 Dylan Brophy
Dylan BrophyNo Cache - multiple memory banks instead
Why? I figured out that cache takes more FPGA resources and likely wouldn't really help with speed as much as just having specialized types of memory.
Although all 3 of the memory blocks available to the main processor are in the same address space, they are optimized for different things.
There is DMEM, IMEM, and RAM. This is basically just data cache, instruction cache, and RAM - except the first two are actually their own memory.
Parallelism
Parallel mathematical operations are achieved through 64 ALUs that are essentially separate from the main processor. These ALUs are more like a coprocessor with DMA than an internal part of the processor.
Each ALU has a 32 bit accumulator. They can do floating point and integer addition, subtraction, and multiplication. I only added an inverse function for floating point. And of course integer bitwise and shift operations are supported.
The ALUs have their own memory inside the FPGA that can exchange every ALUs 32-bit data in a single clock cycle. The data bus is 2048 bits. I have to say, I like that large number. This is by far my biggest FPGA design ever, so it's fun. Except for the synthesis and implementation.... which takes 20 minutes.



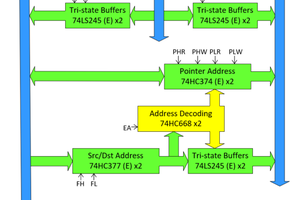

 Erik Piehl
Erik Piehl
 Marcel van Kervinck
Marcel van Kervinck
I'm very curious !