Aleksa
Aleksa-
FPGA Module: Extreme Artix Optimization
04/25/2022 at 02:33 • 1 commentIt's been a while since I posted one of these! I've got a few days before another board comes in so I figured I'd post a log before I disappear into my lab once again. Hardware-wise, we left off after the main board was finished. This board required a third-party FPGA module, which had a beefy 100k logic element Artix-7 part as the star of the show, costarring two x16 DDR3 memory chips.
![]()
But wouldn't it look better if it was all purple? The next step was to build my own FPGA module, tailored specifically to this project.
---------- more ----------First, I did a few optimizations to the FPGA design to make it fit into the 35k logic part. Most of these involved digging around in the PCIe core, changing whatever values I could and seeing if it lowered the logic count without affecting performance.
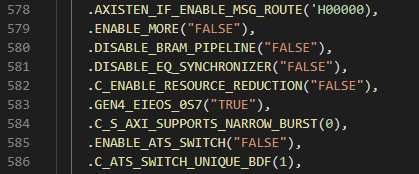
Could it be that easy? Unfortunately not, enabling "resource reduction" only saved a couple hundred LUTs (look-up tables, a finite FPGA resource).
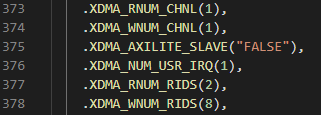
The GUI does not allow you to disable the read DMA channel, so I set it to the minimum number of RIDS I could to try to reduce the logic used by this unused channel. But in the code was an opportunity not just to go to zero RIDs, but to perhaps disable the channel completely! After a very tense compile cycle, it netted a savings of a few thousand LUTs! More importantly, it kept working with the software too (as it never even instantiates the read channel).
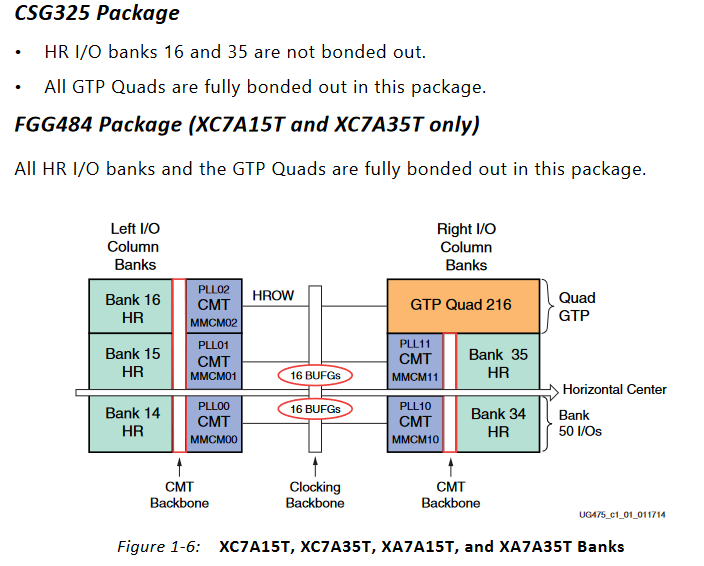
Now that the code fit the smaller (in logic count) part, I decided to use the physically smaller CSG325 package part as well to lower costs even further (the CSG325 is about $10 cheaper through distributors than the FGG484). This came with a few challenges! First, the IO banks for the ADC LVDS lanes (which had to be 2.5V to use internal termination) and the other GPIO (all 3.3V) would have to be merged. I resolved this by using external termination resistors on the LVDS lines to allow the whole bank to be powered by 3.3V.
The next challenge was fitting a x32 wide DDR3L interface on this part. This required two IO banks in the same IO column.
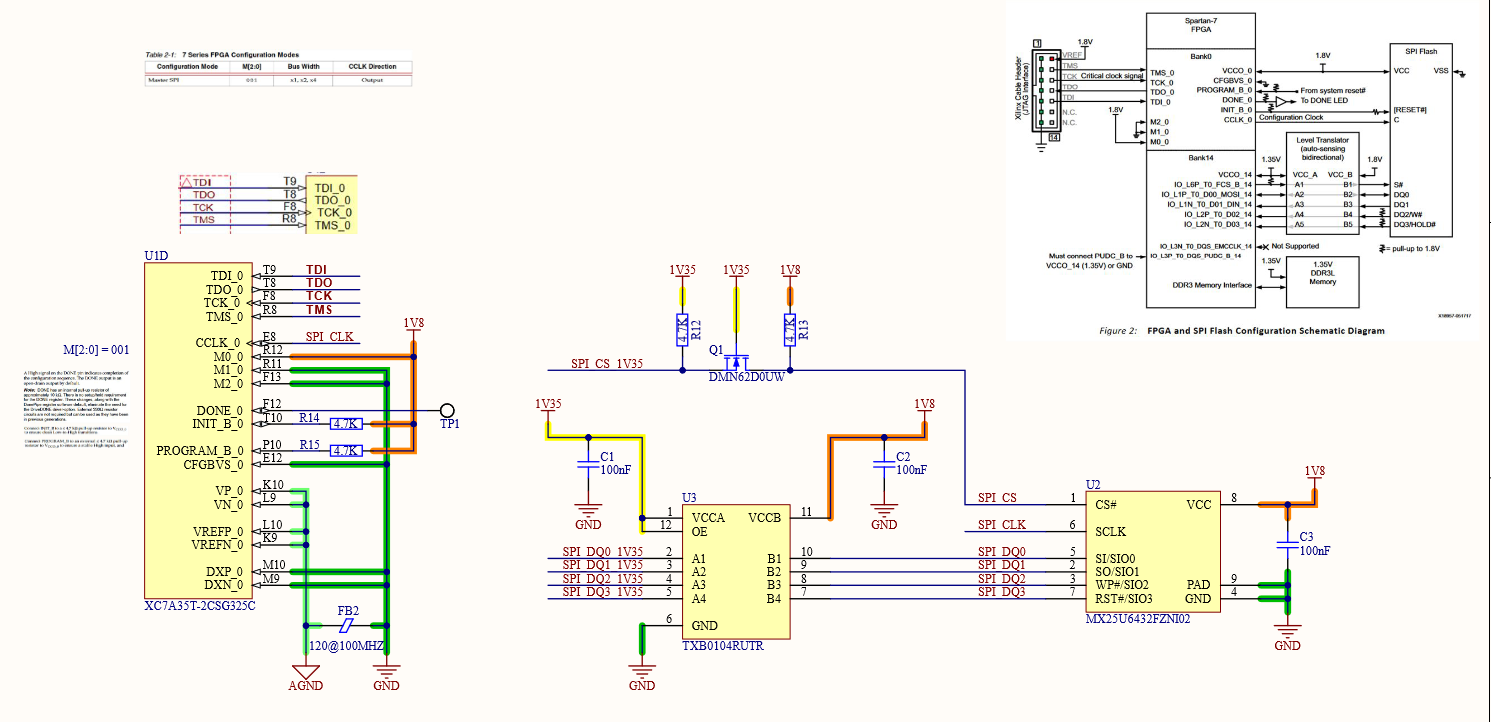
The only two banks that would work were banks 14 and 15, however bank 14 also holds the SPI signals for configuring the part from an external flash memory. There are only five of these signals so it isn't a problem of using too much IO, but again a problem of IO voltage. DDR3L runs at 1.35V and most SPI flash won't run lower than 1.8V, so some sort of level conversion was needed. Luckily enough, someone at Xilinx had thought of this and detailed how to do it in this appnote.
The configuration interface is the one thing you can't reconfigure, got to be careful.
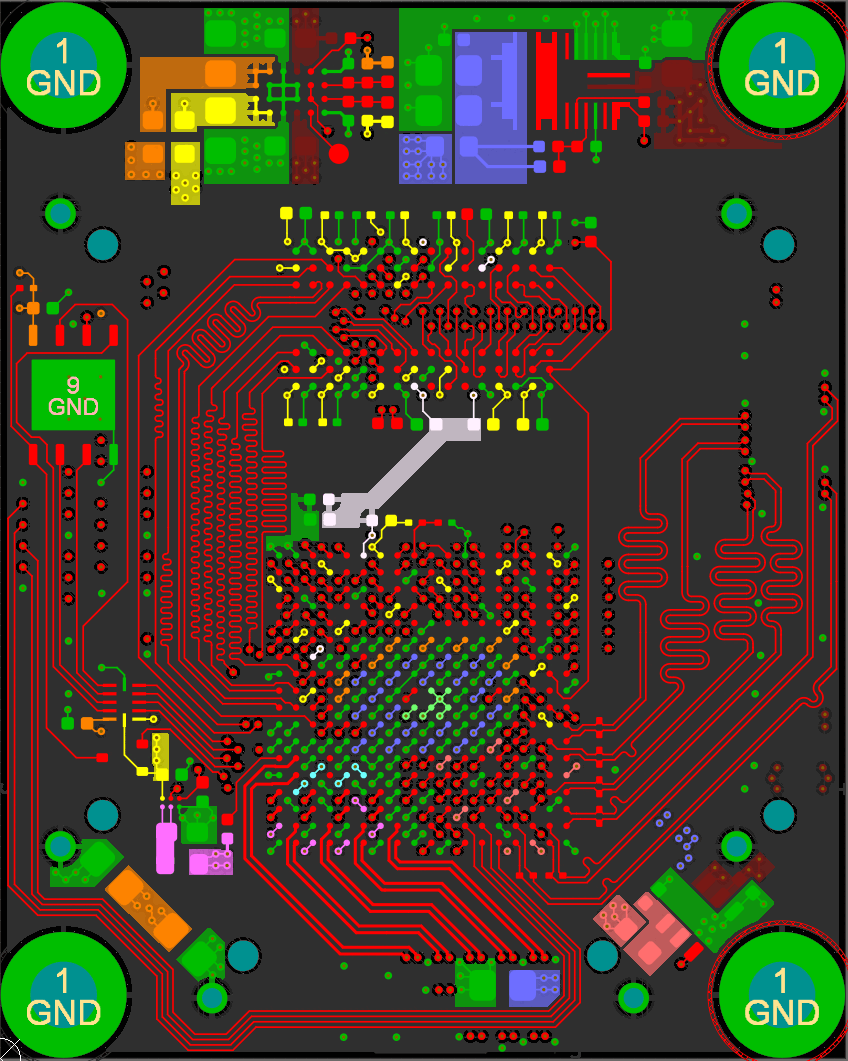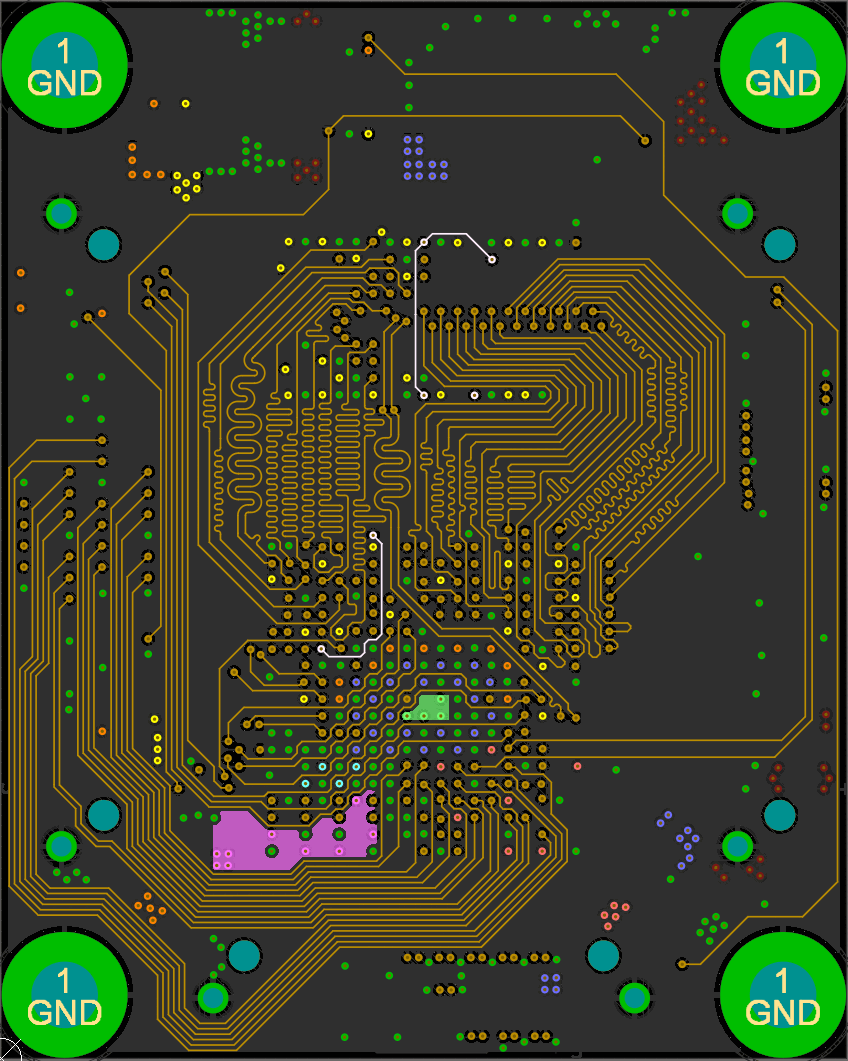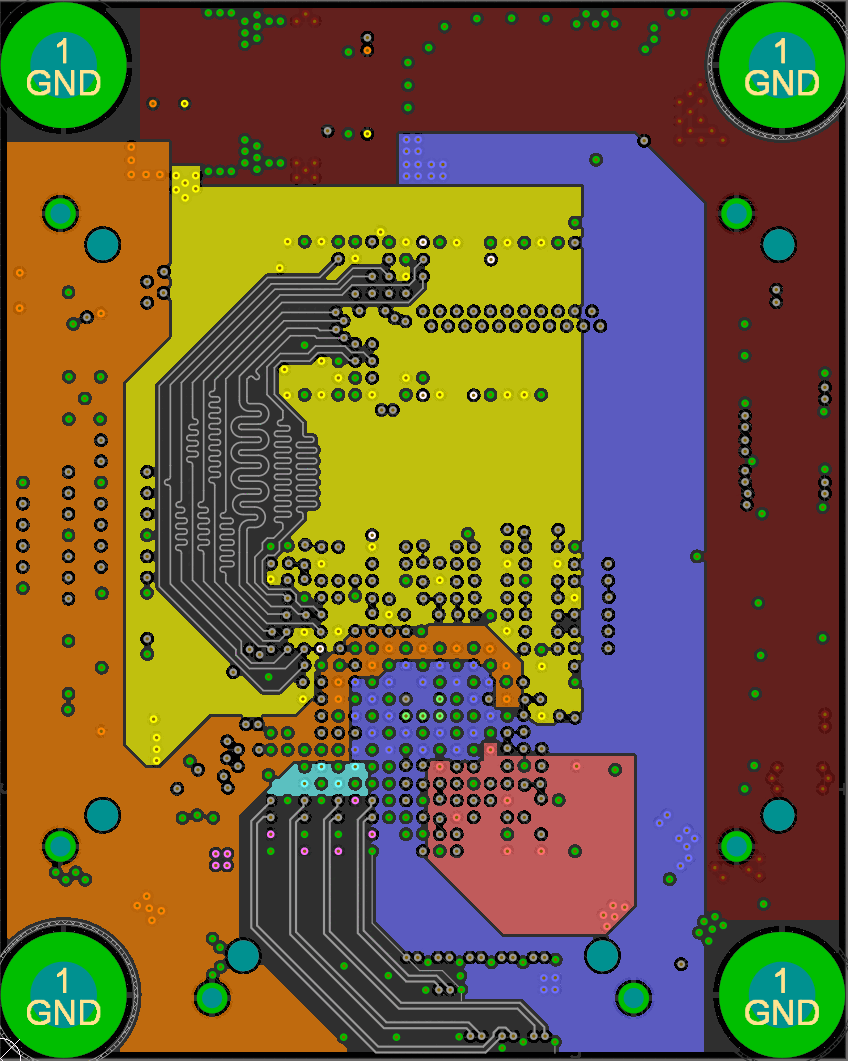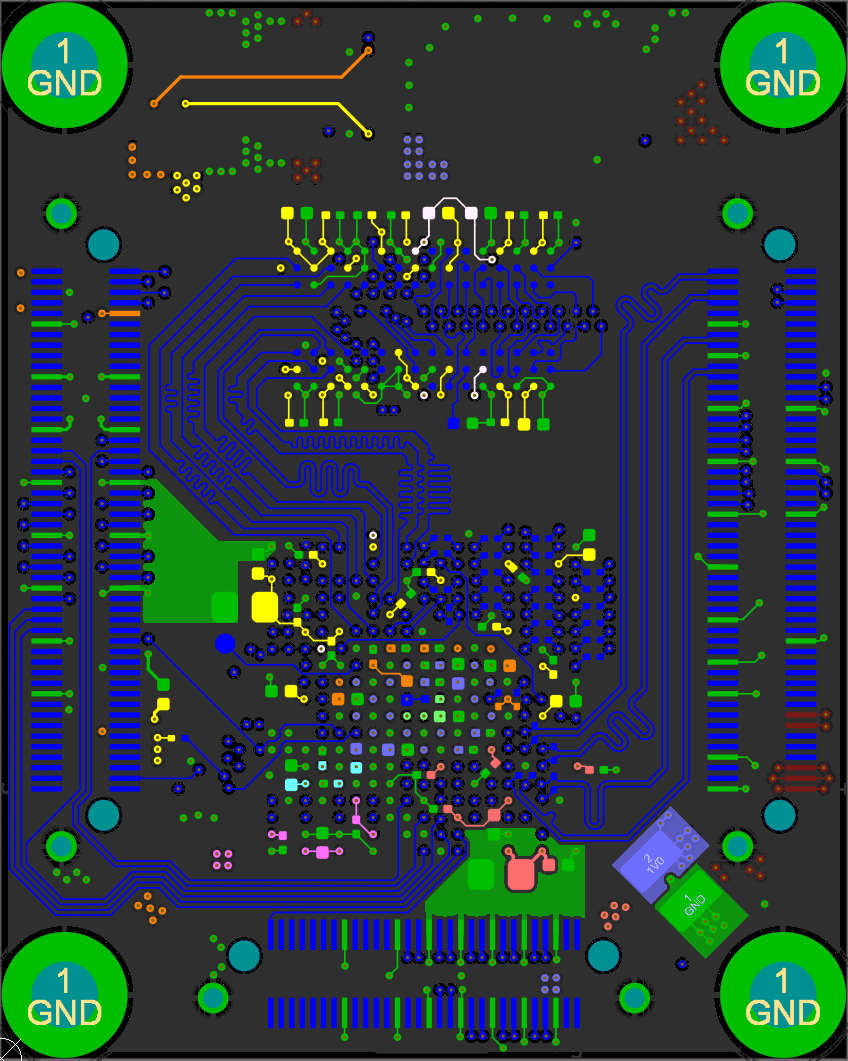
With the schematic sorted out, it was time to layout my first design with a big BGA part and DDR3 memory!
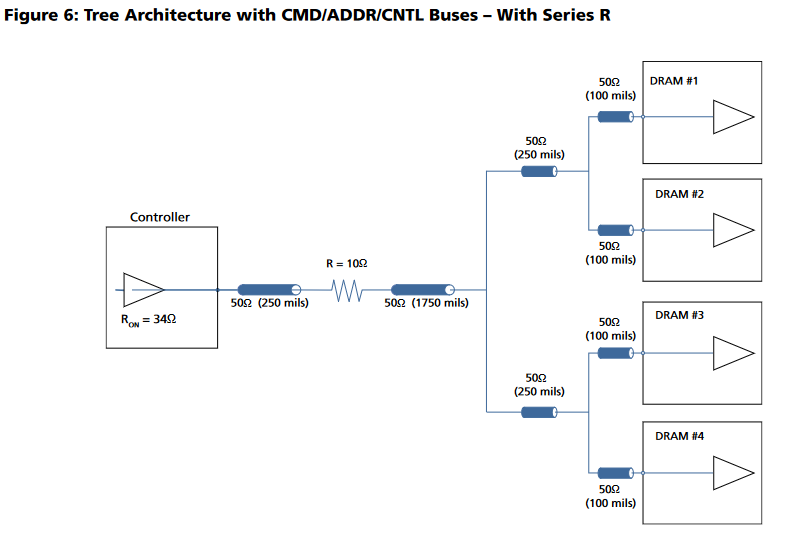
This diagram shows the way I routed the non-data signals (all data signals have on-die termination and don't branch out). Each branch of the tree must have equal lengths as well.
![]()
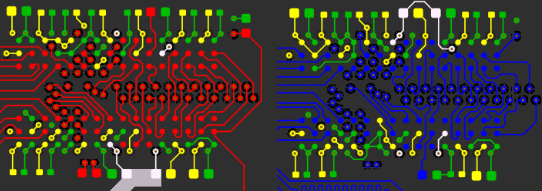
I accomplished this by placing the two DDR3 chips in the same location, one on the top and one on the bottom. I then length matched each trace on both sides (the branches) to a field of vias and brought all the signals out to the FPGA on another layer.
![]()
