 Eric Hertz
Eric Hertzwhile [ 1 ]
do
read -n 1 byte < /dev/ttyUSB0
...
done
SHOULD BE
while [ 1 ]
do
read -n 1 byte
...
done < /dev/ttyUSB0
FRIGGIN DAYS
...
Friggin code worked great. Friggin blacklink powered fine. Friggin weird voltages on PL2303 and HIN213 work fine. Friggin inverted-logic for RS-232 levels worked fine. Friggin bypassing RS232 levels worked fine. Friggin current-draw from a handshake line worked fine. Friggin 5V source creating 2.5V highs right at the HIN213' threshold worked fine. Friggin 8V battery worked fine. I'm sure I'm forgetting a friggin lot of friggin things I friggin tried.
Friggin 9600baud worked fine. Friggin 300 baud worked fine. Friggin 19200 baud had one measly bit error. Looks like the only test i tried that wouldn't've worked was 75 baud.
Put the friggin' pipe on the friggin' while loop, not on friggin read.
...
This explains it pretty clearly /for a file/: https://stackoverflow.com/questions/58829941/i-o-redirection-in-a-while-loop
And, I think, were I writing it for a file, I'd've thought of it like that... I've certainly, in the past /written/ it like that, for files and strings, using the <<< redirector...
So why would I've expected differently with a serial port? The device node is designed to look like a file. Heh!
Now, I guess, this again is where stty might play a role... and maybe IFS?
Unlike a file, the serial port device node isn't static. If you read the first byte in that "file" it will be different each time. Right? And you can't exactly seek the twentieth byte, then go back and seek the first. Right?
So, I guess, I thought the serial port was different.
But, now that I think about it, redirection of stdin is a bit more like reading a serial port than reading a file... stdin isn't seekable, either. Right?
Maybe, maybe, you could treat a "line" as seekable, as though each /line/ is a temporary file... but, mostly, one reads that entire line in one go, then processes its bytes/words/whatever afterwards.
So, again, I guess this may be where stty and IFS may play a role. When one accesses stdin for a read, or redirects a file or serial port to stdin for a read, what exactly happens?
A normal 'read' call would halt the script while the user typed... until they hit Enter, (IFS, right?). Then the 'read' would be solely responsible for processing /all/ of what the user typed in that time. Another call to 'read', then, wouldn't process whatever was left-over from the last read, it would wait for an entirely new line to be entered.
So, probably, with default stty settings on a serial port, it would do the same. Duh.
It gets confusing with read -n1, because, now I recall doing similar in the past, it doesn't follow its normal rules.
Normally read reads each word (separated by space) into each variable name supplied, e.g:
$ read var1 var2 var3
Will store three sequential words into the three variables. BUT, it says it /also/ stores anything remaining in the last var... So, if you enter four words, var3 will contain the third AND fourth words.
OK. So better to write it:
$ read var1 var2 var3 varExcess
And, just don't use varExcess if you don't care.
Now, logically, from that explanation, say we just wanted to grab one byte:
$ read -n1 char1 excess
Sould put the first byte into char1, and any remaining bytes (up to Enter, per IFS, right?) into excess...
But, I don't see that happening. The variable 'excess' is always empty.
Maybe it's to do with my initial testing, which only sent one character every half-second... But, per default stty settings, it should've waited at that read until it received Enter... which, of course, my test never sent. BUT it /didn't/ wait for Enter, or else it'd've never finished that first 'read' and would've appeared frozen.
So /somewhere/ it was sorta set up the way I intended... so, then, it would seem maybe an stty setting told 'read' it was done whenever the buffer was empty. Then, read should've thrown whatever it got after that first byte into 'excess'. But, again, it didn't. At least in that test, which may well've been the result of sending characters so slowly that the entire buffer was read each time, containing only one character each time.
