Current Hardware:
- 1x RPi 4 w/ 2GB RAM
- management machine
- influxdb, apcupsd, apt-cacher
- 3x RPi 4 w/ 4GB RAM
- 1x ceph mon/mgr/mds per RPi
- 18x RPi 4 w/ 8GB RAM
- 2 ceph osds per RPi
- 2x Seagate 2TB USB 3.0 HDD per RPi
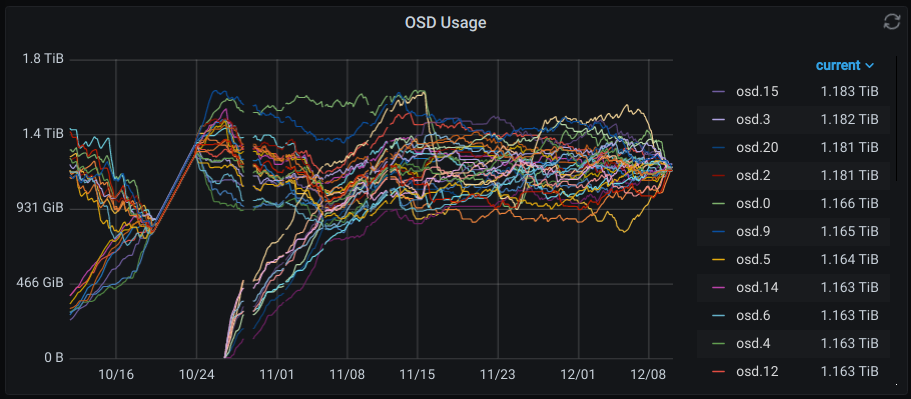
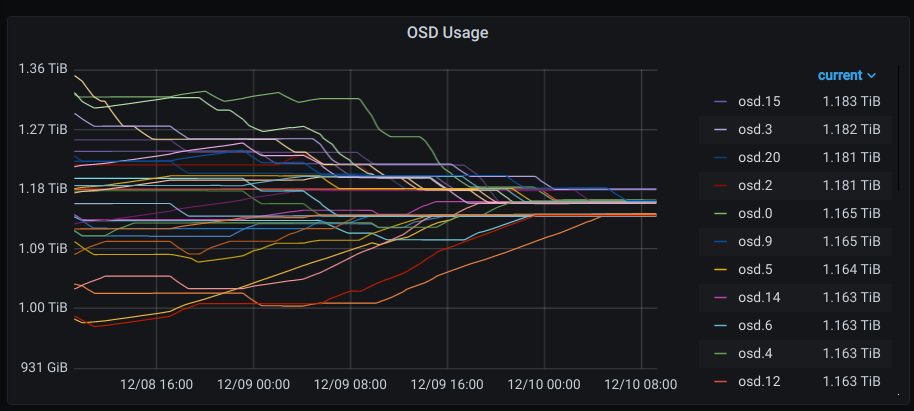
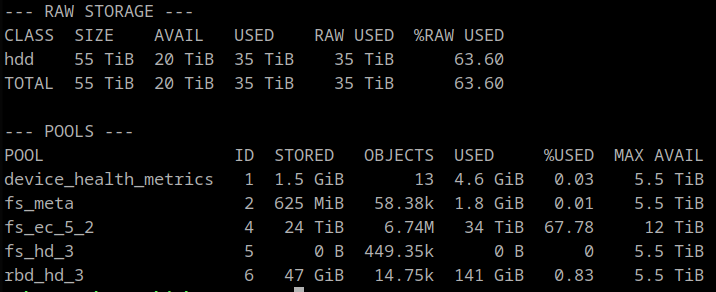
Current Total Raw Capacity: 65 TiB
The RPi's are all housed in a nine drawer cabinet with rear exhaust fans. Each drawer has an independent 5V 10A power supply. There is a 48-port network switch in the rear of the cabinet to provide the necessary network fabric.
The HDDs are double-stacked five wide to fit 10 HDDs in each drawer along with five RPi 4's. A 2" x 7" x 1/8" aluminum bar is sandwiched between the drives for heat dissipation. Each drawer has a custom 5-port USB power fanout board to power the RPi's. The RPi's have the USB PMIC bypassed with a jumper wire to power the HDDs since the 1.2A current limit is insufficient to spin up both drives.