Open the above GIF in another window if it's stopped and you'll see the whole layout. The rest of the data signals just needed some length matching, though it was tough to fit all those signals in to each layer!
![https://cdn.discordapp.com/attachments/909600035786878987/941342101545820240/PXL_20220210_043039082.jpg]() After placing *wayyy* too many 0201s, here it is next to the module its replacing!
After placing *wayyy* too many 0201s, here it is next to the module its replacing!![https://cdn.discordapp.com/attachments/909600035786878987/941342102619586590/PXL_20220210_044232292.MP3.jpg]() And finally, the purely purple prototype! Follow this project to catch the next mainboard revision, where we will be integrating Thunderbolt in a supremely janky way!
And finally, the purely purple prototype! Follow this project to catch the next mainboard revision, where we will be integrating Thunderbolt in a supremely janky way!
Thanks for giving this post a read, and feel free to write a comment if anything was unclear or explained poorly, so I can edit and improve the post to make things clearer!
-
Demo Video!
11/07/2021 at 00:01 • 0 commentsGithub Repo:
https://github.com/EEVengers/ThunderS...Discord Server:
https://discord.gg/pds7k3WrpKCrowd Supply:
https://www.crowdsupply.com/eevengers/thunderscope -
Software Part 2: Electron, Redux and React
10/30/2021 at 19:12 • 1 commentDespite the name of this project log, we aren't talking about chemistry! Instead, I welcome back my friend Andrew, who I now owe a couple pounds of chicken wings for recounting the war stories behind the software of this project!
We’re coming off the tail end of a lot of hardware, and some software sprinkled in as of the earlier post. Well my friends, this is it, we’re walking down from the top of Mount Doom, hopefully to the sound of cheering crowds as we wrap up this tale. Let ye who care not for the struggles of the software part of “software defined oscilloscope” exit the room now. No, seriously, this is your easy out. I’m not watching. Go on. Still here? Okay.
Let’s get right to the most unceremonious point, since I’m sure this alone is plenty to cause us to be branded Servants of Sauron. The desktop application, and the GUI, is an Electron app. I know, I know, but hear me out. For context, Electron is the framework and set of tools that runs some of the most commonly used apps on your computer. Things like Spotify and Slack run on Electron. It is very commonly used and often gets a bad rep because of various things like performance, security, and the apps just not feeling like good citizens of their respective platforms.
All of these things can be true. Electron is effectively a Chrome window, running a website, with some native OS integrations for Windows, macOS and Linux in general. It also provides a way for a web app to have deeper integrations with some core OS functions we alluded to earlier, such as the unix sockets/windows named pipes system. Chrome is famously known for not being light on memory, this much is true, but it has gotten significantly better over the last few years and continues to be so. Much the same can be said for security, between Chrome improvements that get upstreamed to Chromium and Electron specific hardening, poor security in an electron app is now often just developer oversight. The most pertinent point is the good citizenry of the app on its platform. Famously, people on Mac expect such an app to behave a certain way. Windows is much the same, though the visual design language is not as clearly policed, many of the behaviours are. Linux is actually the easiest since clear definitions don’t really exist, this has led to, funny enough, the Linux community being some of the largest acceptors of Electron apps. After all, they get apps they may otherwise not get at all.