(Wherein, I'm working on past memories, vague recollections of having used '-n1' and having similar results even with stdin, excess was always empty, right? I really should do a real test of this theory... but... not... right... now... hey wait! I'm thumbtyping on a friggin supercomputer, it even runs bash! BRB. (Reminder to self, hard-learned: superThumbCompy does /not/ reliably store text entry in websites when switching tabs or apps)
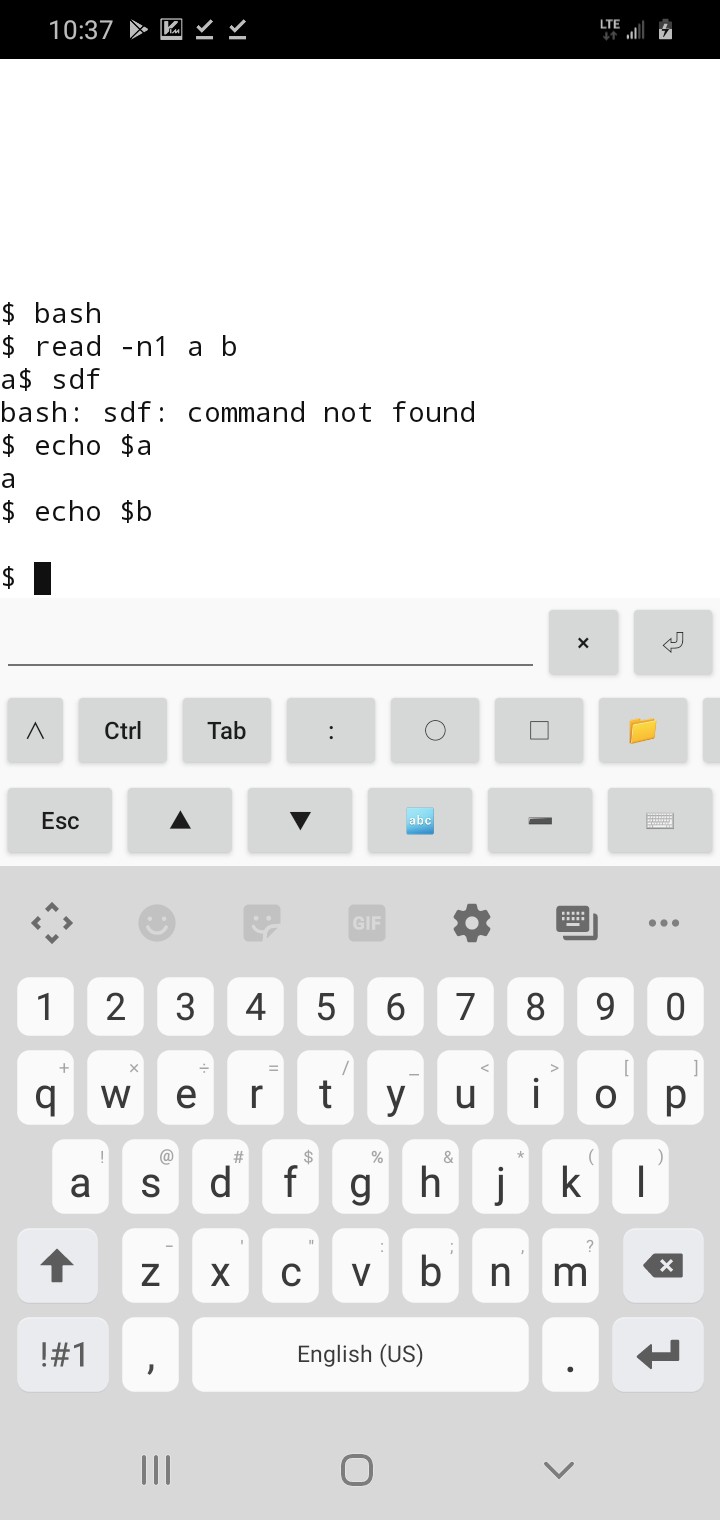
How friggin cool is that? (BTW, the trick is, install droidVIM, then ':sh')
so... it looks like I was right... top that off, it actually exits immediately after getting that byte, didn't even wait for enter.
So, then... I dunno what to think. Seems to me it's a design-flaw to empty the entire buffer when only one character is read from it. And, the manpage doesn't explain it, either.
So, now, which buffer are we talking about, here? The serial port chip has its own buffer. A "real" serial port would be readable by the driver one byte at a time, if the driver implemented it. But, it's somewhat logical to think there's really no reason, in these days of huge RAMs, for the driver/OS /not/ to grab everything in that buffer, to be stored in an OS/driver-side buffer. In fact, it's entirely likely the driver does-so periodically in the background /regardless/ of whether any software (i.e. 'read') requests data from the port... wherein, almost certainly, the driver and/or [and even more likely] the OS has yet another buffer... this one likely still containing raw data... not processed into "words" nor split up into "lines", nor even yet manipulated by stty settings (e.g. converting an input NewLine byte into BOTH a NewLine AND CarriageReturn). In fact, my guess is that stuff is handled during the software's request for data from that buffer.