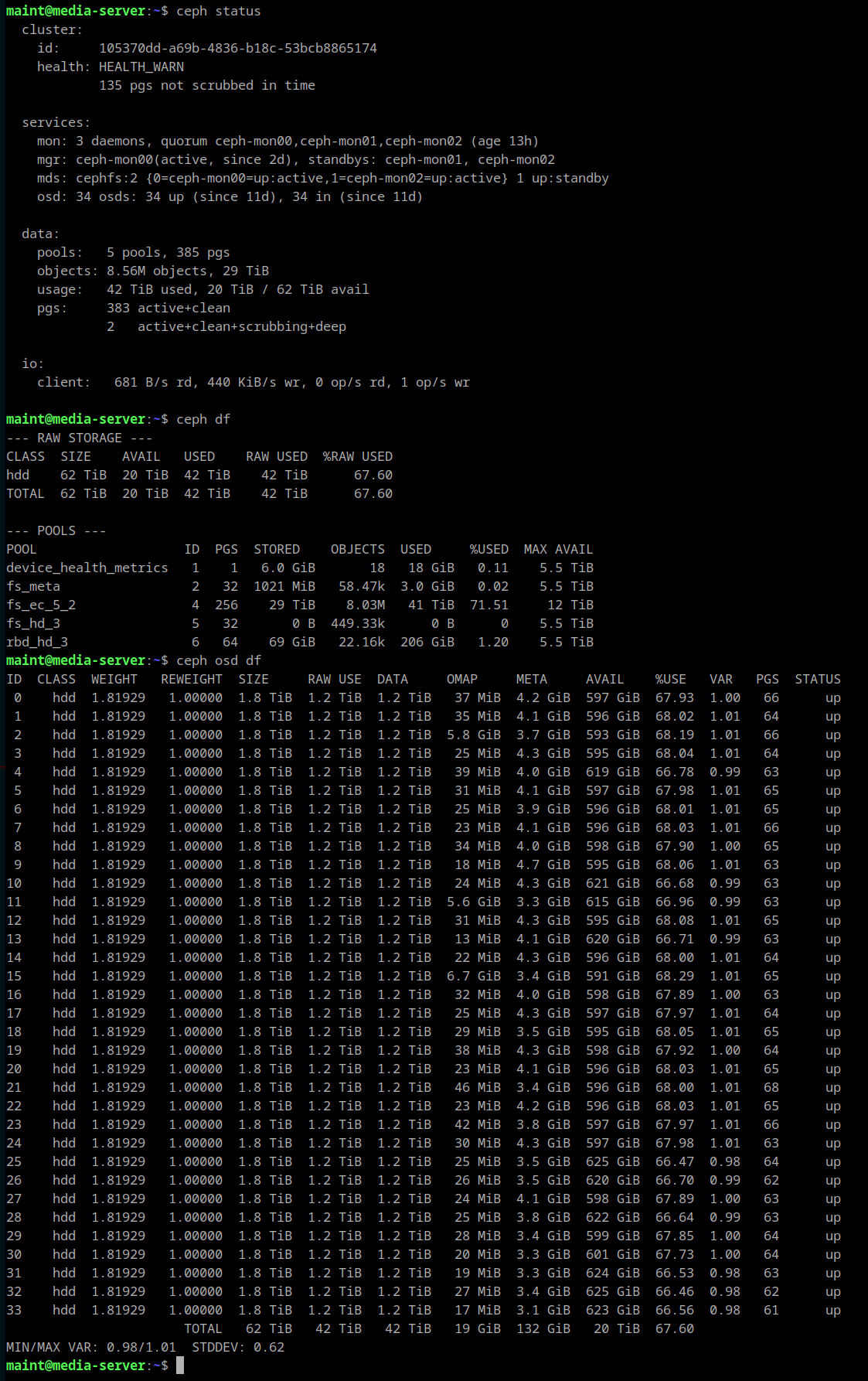
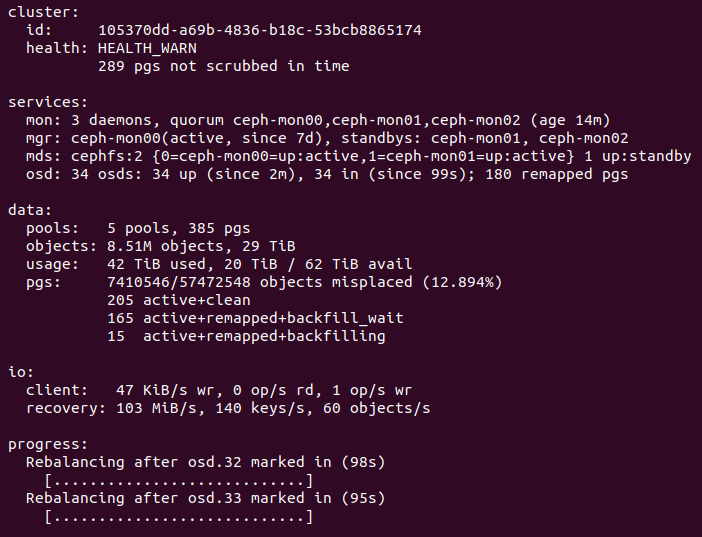

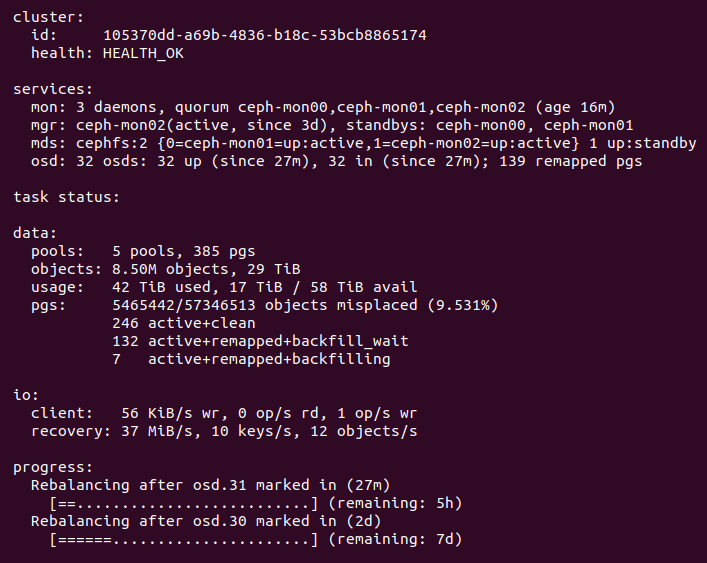
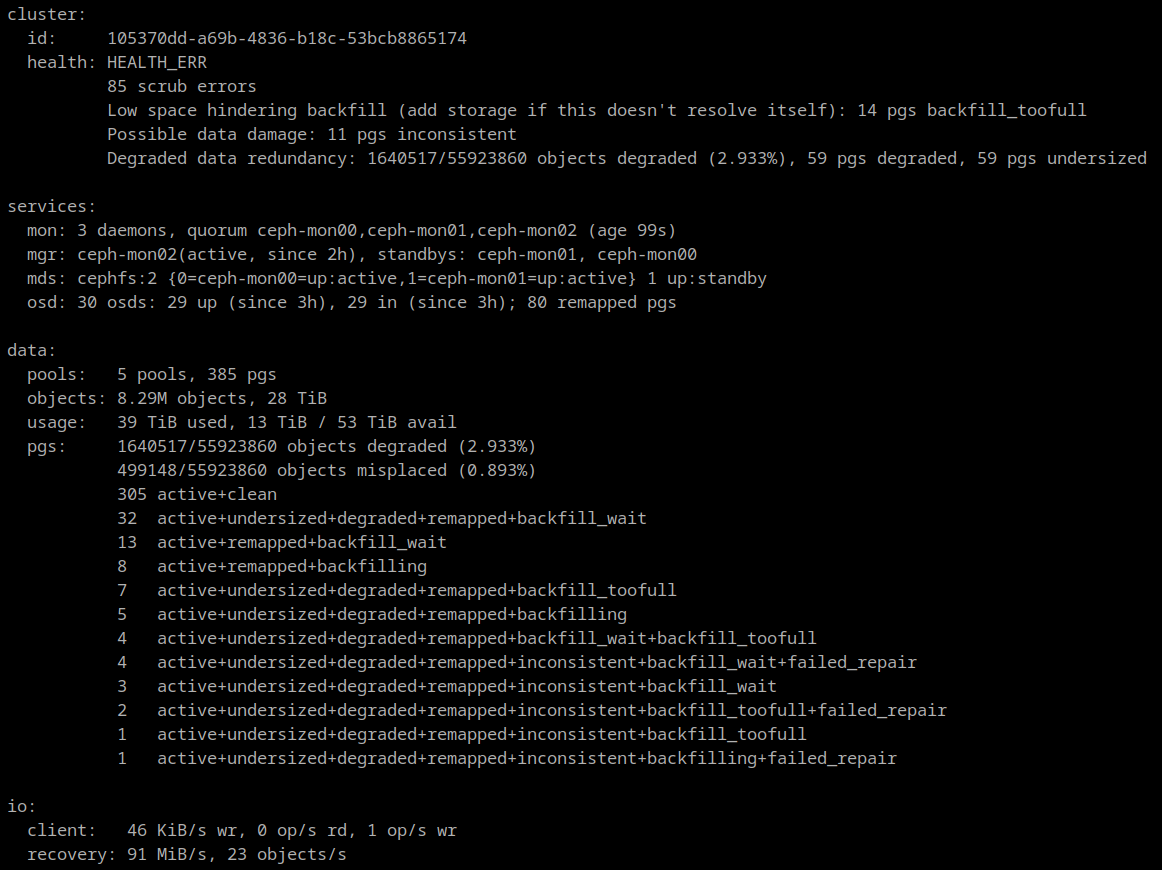
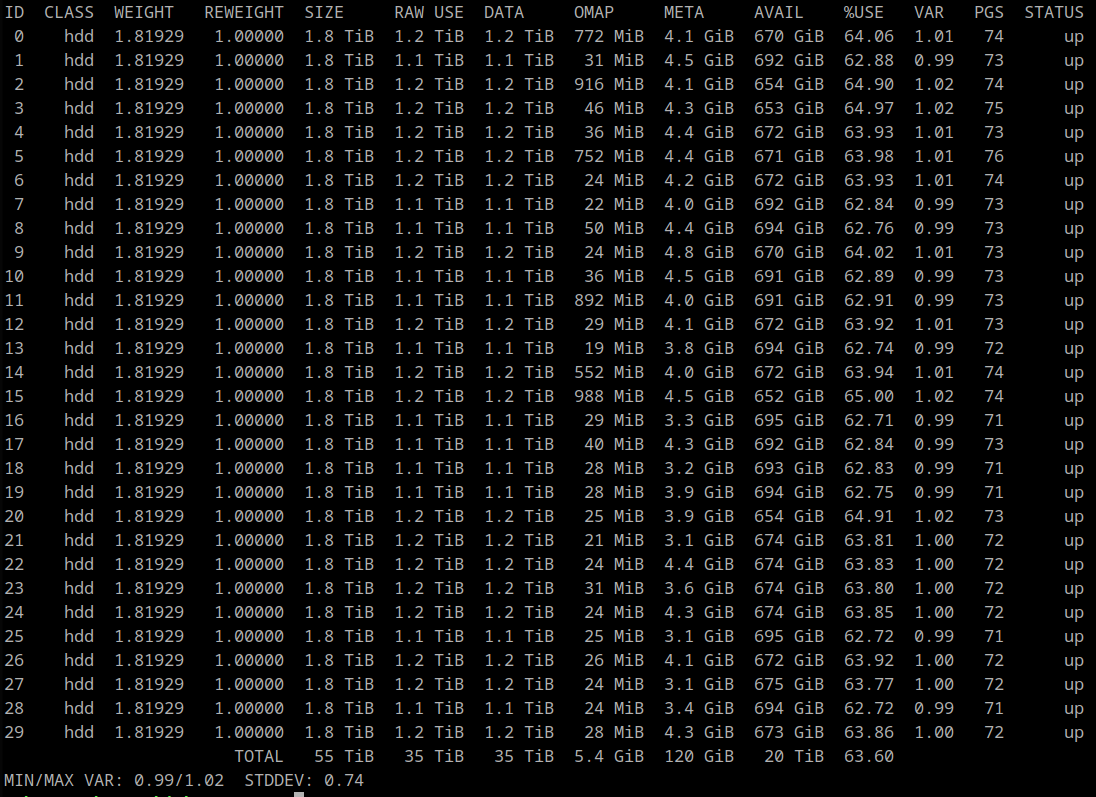