As much as I would love to write a book containing my thoughts on Electron, I am afraid that’s not what this blog calls for. So, in quick summary, why Electron for us, a high speed, performance sensitive application? I will note this, none on the team were web developers prior to starting. It is very often the case that when web developers or designers switch over to application development, they will use Electron in order to leverage their already existing skills. This is good, mind you, but this was not the case for us. We needed an easy way to create a cross platform application that could meet our requirements. In trying to find the best solution, I discovered two facts. Fact the first, many other high speed applications are beginning to leverage Electron. Fact the second, finding out that integration with native code on the Electron side is not nearly as prohibitive as I initially thought. So, twas on a faithful Noon when I suggested to our usual writer, Aleksa, that we should give Electron a whirl. I got laughed at. Then the comically necessary “Oh wait no you’re serious”. I got to work, making us a template to start from and proving the concept. That’s how we ended up here.
---------- more ----------![]()
Last we left off, we were shooting data into the blackbox that was our GUI. Continuing from there, our data goes into something called a Context Isolation pipeline. Without going too deep into it, Context Isolation is an Electron feature that runs your own Electron scripts and APIs in a separate context than the website running within the app. This is important for security, as a website could potentially inject code using these very powerful APIs.
The data goes through internal processing, where the packets are broken down into their actual data in order to be analyzed and displayed by the app. From the opposite direction, this is also where packets including scope commands would be formed before being sent. From there, we go off into React. While Electron is our app framework, we chose to use React for our UI needs. Put simply, it is very common with lots of available resources. Since the data is now in a format TypeScript can understand, it is passed onto the graphing library.
Due to time constraints, we chose to not roll our own graphing library. We knew that in time, we would have to, but for now an open source React based solution would have to suffice. This is our second reason for picking React, the litany of options. We chose react-vis, made and maintained by the fine folks over at Uber. I should note that this whole pipeline needs to be ridiculously fast. As such, we do the bare minimum of processing in Electron, as most of it would have been done in C++ already, including measurements. By the time the data arrives in the app, we fast track it to the graph. As part of this process, labels in the app get updated, such as the measurements of various channels like mentioned before.
![]()
The right hand side column is what we call the “Data Display Components” on the block diagram. This encompasses both read-only labels, as well as the buttons and selectors, which we’ve so aptly called “User Interactable Components”. A user can change the type of math being done between channels, such as addition and subtraction using these. The user can also enable or disable channels here. Certain interactions, such as channel switching, trigger a scope control message to be sent out, following our packet pipeline the other way, as we have often talked about. The instruction is encoded, sent along in a packet, and the C++ uses the driver to trigger the correct function inside the FPGA, and the wonderful loop continues still. This forms the conclusion of the basis of our data loop and how it functions. While the feature set can yet be expanded on, and most of the remaining work is indeed application side, the solid foundation provides a healthy landscape for continued work.
![]()
I want to take just a moment to discuss how technical challenges evolve over time, and in this, address the one block I have ignored on our block diagram. As you can see from our prototype, the design has changed, but not massively. We’re engineers, making a tool for engineers. We recognized early on that we were not designers, and we knew that making the nicest to use piece of software would take a lot more time than we had available to us. As such, we strived to create a solid base, almost a good wireframe, that could be iterated upon. I hope this explains why some of the usual creature comforts one would expect to happen are not yet present. We wanted to ensure in anything we did, we didn’t accrue tech debt or create future work for ourselves. At least not wittingly. This careful approach would allow us to build up in the future without having to tear down massively before (we did consider using some big open source react elements library to make things look nicer on the short term, but we thought that disingenuous).
As for that last block, Redux. Anyone familiar with React is likely to be familiar with Redux as well. We’re all familiar with state machines in the most traditional sense, it helps keep a system working as it should with all components being on the same page effectively. Redux is not a state machine. It does not enforce explicitly a state within a graphically expressible state diagram. Instead, it uses triggers to send out commands using actions based on requirements defined by the designer. This sounds like I’m saying “It’s not a state machine, it’s a state machine”. I basically am saying that, because the logic for switching states in Redux looks an awful lot like any state machine (in web land, XState is a popular tool). The key difference however, is that Redux does not prevent variables and status linked to states, from being changed by anything other than Redux. It is possible for you to code for impossible states and to end up in unrecoverable positions.
We all know that state based management is the best way to control a relatively complex system. We tried to stay away from it in our own app, but eventually we found out we were creating unnecessary complexity to avoid, slightly less complex complexity (something about unwitting tech debt anyone?). Yet, while Redux solved many of our issues, it also caused a decent amount of extra work based on the lack of safe guards provided. This perhaps serves as a cautionary tale and a good reminder that control systems itself continues to be perhaps the most crucial of all disciplines.
Thanks again to Andrew for the excellent write-up of the software! And with this post, you are pretty much caught up on the development of this project. With all the documentation done, check out all the source goodness at the git repo for this project, and stay tuned for the demo video coming up in the next post!
Thanks for giving this post a read, and feel free to write a comment if anything was unclear or explained poorly, so I can edit and improve the post to make things clearer!
-
Software Part 1: HDL, Drivers and Processing
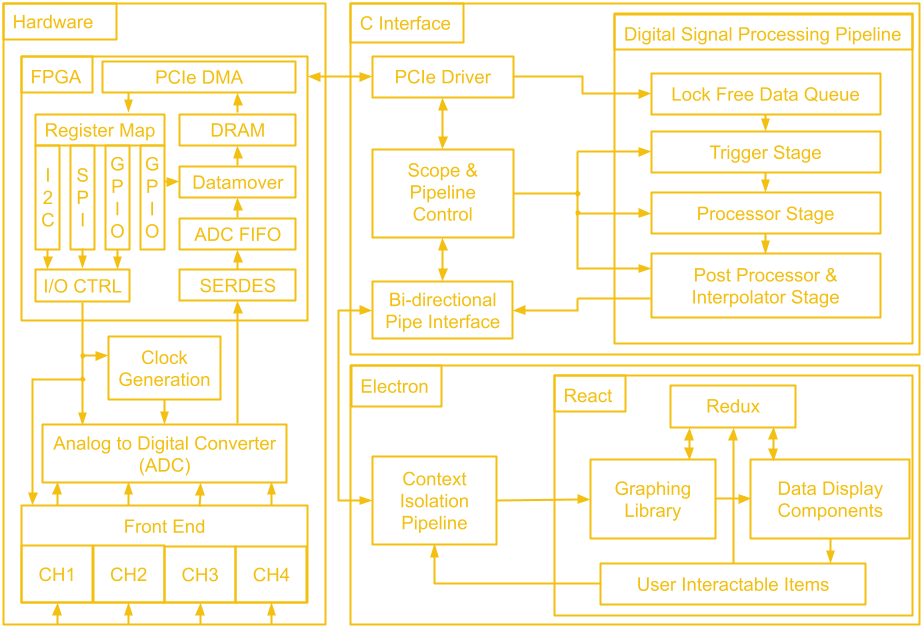
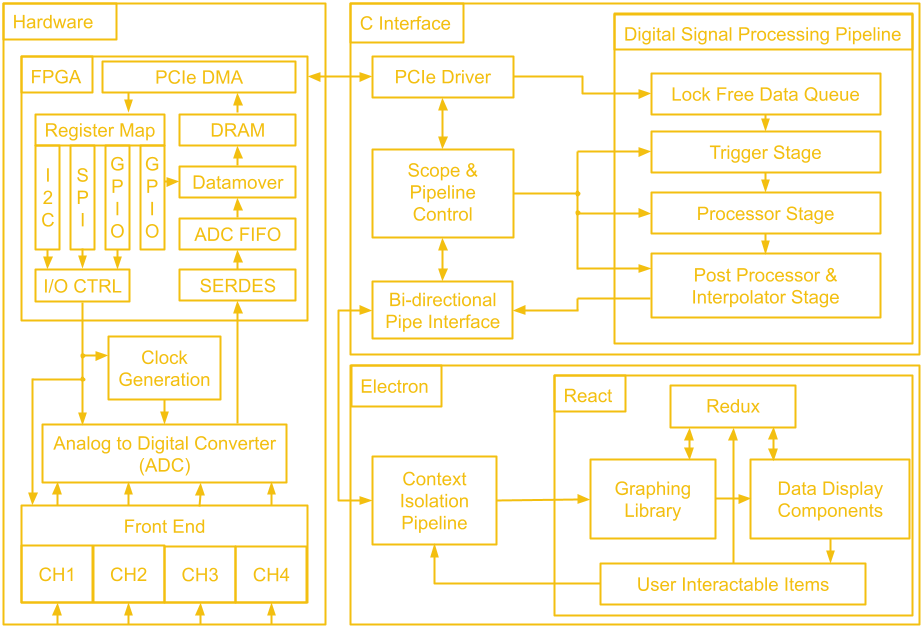
10/21/2021 at 01:07 • 0 commentsWe've gone through a lot of hardware over these last 14 project logs! Before we leave the hardware hobbit hole to venture to software mount doom, let's take a look at the map of middle earth that is the block diagram of the whole system.
![]()
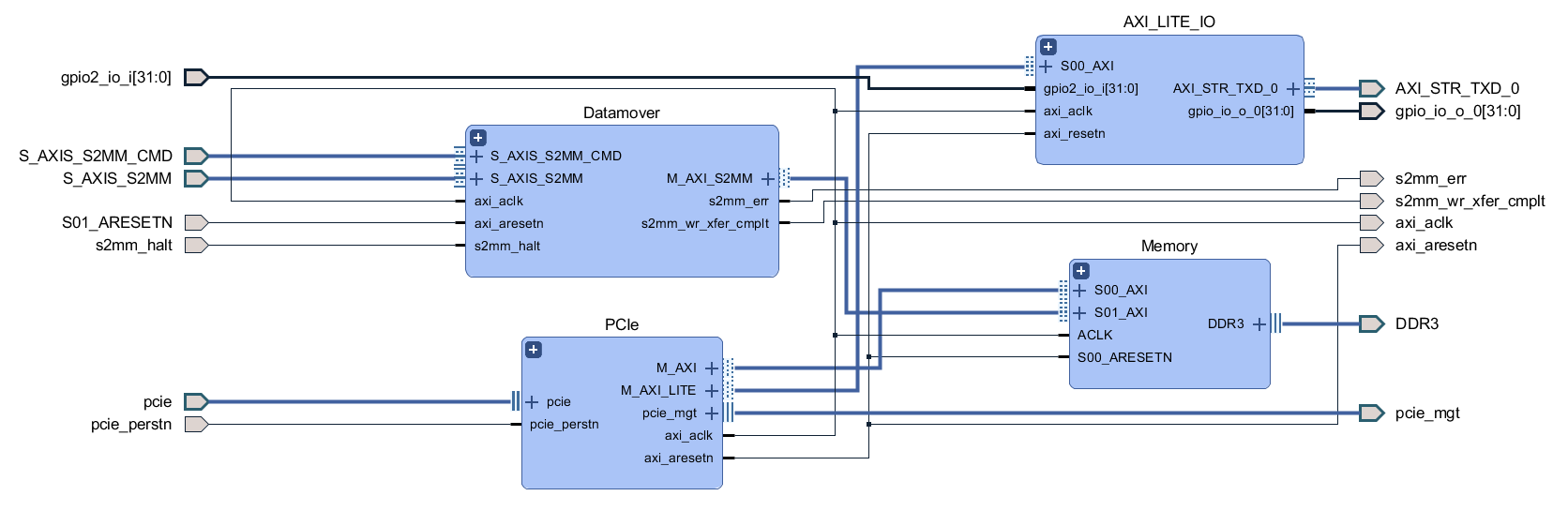
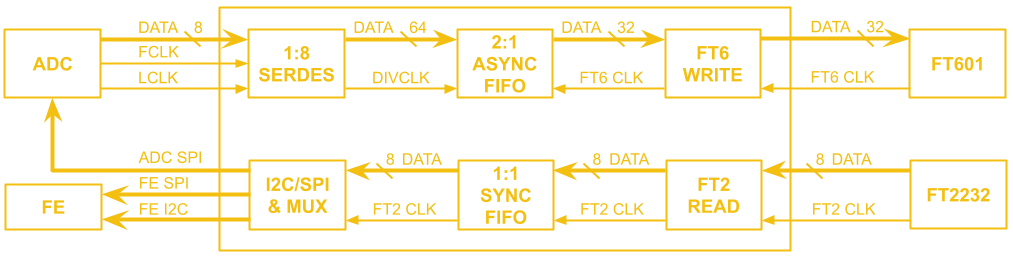
The first block we will tackle is the FPGA. The general structure is quite similar to the last design, there is ADC data coming in which gets de-serialized by the SERDES and placed into a FIFO, as well as scope control commands which are sent from the user's PC to be converted to SPI and I2C traffic. Since we don't have external USB ICs doing the work of connecting to the user's PC, this next part of the FPGA design is a little different.
