting the PID register and executing an RTI.
The process runs until it issues a BRK instruction, at which point the OS interrupt handler executes. This is my usual code for handling interrupts - it determines that the interrupt came from a BRK and calls a BRK handler. This all runs within the context of the user process, because detecting BRK requires us to read from its stack - that's possible for the supervisor by changing its own memory map, but I didn't want to bother with it. Once the interrupt cause is identified, the BRK handler runs, and this saves the registers and stack pointer at $100-$103 and then reads the BRK data byte into the A register before entering supervisor mode.
Entering supervisor mode is achieved by setting the PID register to zero, setting the stack pointer to $FF, and clearing the X and Y registers. The A register still contains the command code from the byte after the BRK instruction. The supervisor doesn't have any important state to restore on returning from user mode, so clearing all these things to standard settings is good practice to remove potential for userspace to exploit any bugs due to them being unset.
At this stage the BRK command code is just ignored, as there aren't any functions provided by the OS yet. One day user processes will be able to request more memory pages, terminate, spawn other processes, perform I/O operations, and do inter-process communication. Right now though the command is a no-op, and just serves to yield to the supervisor.
The supervisor then returns to userspace by telling the schedule to pick a new runnable process and resume it. The procedure for that is exactly as before, ultimately executing an RTI in the processes context, which will resume from after its BRK command byte.
Prototype 0a status
So this is all working now, and I can run multiple processes, with each outputting to a different region of the screen, with their zero pages and stacks in separate banks of physical RAM. I might capture some video footage of it working and upload that. But then it'll be time for Prototype 0b!
3. Prototype 0b
This is planned to be just a small update to add pre-emptive multitasking. It shouldn't be a big deal, it just requires setting up an external timer source. I might pull an existing time signal from the video system (e.g. the hsync or vsync) or something like that. The 6522 is actually not plugged in at the moment; another option is to plug that back in and use one of its own timers.
The general idea will be driving NMI to cause an interrupt (which the process won't be able to block with SEI). This will then enter through the NMI vector and forcibly suspend the process in much the same way that I already do for the IRQ vector when BRK occurs. The NMI handler won't do anything fancy at this stage - just as with BRK, all it will do is save the process state so that it's able to be resumed later on, and then chain to the scheduler.
4. Prototype 1
The purpose of Prototype 1 is to finally add memory protection, and this is what qualifies it to have a version number of 1!
While the user processes in Prototype 0 have separate views of memory, by virtue of having different page table contents - and their page table entries don't map memory that the user process isn't meant to access - they still have full access to rewrite the PT and PID register in the same way the supervisor does, by writing to $8FFF, $8200, etc. A user process could very easily write a 1 to $BFFF, meaning that its own logical page 3 gets mapped to the physical page 1 - and that's the same physical page that the supervisor's logical page 0 is mapped to. Now it can corrupt the supervisor's memory, where it stores things like the list of active processes. Or it could map a different physical page, and access memory belonging to a different user process.
Clearly we need to prevent user processes from doing these things. As discussed in earlier log entries, one easy way to do this is by adding a hardware flip-flop that records whether the system is in user mode or supervisor mode. This needs certain logic to flip its state at the right times - again I discussed a lot of options there in an earlier log.
Another option was to gate supervisor mode based on the current PID value - this is appealing because it doesn't require adding any new hardware components, but it would break the existing prototype because the supervisor needs to set the PID before being able to configure the PT for a user process, and this would essentially take it out of supervisor mode into a state where it no longer has permission to write the PT.
I've also considered using the top bit of the PID register to indicate user status - so the supervisor can make sure not to set that bit until it's really ready to hand control to a user process. When setting up the PT, etc, it will leave that bit clear and just set the lower bits to control the PT address pins. It will still be necessary to have a controlled entry into supervisor mode, which could be achieved by simply clearing the PID register, if I use a register with a clear pin.
I'm still in the frame of mind to do the simplest thing that reasonably achieves my goal, and am avoiding adding a lot of hardware. But a further option here is to swap some existing hardware - the decoder is currently built from some logic gates and a 74HCT138, and I could replace it with a PLD and achieve the same logic functions plus storing a supervisor bit or whatever else I want to do, all in one chip. So it's adding one complexity while removing another.
I might want to explore the non-PLD options first, as the goal of this project is to experiment with different things, but I'm pretty certain I'll end up going with the PLD in the end, as it will resolve a lot of problems that I know I already have in Prototype 0a.
5. Beyond!
As I said, I don't want to speculate too much on what's beyond. But I will say that performing the decoding before the PT's address translation is not ideal. It means that user processes can't easily be given access to I/O devices (which may not be a bad thing), and it means user processes lose as much of their address space as the supervisor needs in order to manage the I/O devices, and access its ROM code.
Choosing a PT address based on the CPU's high address bits and the PID content is also not great.
It would be very appealing to move the address decoding to occur after the address translation - i.e. hook the PT up directly to the CPU, with the decoder being based on the remapped address it outputs. This would solve both the above problems.
The drawbacks are that it's critical that the PT actually has some sensible data in it on power-on reset, as the CPU won't be able to initialize it directly without it already being set up; and actually writing to the PT is going to be complex because the PT itself is "in the loop" during the write cycle. What I mean is, in order to write to the PT we'll need to write through some logical address that the PT itself will remap, before it hits the decoder, and the decoder then says "this is a write to the PT". Now we need to swap the PT from output mode into write mode, give it a totally different address, and connect its data bus to the CPU's data bus. In the meantime we need to latch the fact that this is what we're doing, as otherwise while we do this the decoder is going to stop saying "this is a write to the PT".
