 ziggurat29
ziggurat29My home server crashed for the umpteenth time, so I am going to try to make good from bad by using this as an opportunity to re-engineer the server using the modern container approach and a Raspberry Pi 3 as the host platform.
'Containers' are a thing somewhere between a chroot jail, and a fully virtualized system. There's more isolation than a chroot jail (e.g. networking), and they're lighter in resources than a full VM (e.g. the OS and simulating a standalone processor). This allows you to package an application and it's dependencies as a modular unit, decoupled from others.
Aside from the management benefit, containerization is a key dependency for modern clustering techniques (though in this project I will not be exploring clustering -- just the containerization).
This has taken me some time to do, so I thought it might be of use to others in similar circumstances as a leg-up.
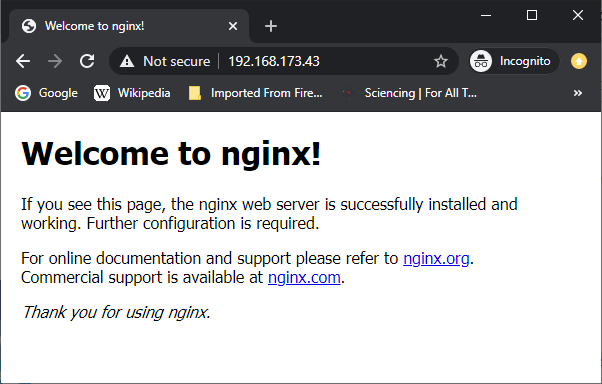



 tlankford01
tlankford01
 lion mclionhead
lion mclionhead
 alusion
alusion
 Luis Ayuso
Luis Ayuso
bruh. unraid.