There is still a low speed and a high speed path, but instead of coming from two separate ICs, both are handled by the PCIe IP. The low speed path uses the AXI Lite interface, which goes to the AXI_LITE_IO block to either fill a FIFO which supplies the serial interface block or to control GPIO which read from the other FPGA blocks or write values to the rest of the board. On the high speed path, the datamover takes sample data out of the ADC FIFO and writes it to the DDR3 memory through an AXI4 interface and the PCIe IP uses another AXI4 interface to read the sample data from the DDR3 memory. The reads and writes to the DDR3 memory from the AXI4 interfaces are manged by the memory interface generator. The memory here serves as a circular buffer, with the datamover always writing to it, and the PCIe IP always reading from it. Collision prevention is done in software on the PC, using GPIO data from the low speed path to determine if it is safe to initiate a read.
---------- more ----------With the deadline of the Hackaday prize fast approaching, I have called my friend Andrew out of retirement to write the rest of the software project logs. He worked on the software far more than I did, so he can give you a better overview of it! Plus he's not a chronically slow writer like I am, two project logs a month isn't too bad right?!
Next, we will question our life decisions as we begin ascending up the slope to Sauron’s domain and talk about the C interface implementation. The data is moved over PCIe by the PCIe IP's driver, also provided by Xilinx. PCIe is notoriously quite difficult to properly implement on the software side (quite the opposite from its hardware requirements) and while we considered writing a custom driver, we found that the off the shelf driver fit our requirements splendidly. This allowed our efforts to be focused elsewhere.
The driver itself passes the data to two separate sections of our C program. The first is the scope control mechanism. This is part of our bi-directional control system that allows the scope to tell the GUI the current state of the hardware (more on that in a later post), while allowing the user to change said state. Certain settings, such as voltage ranges, are not only software display options, but actually result in hardware changes in order to enable more granular reading of data.
The other data that the driver handles is, of course, the readings of the scope itself. This data takes a slightly different path as it requires some processing that would traditionally be done on the on board processor on a scope. The data first enters a queue, a circular buffer that gets processed each time it receives enough data. Specifically, this circular buffer is being analyzed for a possible trigger event, such as a falling/rising edge, as called in traditional scopes. This is such that the software knows when to lock in the data for presentation to the user.
Once a trigger event is discovered however, it then passes to the post processing and the interpolation stage. We process the data internally to make sure it conforms to the voltage and time scales expected according to the scope’s current state, and interpolate missing data based on sinx/x interpolation, the standard in oscilloscope design. You might notice that about half of the processing block is not directly related to hardware itself, but is actually present solely to ensure that the data can be accurately displayed to the user in the GUI. This is one of the challenges of such an implementation, where different components that are not self contained within the scope hardware have to sync up and communicate seamlessly.
Once the data has been processed, it is passed to the bi-directional pipe interface, where we once again meet up with our scope state information, ready to be passed onto our GUI (once again, more on that in a future post). In order to understand the choices we’ve made however, it is important that we explain exactly what our data pipeline is. On Linux we use UNIX Sockets, a quite simple, packet based IPC protocol that will be familiar to anyone that has had to make two programs talk before. We initially used a single bi-directional pipe. This brought about some challenges but with some timing sync logic, it worked out.
Then we looked at implementing the Windows logic. On Windows, the equivalent is something called Named Pipes. These do not really support bi-directional data transfers. The more suggested path, however, is just two parallel one way pipes. Upon testing we didn’t see any performance degradation on the Electron side. Turns out web browsers are quite good at handling packets, who knew? We also changed the Linux implementation to be the same, just to be able to reuse as much code as possible. The other interesting fact we discovered is that, in trying to keep the packets lean, we ended up with quite poor performance on the GUI side. It turns out that on Windows, there’s a upper limit on the top speed of packet delivery, a sort of “next bus” problem.
This does not change regardless of how much data you pack into one packet, up to a maximum limit. As such, the pipe towards the GUI packs enough data such that if we fill every available “bus”, we achieve 60fps on the display. The GUI app reads the header of the packet to figure out the beginning and end of actual data versus state updates and separates it as such for processing. On the receiving side, things are very similar. In order to ensure the system stays synced, the GUI also sends overloaded packets to the C program, to keep the side consistent, even though scope commands don’t technically call for this level of data density. Similar to the GUI side, the C program reads the header to know which commands were sent, compares them to a known look up table converting our internal identifier and value to a known “state”, and sends that state down the driver and to the FPGA to work its magic! And that’s all folks. Tune in next time for a deep dive into the Electron app and the GUI.
Thanks for giving this post a read, and feel free to write a comment if anything was unclear or explained poorly, so I can edit and improve the post to make things clearer!
-
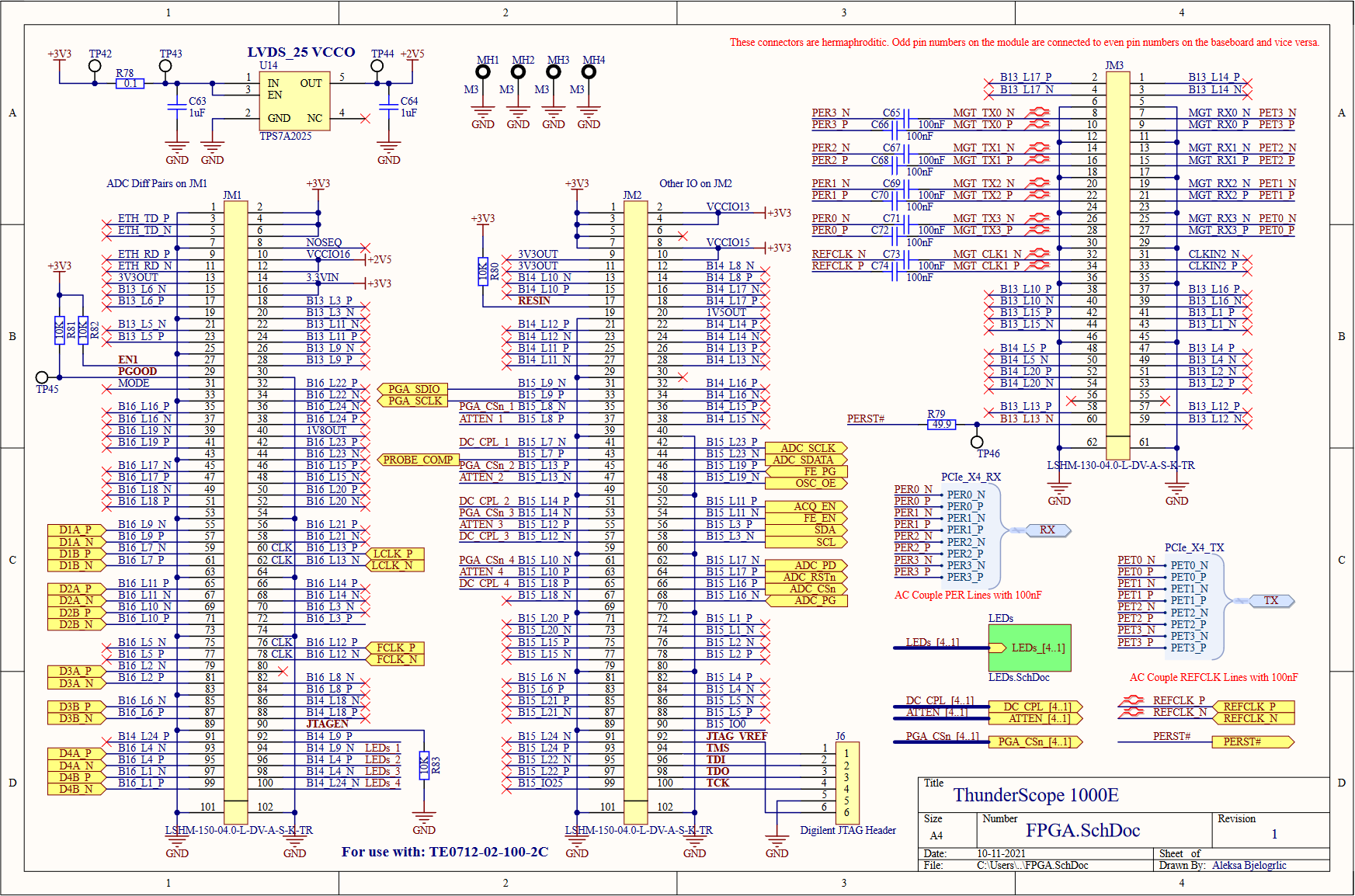
ThunderScope 1000E Rev.1
10/12/2021 at 00:27 • 4 commentsThe time had come to make a new prototype, one with all the hardware needed to accomplish the goals of this project! The front end was well proven at this point, and just needed a slight shrink to fit under an off the shelf RF shield. The ADC had always behaved well during my tests, but it needed a new (and untested) clock generator since the one I had prototyped with wasn't suited for it. Most disturbing of all, I needed to design with an Artix-7 FPGA and DDR3 RAM in BGA packages for the first time.
Tackling that last point first, I saw way too much risk in putting these BGA parts down on one board that I hand stencil and reflow solder on a hot plate. Not just that, but I only had three months until I had to submit this project to graduate my electrical engineering program and had no experience working with DDR3 nor even large BGA packages. I committed to learning these skills for the next revision, but had to find something to tide me over in a hurry.
![]()
Enter, the TE0712-02 FPGA module. This bad boy had two DDR3 ICs, the second largest Artix-7 part, and only needed a 3.3V rail to operate. As my favorite circuits professor put it, "Simplicity itself".