There are two main ways I can envision doing that, but I haven't thought them through yet. One is to write to some other latches, then arrange for those to have their values written into the PT after PHI2 goes low. It's important that the PT is back in output mode well before PHI2 goes high though, to meet address setup requirements on writes to RAM etc. But this could work.
The other way is to latch a flip flop when PHI2 rises based on whether it's a PT write cycle, and if it is, swap the state of some encoders so that the PT's address pins come from lower CPU address bits rather than the usual places. The data lines are already catered for in my current setup. This means the PT is going to see a shortened "write" signal, but I use very fast RAM as a matter of course, so this shouldn't be a problem (my video output circuit does the same thing).
But that's a decision I'm not going to make yet! One step at a time, simplest things first...
-
When to enter/leave Super Mode?
09/22/2020 at 00:56 • 0 commentsBefore getting back to general architecture, let's talk about Super Mode, because that's pretty fundamental to the memory protection scheme.
This is going to be quite a long brain dump of where I've got to in thinking about this. I'll try to add some structure, and hopefully it won't be too hard to follow, but there may be way too much information for comfort here, and some things might not make sense! Feel free to ask if that's the case, maybe I missed something, or could explain my thinking better when less tired!
Paging vs Protection
Most of what I've described so far is more about memory paging than protection. It's true that pages that aren't mapped can't be accessed by a process, but the page table itself, and the PID register, and the system I/O, are all vulnerabilities that user processes shouldn't have direct access to, except in special cases where access is explicitly given and the risk of privilege escalation is accepted.
As I said before, transparent address translation is pretty fundamental, partly because of the level of protection it does automatically provide, and partly because the 6502 stack, and to some extent zero page, are at fixed locations in memory. It would be possible to segment up those bottom two pages and apply protection checks based on the PID for example, but it would limit the system to a very small number of PIDs and/or not much stack/zero page space per process. So transparent paging based on remapping address lines through a page table is obviously the way to go.
We do need some way to set up the page table though, and some way to create new user-mode processes, and a way to switch which process is running. User-mode processes themselves shouldn't have the ability to do this directly, as it's open to abuse - so they need to be able to execute some trusted code that can set these things up without leaving any loopholes to be exploited. That code is the supervisor.
---------- more ----------Hardware difference between supervisor mode and user mode
What is it about the supervisor that means it does have access to set these things up, while user processes don't? It's an interesting question. I've considered three main answers for it.
- The supervisor code is running from ROM, i.e. code running at certain addresses is trusted
- There's a special hardware state that's activated on entering supervisor mode, and deactivated on leaving it (a "super flag" or "user flag", I've used both terms I think)
- The supervisor simply has mappings in its page table that other processes don't (but could) have
1. Supervisor code is in ROM; code at these addresses is trusted
Regarding the first one, it is extremely limiting from a security perspective. The big problem with it is that a user program could call into the supervisor code in ROM at any address, and it could be possible to find a particular address that could be called which, though it's not an intended entry point, would lead to some breach of security that the user process could exploit.
This can be mitigated by vetting the code to ensure no such vulnerabilities exist; but that's impractical for a large amount of code, and easy to get wrong.
Another issue is that it precludes choosing to delegate the authority. I don't consider that a showstopper, but it's a shame.
2. Hardware state to indicate Super vs User mode
The next possibility is some kind of hardware flag that indicates whether the system is currently executing in Super mode or User mode. There are various forms this could take, but for now imagine a simple 1-bit D flip flop (74HCT74) that's set or clear to indicate the mode status.
As it's a persistent flag, the key point to consider is when the transition takes place. In particular, transitioning into super mode must be carefully controlled - it must not be possible to transition into super mode and immediately execute arbitrary code.
I'll come back to this in a bit, but want to discuss option 3 first.
3. Supervisor has privileges because of page table content
The whole idea of the page table is to provide different processes with different views of the system, and especially to limit processes to accessing resources that they are entitled to access. So it's natural to wonder whether we could use it to also limit access to fundamental system configuration aspects like the content of the page table itself.
The basic idea here would be that, even in supervisor code, all bus accesses get mapped through the page table. Instead of plugging a decoder into the high bits of the CPU address bus, it would operate based on the output from the page table. Perhaps the high three bits encode 000 for a RAM access, 001 for a ROM access, 010 for accessing a VIA, 011 for reading/writing the page table, etc. It's the same as what we've always done on the CPU address bus, but applied after address translation.
It is appealing and I might pursue it one day, but there are two big problems to overcome if I do - firstly, something needs to set the page table up initially, otherwise it won't have the entries it needs to permit the supervisor to initialise it; and secondly, writing to the page table would require two accesses to the page table RAM within the same clock cycle - first, to read the translated address; and second, to write new data into the page table. The PT's input bits would need to be set differently on the second access, and that's tricky to arrange. Not impossible though.
How to enter Super Mode
I want to go back to option 2 now, as it seems to be the most likely choice for a first implementation - it's simple enough to be practical, but powerful enough to achieve most of the goals. So given that there is a persistent Super mode flag, let's think about when and how it would get set.
