 Yann Guidon / YGDES
Yann Guidon / YGDESLet's simply start with a simple algorithm pointed to by Wikipedia and that seems to have been widely used :
pseudo-LRU
two-way set associative - one bit
indicates which line of the two has been reference more recently
four-way set associative - three bits
each bit represents one branch point in a binary decision tree; let 1
represent that the left side has been referenced more recently than the
right side, and 0 vice-versa
are all 4 lines valid?
/ \
yes no, use an invalid line
|
|
|
bit_0 == 0? state | replace ref to | next state
/ \ ------+-------- -------+-----------
y n 00x | line_0 line_0 | 11_
/ \ 01x | line_1 line_1 | 10_
bit_1 == 0? bit_2 == 0? 1x0 | line_2 line_2 | 0_1
/ \ / \ 1x1 | line_3 line_3 | 0_0
y n y n
/ \ / \ ('x' means ('_' means unchanged)
line_0 line_1 line_2 line_3 don't care)
(see Figure 3-7, p. 3-18, in Intel Embedded Pentium Processor Family Dev.
Manual, 1998, http://www.intel.com/design/intarch/manuals/273204.htm)
note that there is a 6-bit encoding for true LRU for four-way set associative
bit 0: bank[1] more recently used than bank[0]
bit 1: bank[2] more recently used than bank[0]
bit 2: bank[2] more recently used than bank[1]
bit 3: bank[3] more recently used than bank[0]
bit 4: bank[3] more recently used than bank[1]
bit 5: bank[3] more recently used than bank[2]
this results in 24 valid bit patterns within the 64 possible bit patterns
(4! possible valid traces for bank references)
e.g., a trace of 0 1 2 3, where 0 is LRU and 3 is MRU, is encoded as 111111
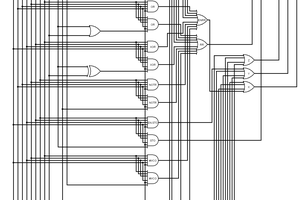
you can implement a state machine with a 256x6 ROM (6-bit state encoding
appended with a 2-bit bank reference input will yield a new 6-bit state),
and you can implement an LRU bank indicator with a 64x2 ROMOf course the 1998 link on the Intel website has long been broken but this gives us a first approximation :
- 2-sets uses 1 bit. This can't be more simple or easy and the logic is truly minimal. Go for it everytime you can :-)
- 4-sets is more complex. There are only 3 bits if pseudo-LRU is good enough for you, but true LRU now has to be distinguished and grows as N!, so you'll need 6 bits and a 256-bits ROM.
How can one build larger systems ?
Wikipedia lists many strategies but it is desirable to get "most" of the true-LRU benefits without the size, time and costs.


 Mike Szczys
Mike Szczys

 Dave Collins
Dave Collins
https://arxiv.org/abs/1512.00727 :
[Submitted on 2 Dec 2015 , last revised 3 Dec 2015 (this version, v2)]
TinyLFU: A Highly Efficient Cache Admission Policy
Gil Einziger, Roy Friedman, Ben Manes
This paper proposes to use a frequency based cache admission policy in order to boost the effectiveness of caches subject to skewed access distributions. Given a newly accessed item and an eviction candidate from the cache, our scheme decides, based on the recent access history, whether it is worth admitting the new item into the cache at the expense of the eviction candidate.
Realizing this concept is enabled through a novel approximate LFU structure called TinyLFU, which maintains an approximate representation of the access frequency of a large sample of recently accessed items. TinyLFU is very compact and light-weight as it builds upon Bloom filter theory.
We study the properties of TinyLFU through simulations of both synthetic workloads as well as multiple real traces from several sources. These simulations demonstrate the performance boost obtained by enhancing various replacement policies with the TinyLFU eviction policy. Also, a new combined replacement and eviction policy scheme nicknamed W-TinyLFU is presented. W-TinyLFU is demonstrated to obtain equal or better hit-ratios than other state of the art replacement policies on these traces. It is the only scheme to obtain such good results on all traces.
A much earlier and shorter version of this work appeared in the Euromicro PDP 2014 conference