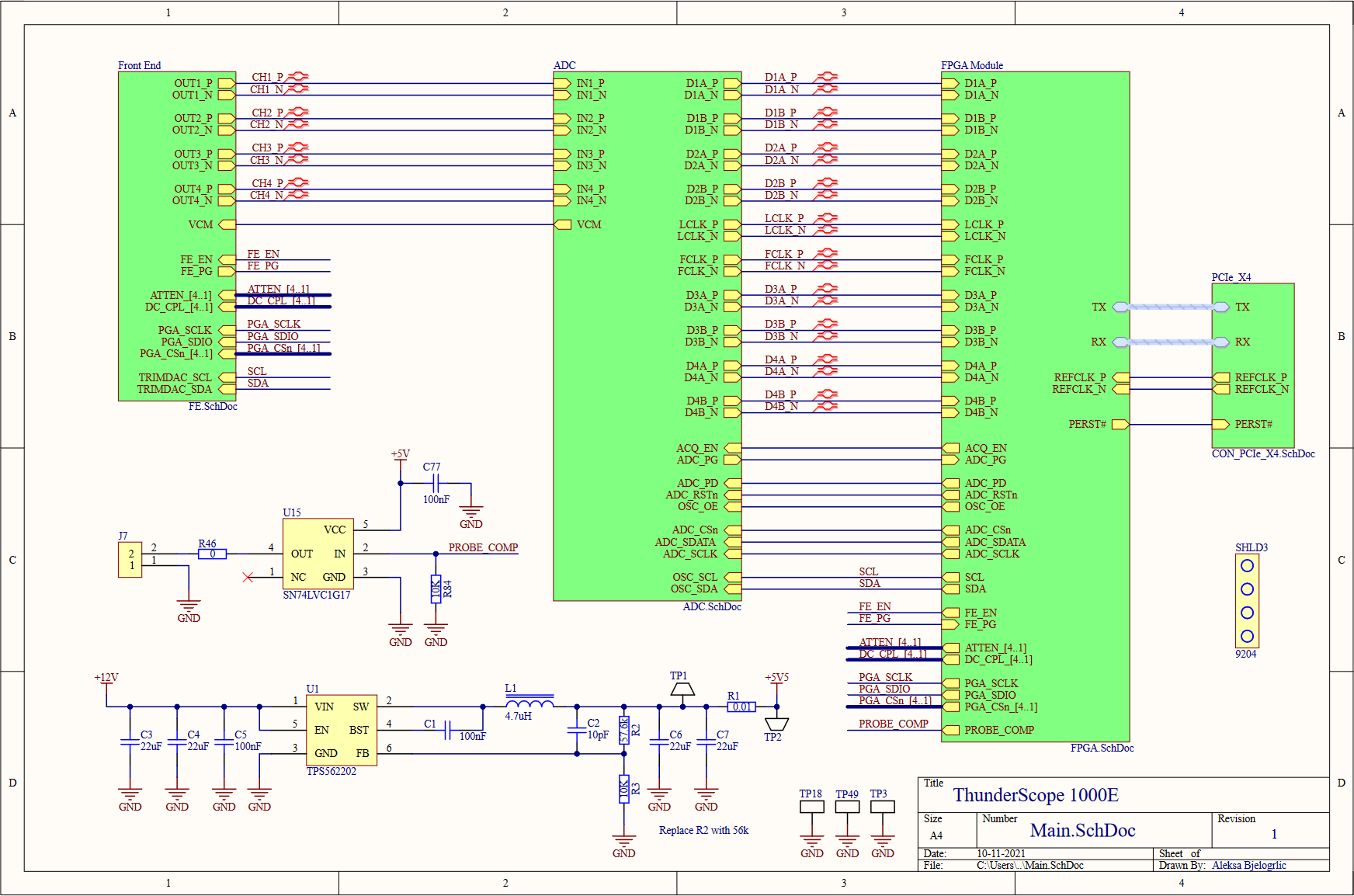
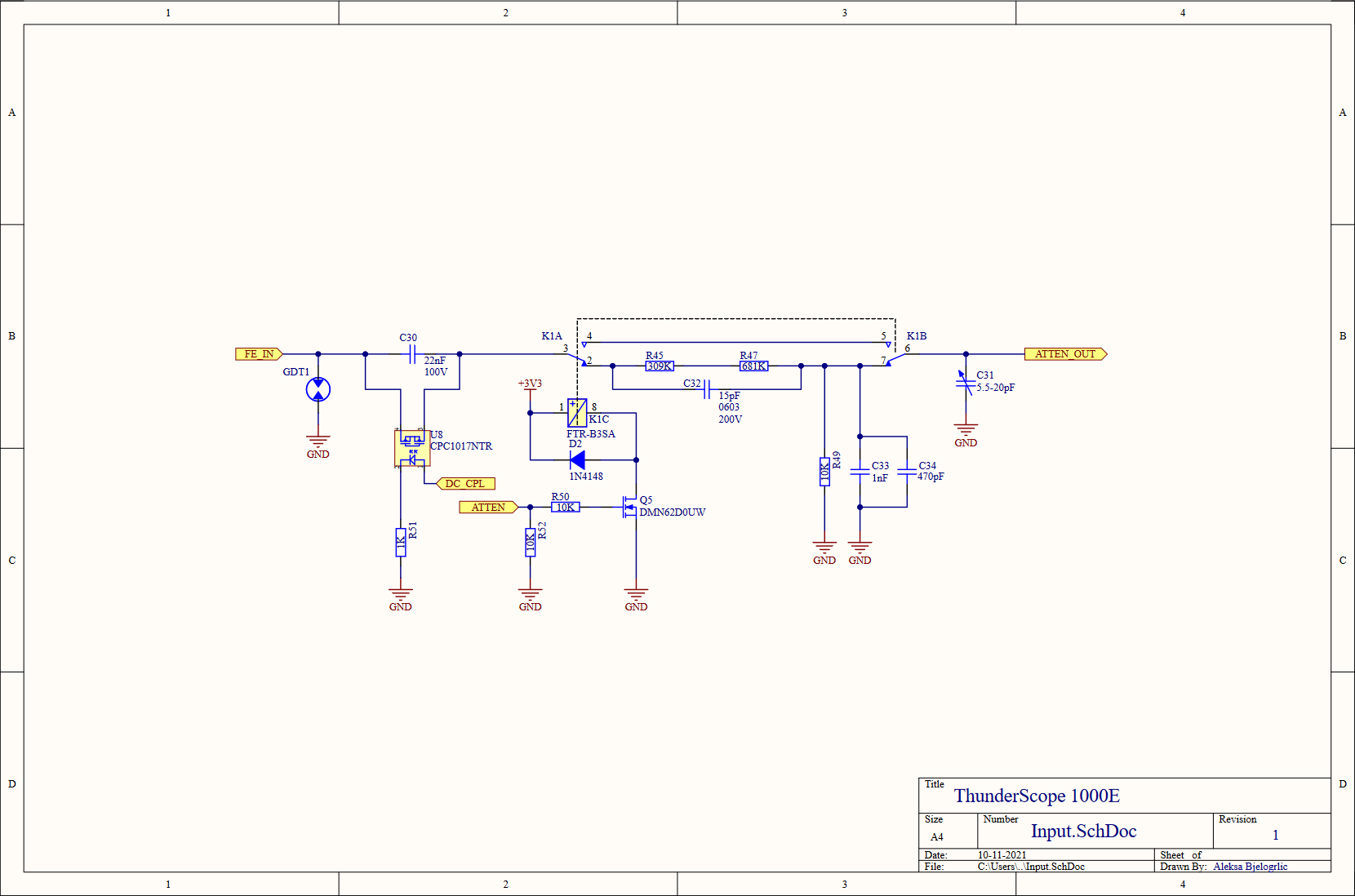
---------- more ----------The top level of the schematic serves as a good block diagram for the entire prototype. The four front end outputs go to the ADC to be digitized, and the data and clock lines carrying the sample data are connected to the FPGA module, which also takes in all the control signals for the board. The FPGA module also connects to a standard PCIe x4 edge connector, which I used a project template to generate along with the specific board shaped needed to comply with the PCIe mechanical specifications. I included the PCIe mounting bracket (SHLD3) as a BOM (bill of materials) only part (not soldered on the board) so I don't forget to order it! I included a 74 series logic buffer (U15) to drive the probe compensation terminals (which I couldn't find the proper part for, so I just used right angle 0.1" headers) from the FPGA. PCIe has two power rails, 3.3V and 12V. The 3.3V rail is limited to 3A, so I decided to use the 12V rail to power the front end in case I drew too much current for just the 3.3V rail. To do this, I used a buck converter (U1) to step the voltage down to 5.5V, which was regulated to 5V with a linear regulator to reduce switching noise in the front end's power rail. I placed shunt resistors and test points on every regulator's input and output, so I can easily measure the current draw on each rail and the efficiency of the regulators.
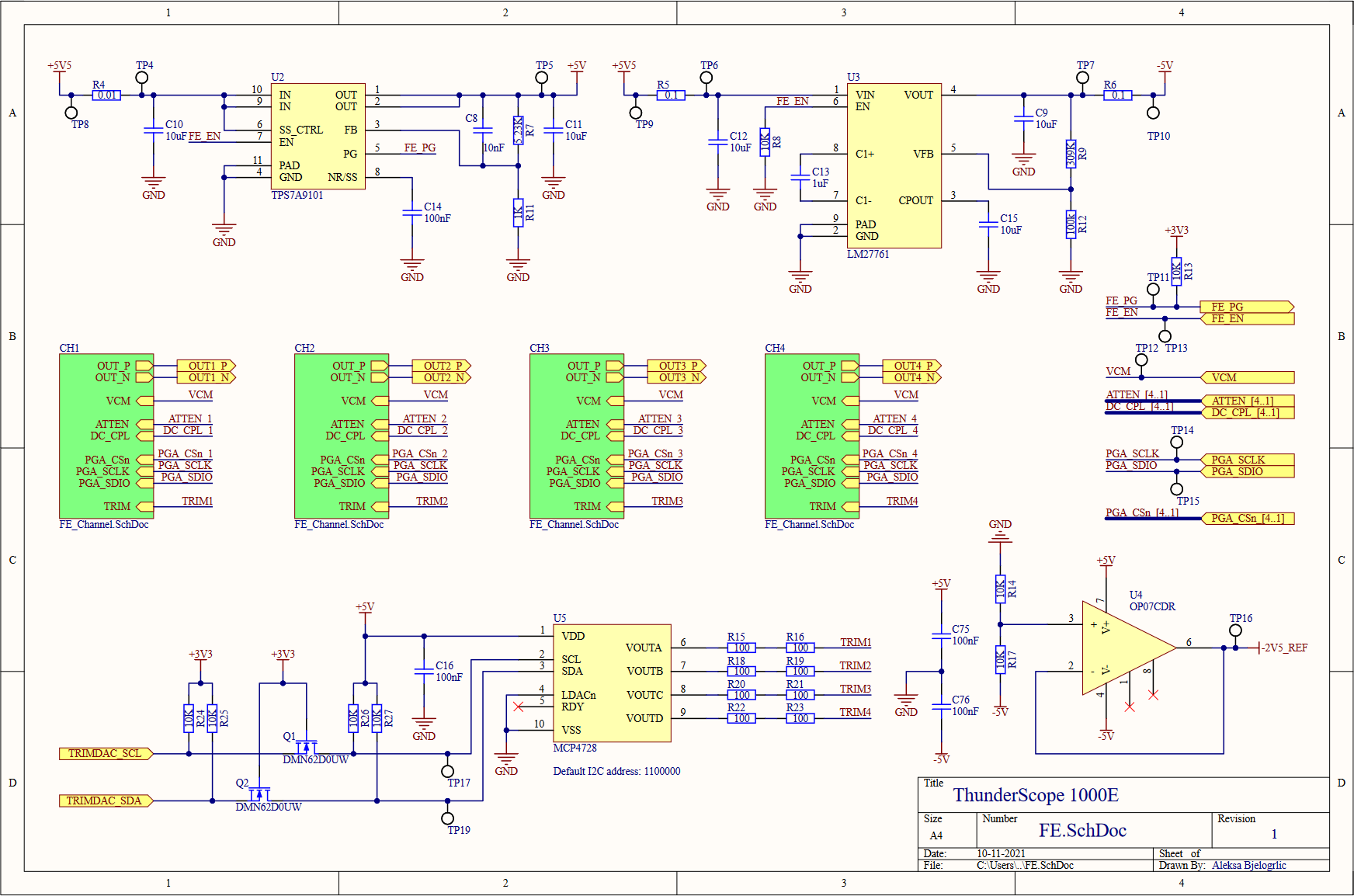
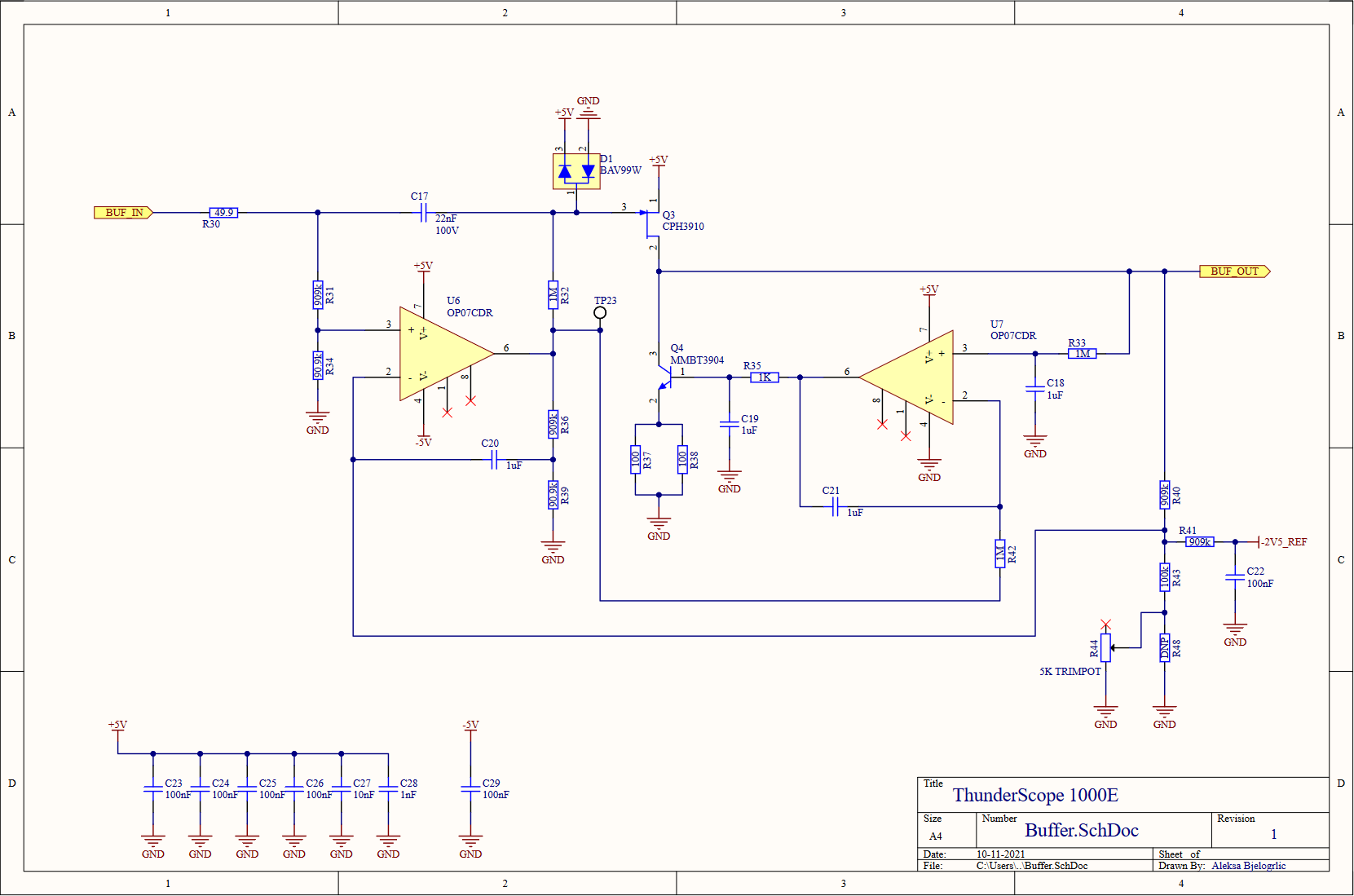
Moving on to the front end block, we see four front end channels, which will lead us deeper into this hierarchical rabbit hole. On the top of this sheet, we have the voltage regulation for the front end, both positive (U2, an LDO) and negative (U3, a charge pump with integrated LDO) 5V rails. A -2.5V reference for every channel's DC bias circuits is generated from this negative 5V rail using a divider (R14,R17) and buffered with an opamp (U4), this replaces the per channel divider from the previous design. A quad channel DAC (U5) is used to trim the DC bias values for each channel. This DAC is powered by (and referenced off of) the 5V rail, so it needed a level shifting circuit (Q1,Q2, and pull-up resistors) to match the 3.3V level of the I2C bus going to the FPGA. I also added test points on every signal going to the FPGA, better to be safe than sorry!