Now, 'read' requested a single byte from that device-node. I can buy that it got it through some sort of stty-process to convert newlines, etc. I can buy that BASH wants to do its own processing of it (e.g. word-splitting, looking for IFS, etc.). Yet, in that quick-test (screenshot) bash clearly only requested one byte from stdin before exitting 'read'... AND it didn't fill in the excess to variable b, as the manpage would have me believe, if it'd instead asked for (or otherwise expects it might receive) a 'line' (i.e. the buffer contents)... so, somewhere, it would seem, buffer data is being flat-out discarded. That... doesn't... seem... right... for nearly /any/ purpose... without being explicitly told to do-so, or explicitly explained in a manpage.
Now, somewhere therein, one might suggest that, well, say some talkative serial device was always talking to the serial port, regardless of whether the software to read it was ever even executed... should that buffer be 100MB?
I suppose it's an important question...
What /should/ happen in that case? Every time the 'file' is closed, it clears the buffer? Only begins filling it if the 'file' is open? Hmmm...
I /suppose/ therein lies the answer... it's not that bash did anything unusual in reading the entire buffer, then discarding the 'excess' despite the manpage saying, essentially, that the rest would be stored in the last variable... i guess the wording should be clear from the description of -n1 that only one byte is grabbed, and the excess isn't even looked-at... That's preferable, anyhow, else even my second test wouldn't've worked and we'd need a second nested while loop to process the excess from the buffer-grab during that first read.
Fine.
So now it's back to the OS, wherein the port's 'file' was opened... and now we have to presume the OS-side buffer was empty, initially, upon opening the 'file', right? But the port chip's buffer /probably/ contains data, much of which has been lost, since its buffer isn't huge... so then we've got to wonder... does opening the port 'file' for read /first/ clear that buffer? Kinda makes sense it would... OTOH, there's really no way of knowing whether /during/ that clearing process a valid byte is coming in... anyhow, fine, that's up to synchronization ala handshaking, or packet headers, etc. And, lacking those, (as in my case) loss of data during that time should probably be expected.
Fine. Open port, lose some data from before it was open, maybe lose some data while it's opening... but now the buffer is ready to go, and no more data should be lost until that port's closed, which, of course, happens immediately after 'read' gets its one byte. OK.
The buffering is only active when the port is open. Bam. So, open it for the /entire/ while-loop, not /just/ during the read... bam.
And the reason it seems different in my screenshot is because 'read' didn't open stdin, it was /already/ open by bash. And 'read' didn't close stdin, bash just took it back... /exactly/ like the while loop would, after 'read' when stdin was redirected for the entirety of the while loop, instead of just for read.
OK.
Buffers disabled/cleared unless/until port is open.
Sheesh.
A bit like typing on the keyboard while the computer is off.
Gotcha.
Turning it on for a moment, waiting for one keystroke, displaying it, then turning it off again...
OK... I GET IT!
Nope... nope I don't...
If it was stdin... and it was a while loop... and there was a sleep of 30 seconds before 'read'... and someone typed during those 30 seconds... then 'read' would get the first byte typed during those 30 seconds, right?
BRB...