Using an interrupt
One common way to manage this in many architectures is to make it so that the only way to transition into super mode is through an interrupt. Interrupts are special because the CPU drops whatever it's doing and runs code at a specific address, and we can carefully control what that code is to make sure there's no way the user can set some bizarre state just before the interrupt that exploits a vulnerability. There's now only one place in the code that we have to fortify.
Interrupts usually come from hardware, and in these cases it is also natural that the supervisor gets to handle the interrupt. However, they can also come from software. ARM has the SWI (software interrupt) instruction; x86 has the INT instruction; and the 6502 has the BRK instruction.
BRK causes a regular interrupt sequence, but also stores a flag that you can use to detect that it was a BRK rather than a hardware interrupt; and the byte following the BRK instruction is skipped in execution, meaning you can store an operation code there if you want to let the user process choose between different functions the supervisor can provide. For example, function 0 might be "terminate process"; function 1 might be "give me more memory"; function 2 could be "sleep for a while". This methodology is very common in newer architectures and operating systems. Normal registers can also be used for additional inputs, and outputs.
One issue with doing this on the 6502 is a CPU bug which manifests if a hardware interrupt occurs at the same time as a BRK instruction is about to be executed. In this case the hardware interrupt wins, and the BRK is not properly executed - or viewed another way, the BRK is executed, but without setting the bit that tells the ISR that it was a BRK. It's possible to work around this, but kind of annoying. I think it was fixed on the WDC chips at least, but that means you need to not work around it on those... ick.
Another disadvantage to the BRK flow is that it's relatively slow, taking quite a few extra cycles.
But how can we detect interrupts and set the flag? On a WDC CPU that's actually pretty simple - it has a specific pin output called VPB that gets set whenever it's reading one of the vectors, which happens very late in the interrupt process, just before it starts executing the ISR code. For legacy NMOS CPUs it would be much harder to detect.
Based on execution address
An alternative to using BRK is to enable super mode when an opcode is about to be fetched from a specific ROM address (or multiple addresses). If user code calls these addresses, then the system transitions to super mode and can continue to run the ROM code; if the user code calls an unapproved address in ROM then super mode would not be activated, and the user process should be blocked from reading from ROM, and get terminated instead.
In terms of implementation, it's fairly simple to check in hardware for certain addresses or bit patterns on the address bus, simultaneous with "sync" being high which indicates that the CPU is starting an instruction, and use that to set the super flag. You mustn't do it when "sync" is low, as user code could simply try to read from these addresses to enter super mode, and it shouldn't be able to do that.
Assuming the VPB test above isn't also being used, it would be important to ensure that IRQ and NMI handlers go through an approved address, so that they also have the flag set - otherwise they'll just keep running in user mode. The vector addresses would also need to be readable from user processes, as when the interrupt is first picked up, the system will not yet have switched to super mode.
This method can let user code choose between different entry points for different supervisor functions, which could have its benefits, being more efficient than parameter-passing by other means.
Based on a specific opcode
Finally, I thought it may be possible to enter super mode when a certain opcode is detected on the data bus, with "sync" high. The instruction would need to be something benign, or we'd need some juggling on the bus to send a different opcode through to the CPU. Ultimately I don't really think this is worth considering deeply - it would add a lot of hacky complexity, and doesn't seem to have significant benefits.
How to leave Super mode
On the other hand, how could the supervisor return control to a user program? This is less of a minefield security-wise because the supervisor is in control from the start, but of course it needs to happen smoothly, with the user program - which may have been involuntarily pre-empted - able to continue from where it left off. It's also important that it does happen properly and cleanly, i.e. that there aren't cases where execution could return to user code without dropping the super flag first, or cases where the flag getting cleared at a bad time causes memory mapping issues.
Note that the supervisor won't necessarily want to pass control back to the same user process that was running already. Especially when pre-emptively task switching, it needs to hand control to a different process.
Returning to an interrupted process
Let's start with the case of returning to a user process which lost focus due to an interrupt - either BRK or a hardware interrupt - because whether or not interrupts are the sole way to enter Super mode (as discussed above), they will certainly need to be at least one valid way to enter Super mode.
When an interrupt occurs while a user process is running, the CPU will wait until the end of an instruction, and then push the two-byte address of the next instruction onto the stack, followed by a copy of the status register (possibly with B cleared, if it was a hardware interrupt), and it will then fetch the ISR address from one of the vectors at the top of the address space. It's important to note that the ISR address is fetched last - and it is the earliest time we'd possibly know that we're entering Super mode (i.e. if we're using VPB to detect this). This means that all the stack activity so far must happen on the process's own stack.
In order to return to this interrupted process, we can either pick these values off the stack ourselves, or use an RTI instruction to do it. Either way, when we're done, the CPU will start executing from where it left off, and we need to be back in User mode by that point.
One way to trigger the transition to User mode could be to just always do it whenever the CPU fetches an opcode from RAM rather than ROM - or specifically from outside of a defined range of addresses that contain only the supervisor's code, and that can only execute in Super mode. However, this only works if the ROM remains visible during User mode, to guarantee that user code is never executing from that address range.
I don't really want to keep the supervisor code present in the user process's address map though, so need another way to detect leaving Super mode. Another option, then, is to have reading an instruction from a specific address be the cue to leave Super mode. That instruction could be the RTI itself. So by placing the RTI at a known address, with hardware to detect "sync" being high while that address is on the bus, we could derive a signal to turn off the Super mode flip flop.