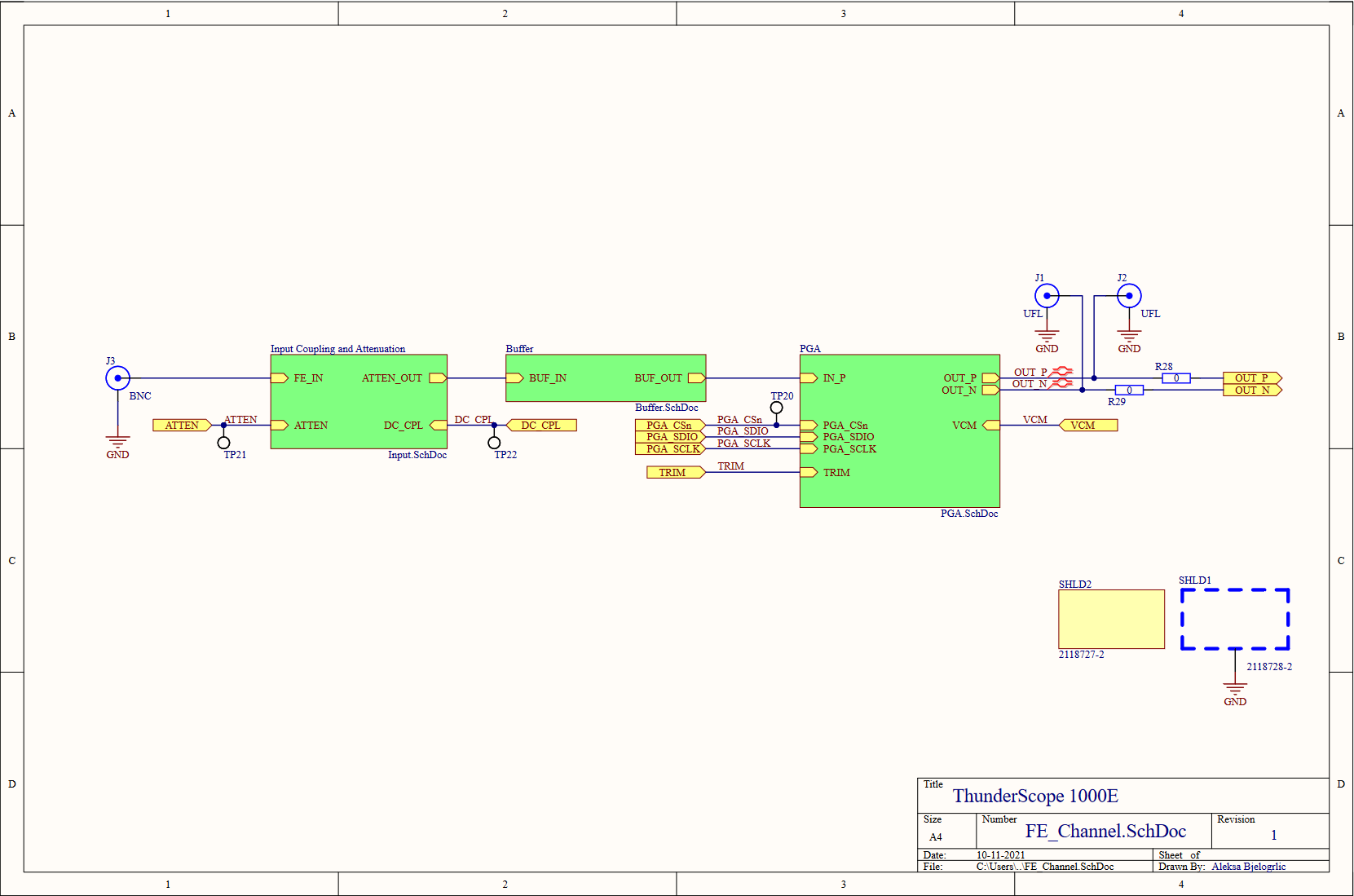
Last level of hierarchy before we get to the juicy stuff, I promise! On the left is the BNC input to the channel (J3), this is where the rubber meets the road (or where the scope meets the probe, ha). The RF shield I mentioned earlier comes in two parts, a frame (SHLD1) which is soldered onto the board, and a cover (SHLD2) which is press fit onto the frame. As with the PCIe bracket, I included the cover in the schematics and therefore the BOM so I don't forget to order it along with the rest of the parts. In order to test the front end channels, I included some UFL connectors (J1,J2) to bring the PGA output out as two 50Ω signals. When these connectors are used, the resistors (R28,R29) are removed to disconnect the output from the rest of the board to avoid doubly terminating the signal.
The input circuit was slightly simplified, removing the 6pF input cap right after the gas discharge tube and rolling it into the attenuator to get 15pF of input capacitance (provided by C32) when the relay is on. A variable capacitor (C31) was added to allow the capacitance on the non-attenuated branch to be changed to better match the attenuated branch. I also reduced the number of resistors in the attenuator, since it made no sense to worry about hitting an exact value when the resistors themselves have a 1% tolerance!
Continuing the trend of reducing the part count of this design, I replaced the two resistors that it took to get 900kΩ with a single 910kΩ, and replaced the 100kΩ that made up the other half of these dividers with 90.9kΩ to get the 1MΩ total (999.9kΩ, close enough!) needed. I also moved the protection diode over to the gate of the JFET (Q3) so that it wouldn't clamp on a DC over-voltage condition that the input would otherwise be able to handle (due to the divider on the opamp input, that node can handle up to 50VDC). I changed the value of R35 to 1KΩ from 3kΩ and C19 to 1uF from 330pF, using simulations to find common values to replace these values that didn't exist in the rest of the design. I did this to reduce BOM line items, which can reduce cost of assembly when going to a contract manufacturer. As a result of these changes, C20 also changed to 1uF from 100nF. I also split the 50Ω resistance at the emitter of Q4 into two 100Ω resistors (R37,R38) to better handle the 40mA maximum current flowing through it. Aside from using a buffered -2.5V reference, I added a trimmer potentiometer to the DC offset feedback divider to better tune the DC gain to match the AC gain of the circuit.
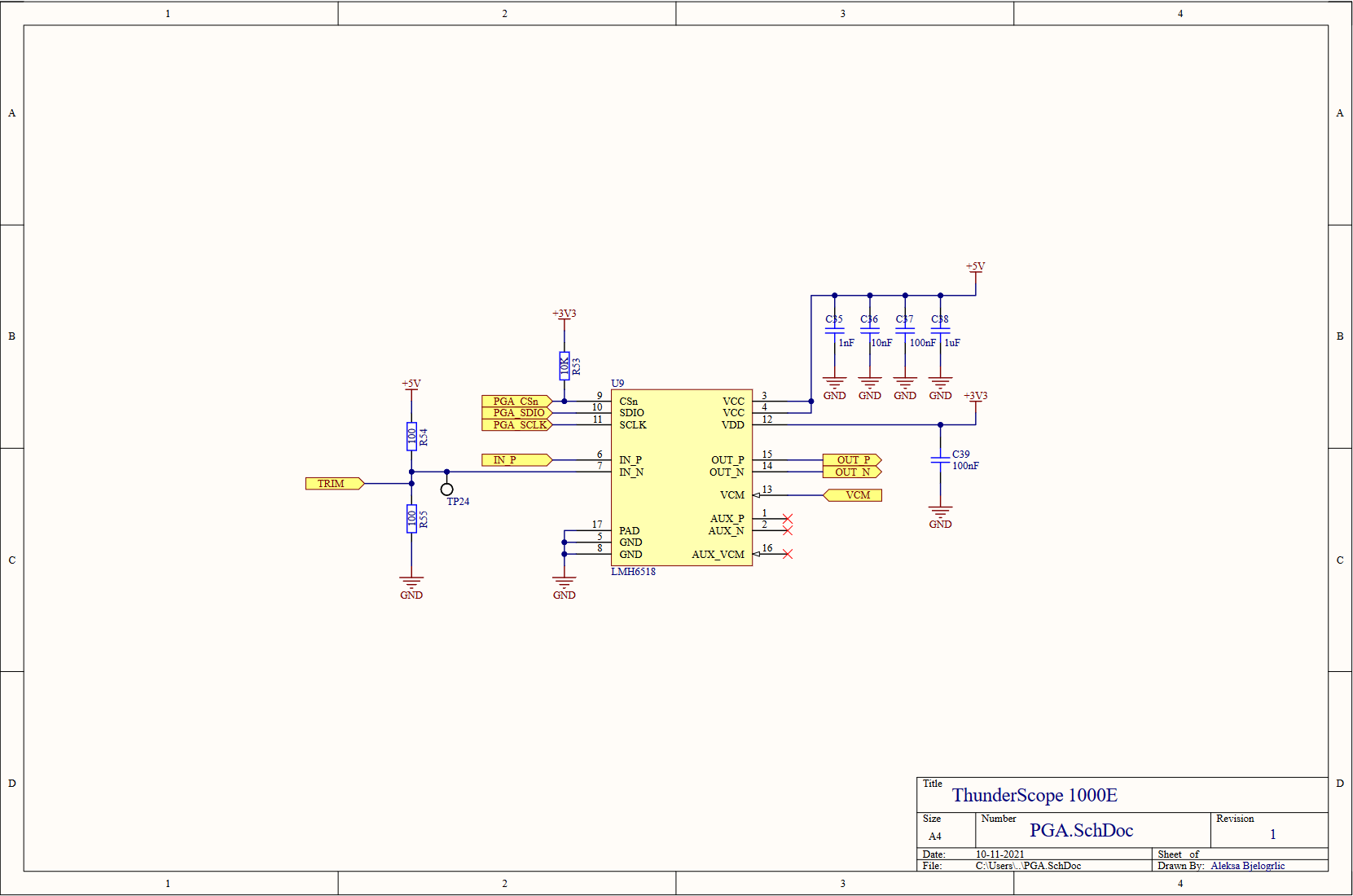
After that laundry list of a change log, I am pleased to tell you that nothing has changed in the PGA sheet. Better yet, we've completed our dive into the front end block. Now to resurface and explore the ADC and it's clock generator, which fit in just one page!