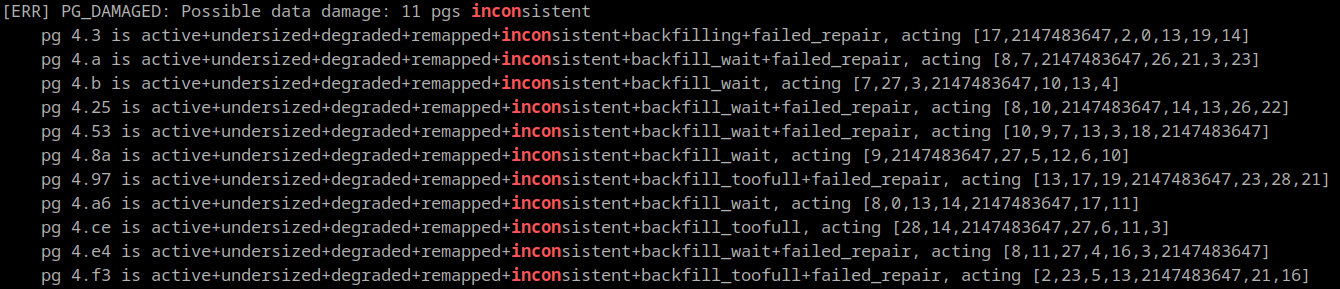 The inconsistent PGs all have a single OSD in common: 2147483647 (formerly identified as 25)
The inconsistent PGs all have a single OSD in common: 2147483647 (formerly identified as 25)