This is pretty much the mirror image of one of the techniques for detecting entry into Super mode above. The RTI instruction could be in ROM as usual, or it could be placed at a specific address in the user process's RAM space, e.g. $00 or $0100.
Finally, the brute force option is for the supervisor code to have a way (e.g. memory-mapped I/O) to disable the Super flag explicitly. This is pretty clumsy, and one potential issue with it is if disabling the Super flag affects the memory map, for example if it's not acceptable to execute code from ROM in user mode, then as soon as the flag's turned off, the rest of the "return" code can't run - unless it's copied into RAM or something like that. This code could be simply a single RTI instruction, which is just one byte to copy.
Returning to a non-interrupted process
The other case to consider is where the user process was not interrupted by an interrupt - it made a system call itself, under its own power. If the mechanism for this in BRK then in fact it still behaves like an interrupt and the above all applies. But if the mechanism is a simple JSR, then we can't follow up with an RTI for two reasons - firstly, RTI will pop the flags off the stack but they were never pushed; and secondly, RTI pops the actual return address from the stack while JSR pushes one less than the return address. Both of these can be fixed up of course as part of the entry code, so the RTI is still a good option so long as we take care to do that.
Otherwise we could consider an alternate return path that uses RTS instead of RTI. I think the general theory is exactly the same, so it's not a big deal to support this as well. Especially if we use the method where the RTI instruction is stored in RAM at $00 or $0100, it's really easy for us to put an RTS instruction there instead when we need to.
General considerations when returning control to user processes
Generally we want to restore all register values before returning. This is critical for interrupts, but there are exceptions for syscalls because they may actually need to return data in registers.
After control is passed to the supervisor and the super flag is set, we need to be careful with the memory map. If entering super mode fundamentally changes the memory map, then the user's stack will no longer be visible; yet the stack pointer will still try to point into it. Any attempts to save the A, X, Y, and SP registers will likely write to supervisor memory, not the process's own memory. It's not a problem per se but needs to be borne in mind, especially when returning again.
Let's explore what things look like if the memory map has indeed changed by this point.
The supervisor itself won't have any useful information in its own stack, so there's one less thing to worry about there. It's fine to reset the stack pointer to maximum and carry on from there. Or to not bother, and just keep pushing data wherever it's ended up temporarily, if that turns out to be useful.
It will be necessary to save the user process's A, X, Y, and SP registers somewhere safe, potentially for a while. Due to scheduling, we might return control to a different process, and have to come back later to resume this one. It makes sense to allocate an area of memory for storing each process's saved register states. In order to do this, we need to know which process is currently running, so we can index with it. In order to index, we also need the X or Y register free. So there will be some work to do before we can actually save the values.
To determine the PID, we could perhaps read it from an I/O address mapped to the PID register. But I don't really want to have to make that register bidirectional, due to the pinout of the '273. So let's say we just store a shadow copy of the active PID in super RAM somewhere, e.g. $40, so that it's there waiting for us when the process is suspended. We can store the Y register somewhere temporarily, e.g. $41, and then load the PID into Y from $40 to help us store the rest of the registers:
zp_pid = $40 zp_temp_y = $41 ... sty zp_temp_y ; save Y for now ldy zp_pid ; load PID into Y sta $200,y ; save A value stx $280,y ; save X value lda zp_temp_y ; restore saved Y value into A sta $300,y ; save original Y value tsx ; get the stack pointer into X stx $380,y ; save the old stack pointerThis is using super RAM from $200 to $400 to store saved register values, for up to 128 user processes.
Again, this is assuming that the memory map has already changed by this point, e.g. assuming that setting the Super flag forces the supervisor's stack and other low memory to be paged in. If that's not the case, then at this stage the user process's memory will still be visible. The options are actually simpler in this case - there's no need to explicitly store the registers in super RAM, we can store them in user RAM instead:
zp_save_a = $60 zp_save_x = $61 zp_save_y = $62 zp_save_sp = $63 ... sta zp_save_a stx zp_save_x sty zp_save_y tsx stx zp_save_spThis is obviously much simpler, both for saving and restoring the registers. There's no need to use the stack here - it doesn't need to be re-entrant. The user process won't run again until we've already restored these.
So both of these are viable, which applies will depend upon exactly how the address translation responds to being in super mode.
Going back to syscalls that need to return data, though - it's fairly easy to see that we can still return values in A, X, and Y by simply updating the stored values - either in user RAM or super RAM - before returning.
Summary
This was a long and dense one, but maybe it's been interesting. It's certainly useful for me to brain dump this all out to a log. I can't vouch for the accuracy of sense of these plans yet, and I'm keeping quite a few options open at the moment, until there are clear reasons to go one way or another. Feel free to ask what I mean though if something doesn't make sense!
One conclusion that is standing out at the moment is that if I drop the requirement to also work on NMOS 6502s, and instead focus on WDC 65C02s, this would all be easier to do in a neat and tidy way - the IRQ/BRK bug is fixed in those, and they have a VPB signal. The reason I care about NMOS 6502s though, is that I have one and might want to use that one for this project. As such, and because I kind of swap back and forth sometimes, I prefer to design things that will work on both.
Tomorrow I'll post a simplified sketch for a first prototype, less ambitious than the more full-fat design I posted today, and I'll discuss a bit how the Super Flag might work in that design, as well as how the supervisor would manipulate the page table and access user process memory.