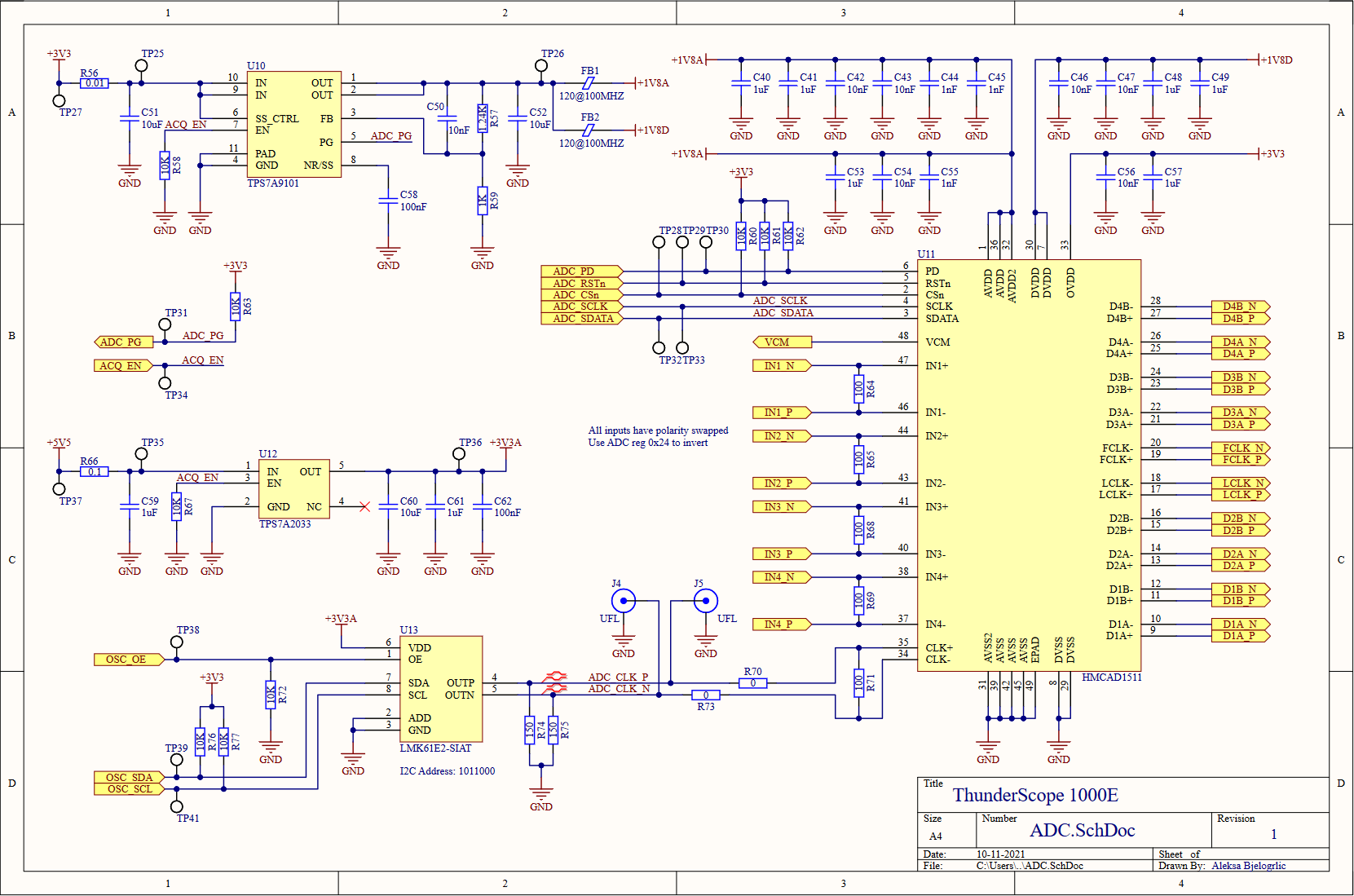
The hierarchy may be shallow, but this page wasn't smooth sailing! Luckily enough, not much has changed with the ADC or it's voltage regulation. The one major change was swapping the datasheet recommended input network to 100Ω resistors to terminate the PGA outputs properly.
The PLL I already prototyped with would provide very marginal performance as the ADC's clock, so I looked for something that would really make the most of the ADC. It needed to have low jitter, with a target to beat of 760 fs RMS measured from the previous circuit. To drive the ADC optimally, it also needed to have a LVDS or LVPECL digital differential output. I also wanted the simplest solution I could find to minimize the chances of this failing, since I likely wouldn't have time to make a new revision of this board by the capstone project deadline (so I was minimizing the chances of ME failing as well!).
In came TI to my rescue (a sentence not repeated since the start of the component shortages) with a wonder-chip. The LMK61E2 (U13) includes its own reference oscillator and loop filter, can output LVPECL, is configurable via I2C, and has a typical RMS jitter of 90 fs! This amazing chip cost almost twice as much as the previous solution, but it was a small price to pay for something that was almost sure to work. The almost in that sentence is why I included UFL connectors to pipe in a clock from somewhere else, or more optimistically, measure the clock generated by this chip. The LVPECL output requires a specific termination scheme, I used the convenient LVDS-like termination (R71,R74,R75) described in page 9 of this Renesas app note. I also added local regulation (U12) for this part to ensure a noise-free 3.3V rail, as opposed to the main 3.3V which is taken directly from the host PC (or Thunderbolt enclosure!) through the PCIe connector.
All roads lead to Rome and all connections lead to the FPGA! The FPGA module has three Samtec LSHM connectors which bring out the FPGA's IO banks and their voltage rails. All the bank IO voltages are set to 3.3V except bank 16, which must be 2.5V (regulated by U14, an LDO) to enable on-chip termination for LVDS. I brought the JTAG lines out to a header (J6) that matches the pinout of my programmer and included four LEDs (on a seperate page to save space) for debugging.
![]()
Here's how all of that looks on a board! I decided to get fancy with it and digitized my group members initials to include in an ENIG gold finish. And speaking of, what kind of software magic did the rest of my group get up to? Stay tuned for the next posts, which will be all about the software that makes this thing tick!
Thanks for giving this post a read, and feel free to write a comment if anything was unclear or explained poorly, so I can edit and improve the post to make things clearer!
-
Designing and Testing a 1 GHz PLL
10/06/2021 at 23:04 • 0 commentsNow that I knew that the throughput to the PC could match the ADC’s rated sample rate of 1 GS/s, I had to make a circuit that clocked the ADC at that rate as well. This circuit needed to output at 1 GHz with very low jitter, as any jitter on the ADC sample clock will turn into noise during the conversion process.
The heart of the clock generation circuit is the phase locked loop (PLL). Without getting into too much detail, the PLL compares the phase of a low frequency reference (generally from a crystal oscillator) with a divided down copy of a high frequency that is generated by a voltage controlled oscillator (VCO), which it tunes until the two match. By changing the division settings any frequency can be synthesized, with the accuracy and jitter characteristics of the reference conferred onto the output.
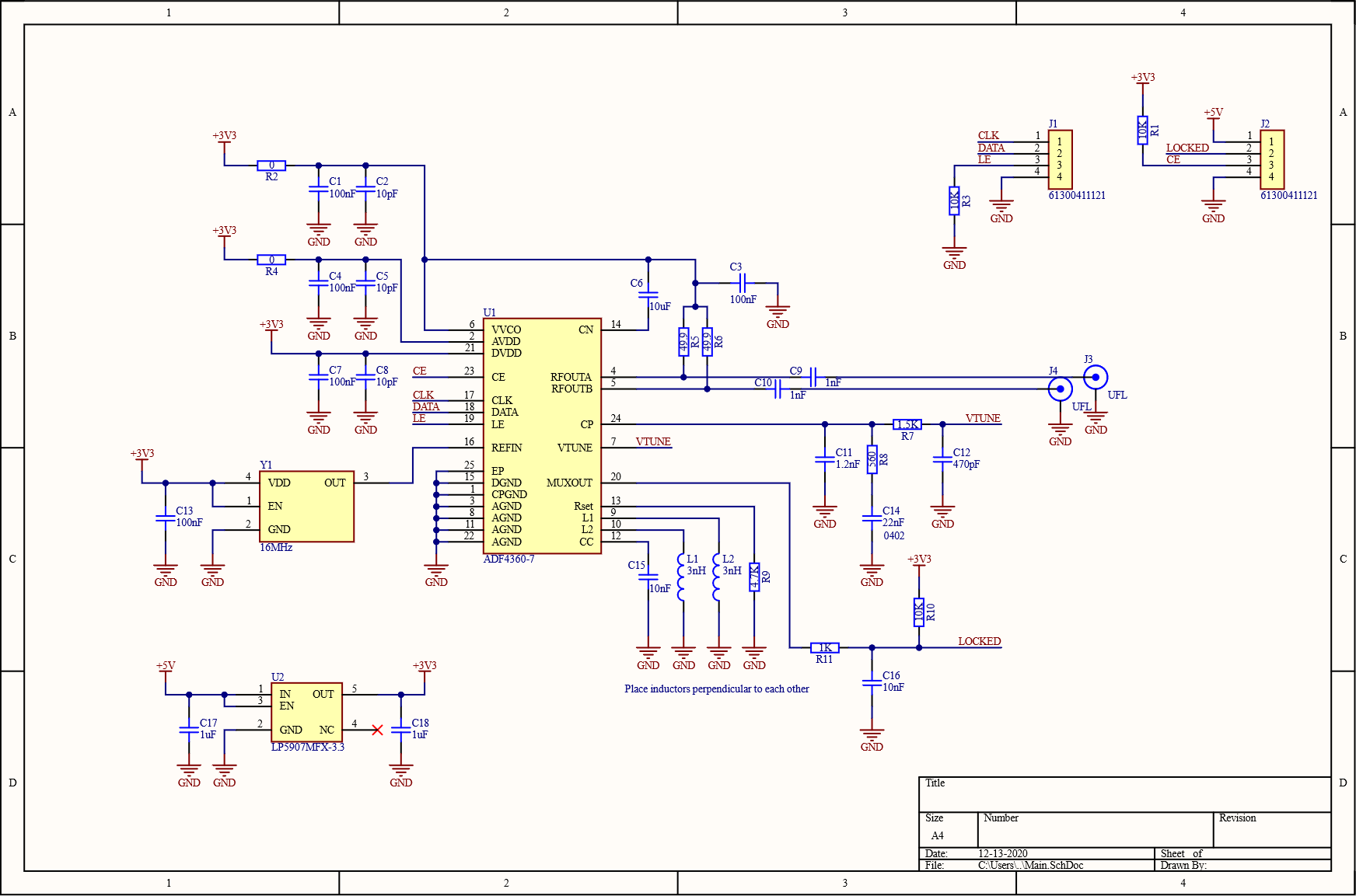
Looking at the other scopes that use the same ADC, I found that many also used the ADF4360-7 in their clock generation circuit. I did some research on the part and it seemed to be the cheapest solution that would give me the 1 GHz output I needed. This chip had an integrated VCO, so the only other parts I needed were the reference oscillator and some passives. Saving me loads of digging into the datasheet, Analog Devices had a tool for calculating all the values of the passives as well as the register values to program for a given output frequency.
That sticky note yellow colour... The navy blue connections... That's not KiCad! It's true, it was at this point that I was offered an Altium license through my school. And with the size and scope of the next board already in mind, and the year of internships working with it, I decided to switch over. As for the design, I chose to use two 50Ω resistors (R5, R6) to bias the output as opposed to a more complicated matched network. The reference oscillator (Y1) was a 16 MHz crystal oscillator, which came temperature compensated for added frequency stability, and the LDO (U2) was a low noise part to avoid noise on the power rails affecting the performance of the circuit. Decoupling cap values were copied from the part's evaluation board and the rest of the passive values were taken from the design tool.