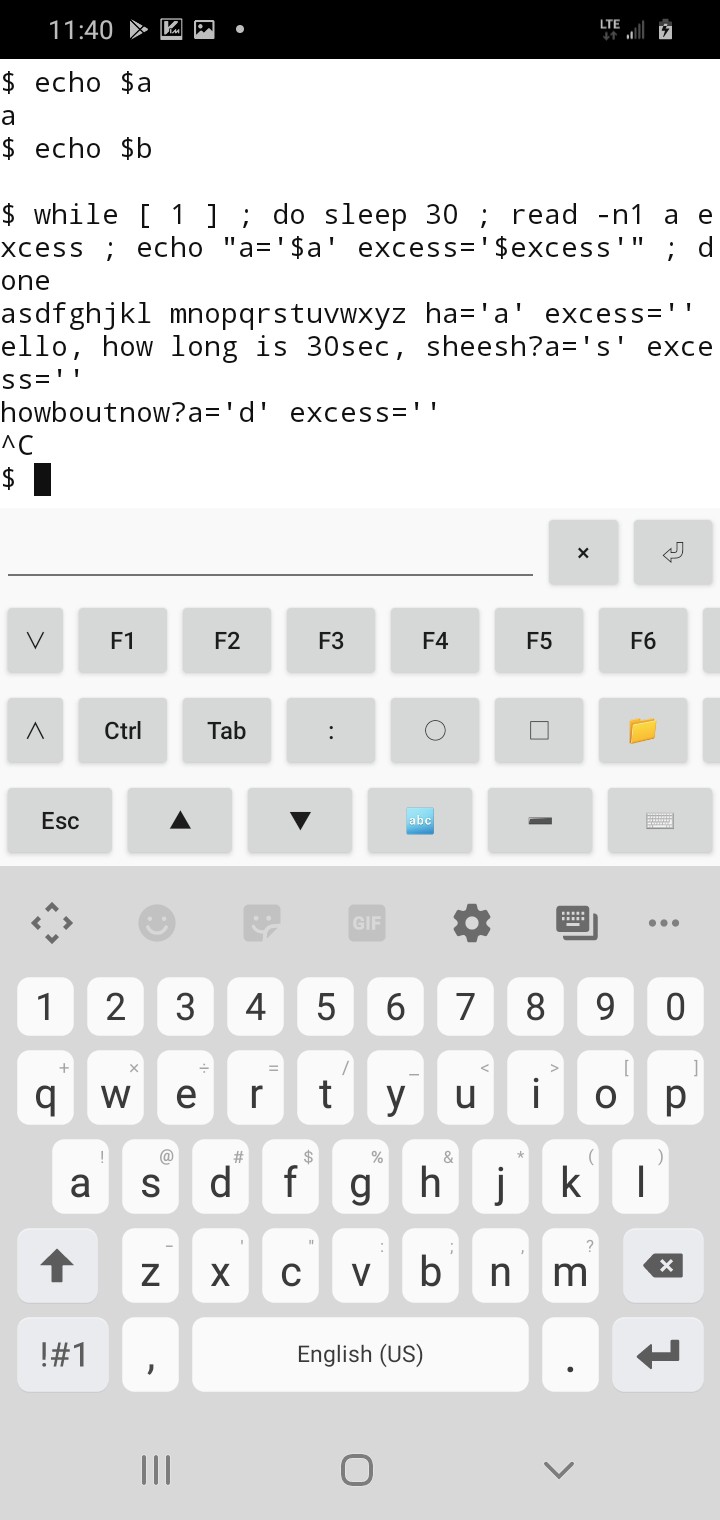
(How cool is that? And I once thought "smart phones" to be little more than dumb toys)
Right... so, stdin was already open... nothing grabbed the data (except screen printout, which I guess is another matter entirely) until the read. Read grabbed a byte from the beginning of the buffer. Makes sense.
But, no... no it doesn't...
Oy... I could go into why, but... I've gone this far, and the end result is the same... this be how it werkz, so figure out how to remember it: buffer is only buffered when the port 'file' is open, cleared otherwise. Bam.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
That's seriously quirky! Thanks for writing that up.
You have to really love those quirks to use a shell script instead of Ruby or something.
It's funny the way a shell script can make C look so straightforward and obvious. :P :)
Are you sure? yes | no
haha! No kidding !
I often think "oh this is just a quick thing... no sense in compiling it!" And wind up fighting bash quirks for hours, something i coulda done in c in a fraction of the time. But, C's really the only language I know, so it's not really fair for me to say it's easier in general.
On that note, now fighting a different bash quirk writing a really simple checksum... it's three assembly instructions... two simple arithmetic functions, add and xor. But doing it in bash is beating me up... apparently it likes to assume every byte it deals with is text, and even /changes/ bytes it reads based on the machine's language settings, and such...?! SHEESH. I thought a byte was a byte!
Ahhh... /ruby/panther... I get it now!
Are you sure? yes | no
One nice thing about Ruby is that it wraps all the C stdlib functions and they work as expected, and you can use mostly C-style syntax, so it is really convenient when C is your other language
Are you sure? yes | no
that, ruby, sounds promising... i thought about trying c-shells, but really never have in all this time. I guess it's because bash is pretty much de-facto, and I try to do stuff that will run on different systems without needing to download other tools first. My phone even has bash! Heh!
Kinda surprising things like c-shells, or ruby, aren't more commonplace!
Are you sure? yes | no
Yeah, I used to use csh but I switched to bash because I got tired of rewriting scripts for shell utilities and things. And that was back when I was stuck with Perl for scripting. (Ruby didn't have English docs yet) Even using Perl was a time-saver.
Are you sure? yes | no