-
Address decoding logic
09/21/2020 at 21:03 • 0 commentsRegarding the decoder, it felt like a really good fit for the PLDs that Dawid Buchwald had been recommending recently, so I thought a bit about how that logic works. What does the supervisor need to be able to do? How can it set up the various control lines to achieve it? How many outputs does the decoder need? Here the resulting logic table:
---------- more ----------![]()
The letters at the side correspond to various types of operation listed above. The signals driving the chips are along the top of the table. The Greek letters are unique outputs from the decoder, as some of the columns are constant or identical to each other. It seems a pretty good fit for a simple PLD, but what about user mode, what's different there?
![]()
Hmm, mostly just constant values in user mode. But the bank register needs another control line here, designated iota. But it's actually exactly the same as "are we in user mode?" so not really necessary as a decoder output.
Maybe eta and theta could be dropped if I'm running low on outputs and want to put other logic in here later. They don't have much in common with the other outputs. I've considered using the spare space in this PLD to implement the Super/User flag.
I also wondered whether I could implement the bank register entirely in a PLD. As it stands I'd need a bus transceiver to gate the CPU's A12-A15 and RW lines, as well as a '273 or similar for the register. Or maybe a multiplexer. But can a small PLD serve both purposes?
It would need five bits of registered outputs to store the value in, and five inputs for A12-A15 and RW to pass through in user mode. But I don't think it would be possible to use the registered outputs to drive the page table in user mode, as they are clocked and it would be hard to clock the new data in at the right point in the cycle. So I'd need another five outputs to actually go to the PT, and I'd make them get set to either the register values (in super mode) or passthrough of the CPU address (in user mode). That's now ten outputs. I also need another five inputs from the data bus in super mode, and also the super/user flag... that's eleven inputs... More than is supported by these chips. 🙁