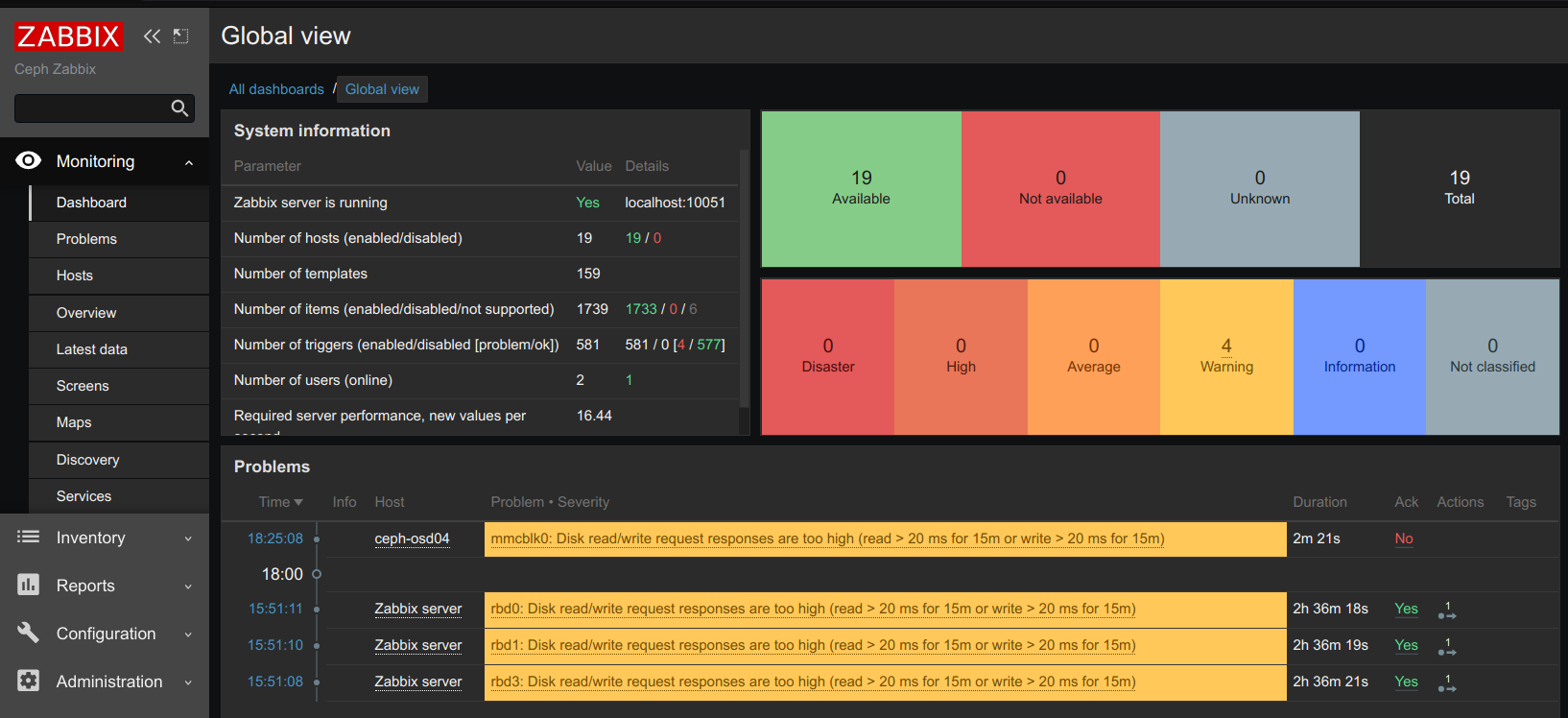



 Ken Yap
Ken Yap
 Clara Hobbs
Clara Hobbs

20TB raw capacity per shelf is great. How are you finding heat? It would be very cool to wire in two temperature probes to your management Pi's GPIO and monitor temperature by the exhausts.
Have you found single gigabit per node to become a bottleneck?
Awesome project, makes me very jealous.