It's close enough that I think there must be a way to make it fit. Maybe using the address bus instead of the data bus to set the value.. the code wouldn't be pleasant though. There are also other considerations, like the logic for when to go into or out of super mode, and it's possible that I just need to spread some of this logic across several PLDs to get a tidy result overall. Something to come back to later!
-
Requirements and architecture brainstorming
09/21/2020 at 20:32 • 0 commentsOver the weekend I thought a bit about what I want to achieve, what matters most, what I'm not so interested in doing, and drew up a list of requirements to help me balance various design choices. It's in the description above. It will still evolve over time but it's still helpful to have a reference written down.
I also thought a bit about architecture. In order to support multiple processes on a 6502 you pretty much need address translation, otherwise they all have to share the same stack space at 0100-01FF. It's possible to do that (GeckOS does when running on the C64) and I think it's also possible to do it in a safe "protected" way, but it's not very elegant. My goal is to explore the benefits of hardware support anyway. Using memory paging and address translation is more in line with how larger real-world architectures work.
So I thought a bit about how to organise that, what addressing scheme to use, and drew some diagrams on paper. These are horrible to read, but they make sense to me and I wanted to share them anyway. When things are more concrete I'll make some clearer one electronically.
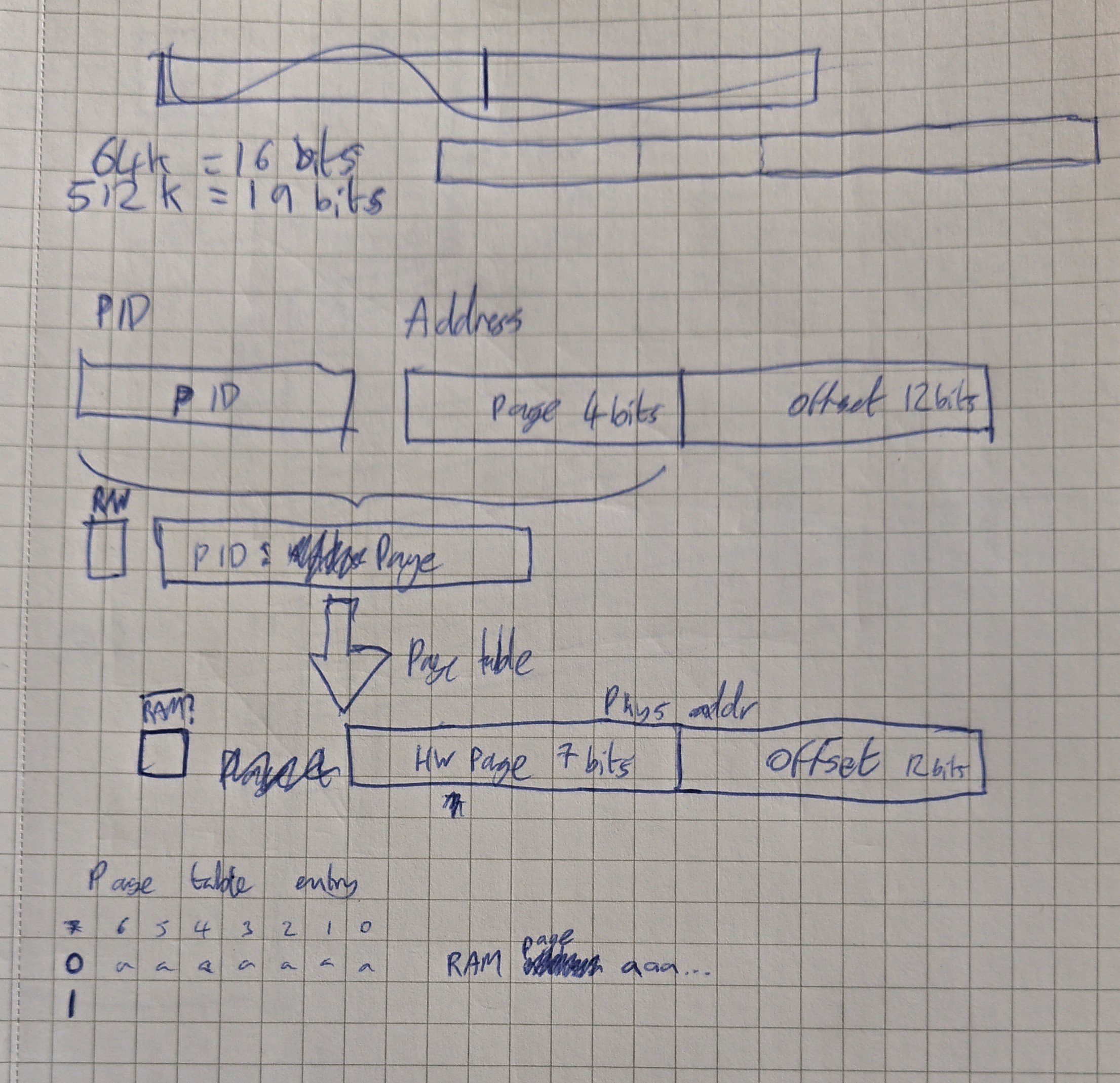
The first is just brainstorming the addressing scheme:
---------- more ----------![]()
I've ordered a 512K RAM chip, that needs 19 address bits. The CPU's address space is 16 bits. I'm going to take the top few bits off that and use them combined with a process ID (and maybe the read vs write bit) to look up the top bits of a physical address in a separate RAM chip. I'm using 8-bit memory (16-bit was expensive) so I don't have many bits to play with in the result. I'll reserve the top bit to flag non-RAM access, as eventually I'd like to allow that kind of thing to be mapped as well. So I have seven bits left that can form the top seven bits of the physical RAM address.
The 512K RAM needs 19 address bits, so there are 12 left. That means my page size needs to be 12 bits, leaving 4 bits at the top end to select which page. It divides the address space into 16 chunks of 4K.
I wasn't very happy with this, I'd prefer to have more, smaller pages. Also this doesn't leave room in the page table output for any restriction bits, e.g. read-only. But I want to keep things reasonably simple at first. Later on I could add a second RAM chip to get 16 bits of data per page table entry; or I could sequentially read the page table. But let's not overcomplicate things yet.
4K pages are also quite common if you look at other people's similar systems, like André's. He used a dedicated MMU chip that outputs 12 bits rather than 8, which seems handy, but it's discontinued. He used the higher bits to store access rights. Expanding to 16 bits per PT entry is very appealing now.
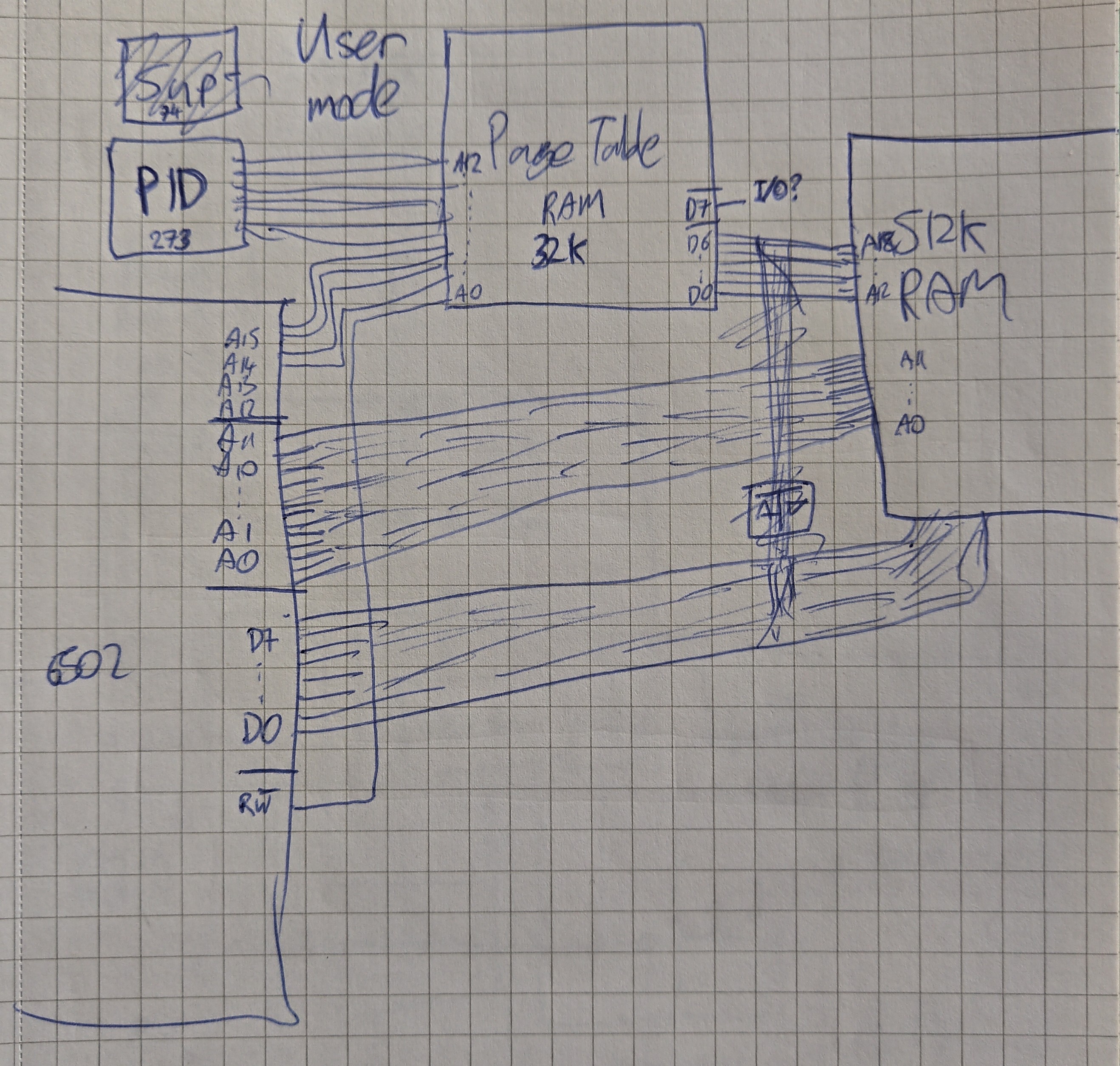
Next up, I sketched how the system should look to a user process. It's fairly simple:
![]()
I wanted the whole 16-bit address space to be usable, I didn't want some of it wasted on ROM or I/O mappings that the user process isn't allowed to use anyway. That should all be opt-in.
Note also the '273 register in the to left - this stores the process ID (PID), which also feeds into the page table (PT).
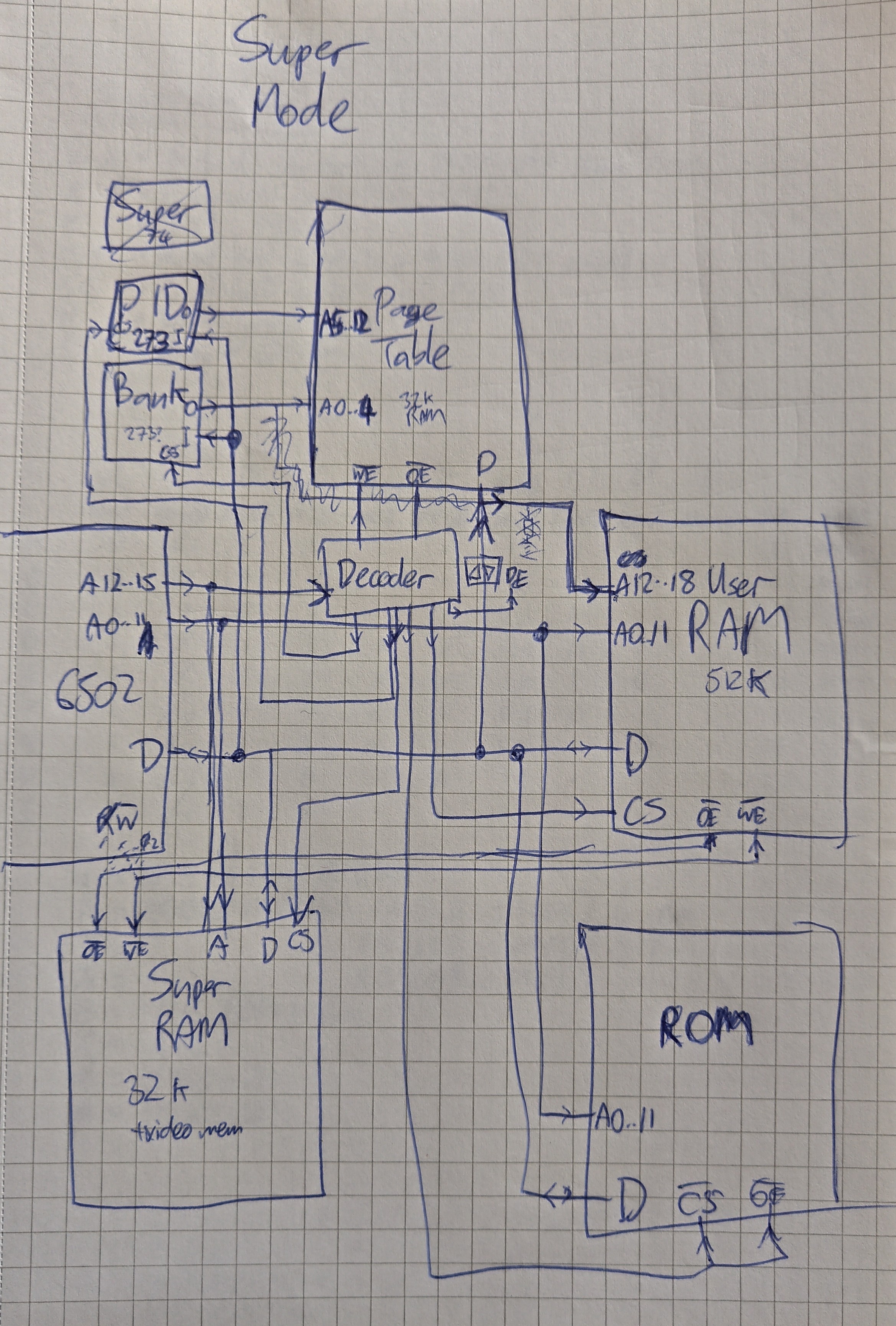
The user mode process doesn't have access to read our write either the PID or the PT entries. Ignore the link to the data bus on the right hand side, I started adding the links needed in supervisor mode, but then decided to draw a separate diagram for that:
![]()
So... wow, this got complicated fast.
In the lower right there's a ROM, which is where the supervisor code lives. There also an extra RAM in the lower left. This is maybe optional... But I'll likely be implementing this in a system that uses shared RAM for video memory, and that's where that lives at the moment. It could also be where the supervisor stores all it's own data. In that sense, from the supervisor's perspective, the whole thing is more like a regular computer but with user RAM and the page table added in like peripherals. I thought this was an interesting way to look at it.
The supervisor needs to be able to write to the user RAM anyway, so to do that it needs to also be able to send arbitrary inputs to the PT. It can't just use A12-A15 because it's using those for regular address decoding. So there's an extra "bank" register which it can program to control the PT.
In order to update the PT, there's a link from the data bus to the PT output (it's data pins) with a bus transceiver to control whether the data bus or PT is outputting. The data bus is also wired to the PID and Bank registers, and a decoder decides which of these things should be active at any time based mostly on A12-A15.
I would have liked the decoder to be driven based on the PT's output. This may be necessary in the end, to allow user processes to access more than just user RAM. However, writing to the PT itself is something that depends on that decoding, and we can't read from and write to the PT simultaneously, as it's not dual-ported. Maybe it should be, or maybe I can access it twice per clock, latching the write and performing it when phi2 goes low again. Something to figure out in the future!
This sketch is obviously not complete, but it's a good start. Next I thought a bit about the decoder logic, but I'll post a separate update about that...
-
Inspiration and existing projects
09/20/2020 at 18:36 • 0 commentsI wanted to call out where some of the inspiration to do this came from, and also point out another project here on Hackaday that's touched on the topic.
Inspiration - GeckOS by André Fachat
The main inspiration for me was about a year ago when I saw the YouTube video that I've linked at the end of this log entry. It's a presentation by Glenn Holmer from a retro computing convention, in which he demonstrates a multitasking OS running on a 6502-based Commodore 64.
The OS in question is called GeckOS, and it's by André Fachat. Any time you search for things like this on a 6502 you're likely to end up on André's web site! He was trailblazing this kind of thing back in the 90s, on both the software and the hardware side.
My first thought when I saw this presentation was that there are some really simple things you could do in the hardware to make this work a lot better. And of course that's exactly what André did - it's not shown in this presentation, as the presenter is only using a C64, but André was building his own monster of a homebrew computer, with 6502s and other processors all slotting together, and at least at some stages he was using quite a versatile MMU.
André's system did have some elements of memory protection, including quite advanced features such as virtual memory (using page faults to page from storage), and read-only and no-execute pages. I'm not sure whether he implemented a privilege system though - from his designs it looks like untrusted code could break out of its sandbox.
Existing projects
I also wanted to point out this other project here on Hackaday that has some similar needs. I'm not sure if it's still in development, it was a couple of years ago: https://hackaday.io/project/98837-8-bit-portable-internet-enabled-computer
They are thinking along similar lines, in any case, and of course, referring back to André's excellent work as well.
If you're aware of any other interesting attempts at this, please do let me know. I'll probably still forge my own path, as this is all about the journey for me, but I'd still love to check them out!
-
Why make a protected memory enviroment on a 6502 breadboard computer?
09/20/2020 at 17:33 • 0 commentsOver the years I've found my homebrew 6502 computer to be an incredibly valuable way to experiment with and understand computer hardware concepts. I've learned about clock signals, memory, buses, address decoding, and memory banking; I've built my own video and audio output circuits, and keyboards that connect straight to the bus; I've experimented with the 6522 VIA's timers and shift register, and wired peripherals up to that. I've also learned a lot about digital electronics, how and why things work, and what not to do!
A lot of what I've done has been driven by understanding how the BBC Micro that I used in the 80s worked - but I'm also interested in other concepts that were less relevant on early 80s microcomputers.
Protected memory systems had existed long before the 6502 was produced, but were only relevant on much larger systems, which had multiple concurrent users and enforcing privacy was important. In later decades, running partially-trusted software became so important that computer security became relevant for home users as well - but for the general applications of a 6502, especially with the memory constraints of the age, it was never very relevant.
Nevertheless, even if these concepts aren't useful on small 8-bit computers, they're still interesting and educational to experiment with. The simple architecture and lack of advanced features built in to the 6502 itself mean that you have to create the more complex systems yourself - and this means you have the freedom to try doing it in ways that make sense to you, and discover the pros and cons yourself, without being forced to do it in the way a more advanced CPU requires you to.
I don't particularly expect to make a useful protected memory environment on my 6502; but I do hope to make something simple, elegant, and understandable, and learn a lot in the process!
Protected-memory multitasking for 6502 computer
Designing a memory controller and OS interface to support multitasking on a 6502 with strictly-protected memory