![]()
Pictured here, a 1 GHz postage stamp! I didn't have any decent way to test it on its own, so I hooked the SPI bus up to the rest of the oscilloscope prototype and updated the software to set all the registers on the chip at boot.
![]()
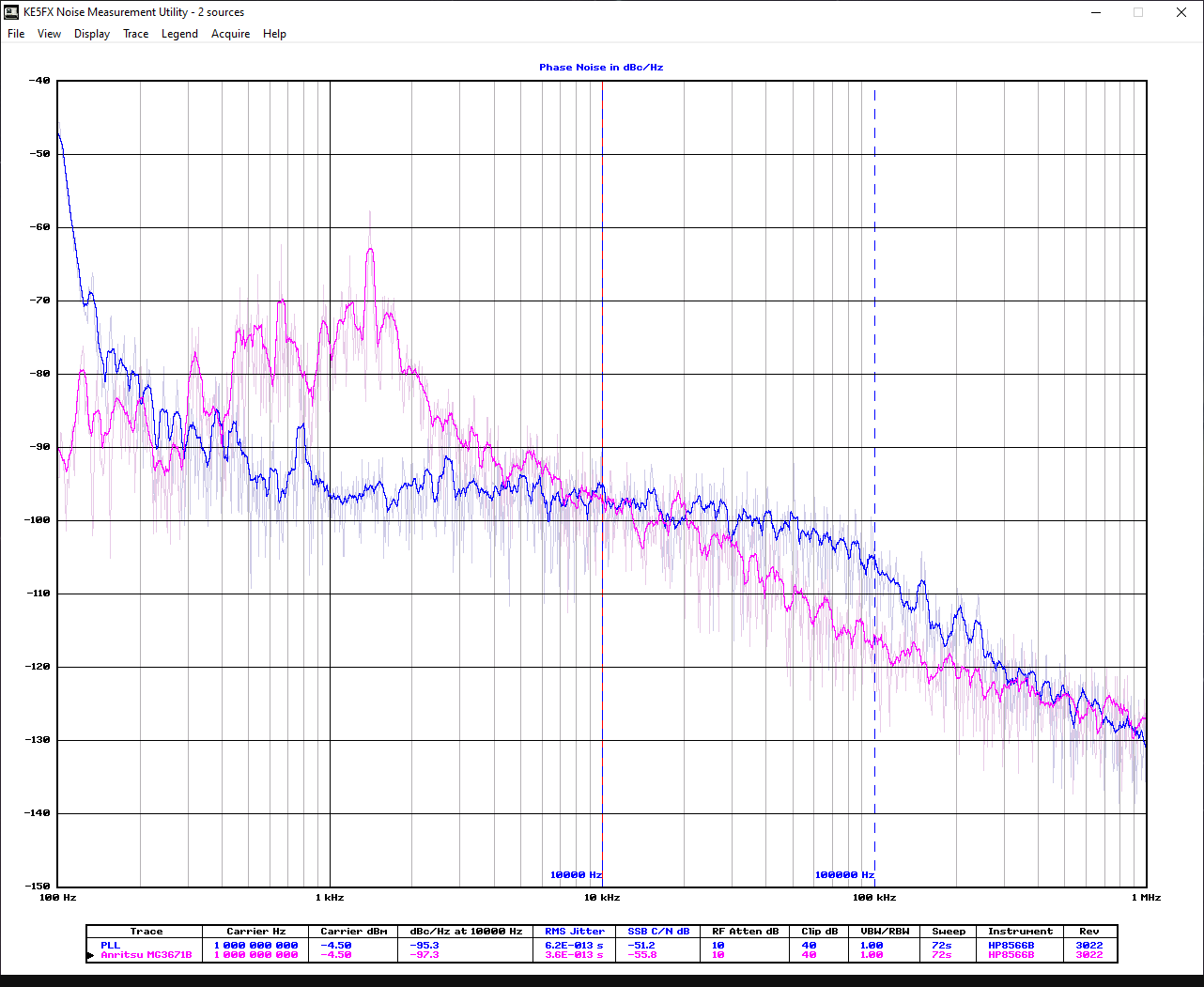
First I connected the RF output to a balun on a scrap ADC board to generate a single ended output that I could test on my spectrum analyzer. I then verified that it output at 1 GHz and used KE5FX's excellent GPIB toolkit to measure its phase noise performance against the simulation values from the tool as well as calculate total RMS jitter.
![]()
Here it is against my RF signal generator (in pink). The 100 Hz range was off, but the other ranges matched the simulations pretty well. The RMS jitter from 1.00kHz to 1.00MHz (didn't have a screenshot of this range, so the numbers are different here) was 760 fs vs. a simulated value of 580 fs. All of this looked promising, so I moved on to functional testing.
I hooked up the RF output into the ADC board through the two UFL connectors I included for differential inputs and updated the FPGA code to reflect the new clock rate. I then ran a quick capture to a CSV file, and the script hanged! That was odd, so I started debugging. Eventually, I found that the ADC wasn't outputting a clock at all! I looked through the clocking section of the ADC datasheet and this line jumped out at me:
"For differential sine wave clock input the amplitude must be at least ± 0.8 Vpp."
A quick trip to the dBm conversion table later, I found that I needed at least 2 dBm of output power. I had about -5 dBm! The matched output network I mentioned earlier would net me an output of -2 dBm according to the datasheet, which is still not up to spec.
My conclusion is that the circuit would probably work, given it's what the other manufacturers use, but it would have to be very marginal. The goal of this project is to make a better oscilloscope at the same price point by offloading so many costly aspects of a benchtop oscilloscope to the user's PC. This allows me to spend more on components to get the performance I want out of this design. With this in mind, I decided not to bother squeezing out every dBm just to reach the bare minimum the ADC would function on, and use a different clock generator that would make the most of the ADC.
Unfortunately, I was running out of time in my final term to get this project done. I had to go straight to the final design, a x4 PCIe card that incorporated all the other blocks I've written about, as well as a new (and untested) clock generator! Follow this project for the whopper of a project log that's coming up, as well as some posts about all the software work the rest of my group was doing as I was designing the hardware!
Thanks for giving this post a read, and feel free to write a comment if anything was unclear or explained poorly, so I can edit and improve the post to make things clearer!
-
Mach 1 GB/s: Breaking the Throughput Barrier
09/25/2021 at 20:31 • 0 commentsNow that the front end was in a satisfactory state, it was time to revisit the architecture of the digital interface. At this point it had been over a year since I designed that board. I chose a USB 3 Gen 1 interface capable of 400 MB/s (which proved to be 370 MB/s in practice) as a stopgap to develop on until a USB 3 Gen 2 chip was released that could match the 1 GB/s throughput of the raw ADC data. Unfortunately, the FX3G2 on Cypress's USB product roadmap failed to materialize, leaving me with few options.
I considered using the Cyclone 10 GX (which is the cheapest FPGA with the needed 10 Gb/s transceivers) with USB 3 Gen 2 IP, but even this couldn't reach 1 GB/s, topping out at 905 MB/s according to the vendor's product sheet. I considered PCIe, which is super common on FPGAs, with free IP and loads of vendor support! However, that would seem to limit this to desktops, since most people don't have PCIe slots on their laptops.
They did have the next best thing though! Thunderbolt 3 (and now USB 4 and Thunderbolt 4) supports up to four lanes of PCIe Gen 3 at a maximum throughput of 40 Gb/s. Perfect! Unfortunately, though the chips themselves are freely available on Mouser, the datasheets are not. I didn't worry about that yet, as I could prototype the system as if it was just a PCIe card by using an external GPU enclosure. This review and teardown really showcased how simple the extra Thunderbolt 3 circuitry was, so I didn't feel like it was a big stretch to incorporate it once the PCIe design was tried and true. I bought the enclosure and got to work finding a new FPGA to do all the PCIe magic.
![]()
I used this list of FPGA development boards to find the most affordable way to start prototyping with PCIe. This turned out to be the Litefury, an Artix-7 development board which appears to be a rebadged SQRL Acorn CLE-215+ (an FPGA cryptomining board). Although this board had the four lanes of PCIe I needed, it came in an M.2 form factor so it needed an adaptor. It didn't have a built in programmer either, so I used this one, which was the cheapest one that worked directly with Vivado (Xilinx's IDE for their FPGAs).
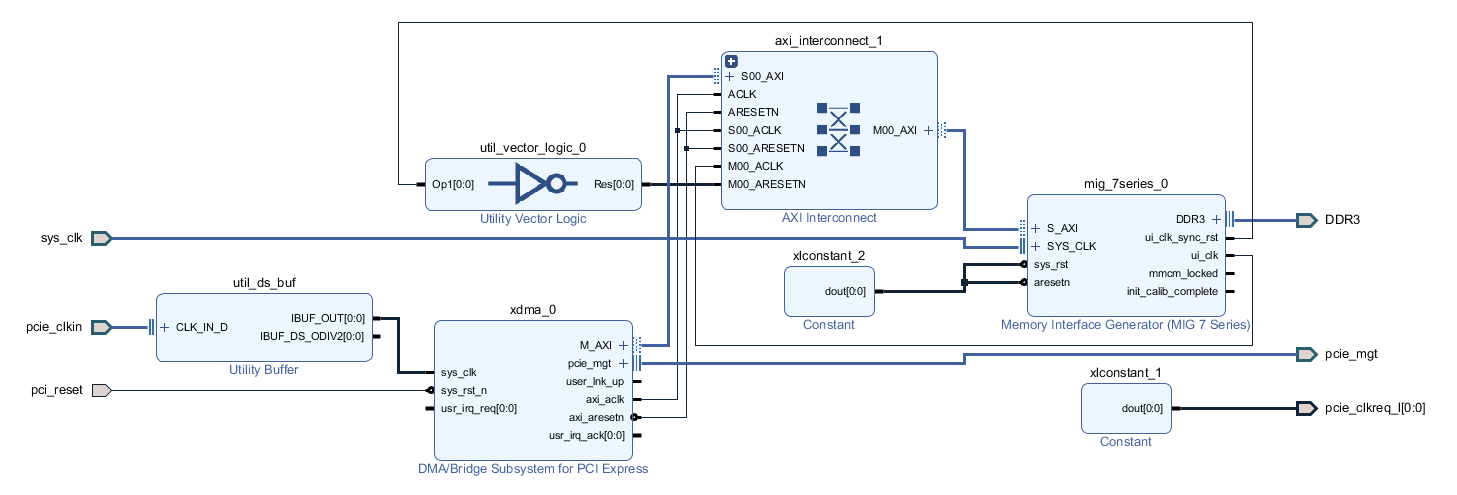
![]()
Shown above is the Vivado block diagram of the Litefury example design, this design allows DMA access from the PC to the onboard DDR3 memory and vice verse. I would use this to verify the transfer speeds when connected directly to a desktop PC compared to those through Thunderbolt when it was installed in the enclosure. I installed the XDMA drivers (which I had to enable test mode in Windows for, since the driver is unsigned) and ran a basic transfer with the maximum transfer size of 8 MB.
It took 7.072 milliseconds to receive 8 MB, which is just over 1.1 GB/s! Best of all, this number didn't budge when I tested it over Thunderbolt!
This inspired me to finally gave this project it's name: ThunderScope!
Follow this project to catch my next post on designing a 1 GHz PLL to take advantage of this blazing fast transfer rate, and then promptly learning my lesson about cribbing off the other oscilloscope manufacturers!
Thanks for giving this post a read, and feel free to write a comment if anything was unclear or explained poorly, so I can edit and improve the post to make things clearer!
-
Testing The New Front End Architecture
09/16/2021 at 00:04 • 0 commentsIt was time to see if the third time really was the charm and test the newest revision of the front end! The first task was to test the front of the front end (FFE) - the coupling circuit, attenuators and input buffer.
![]()
Look ma no probes! I started off by verifying the DC bias voltage at the output, which was just about the 2.5V I expected. The exact value of the bias voltage isn't important as it will be matched by the trimmer DAC once the channel is calibrated. I tested the AC coupling by adding a DC component to the signal, which caused no change to the DC voltage at the output. Next, I enabled DC coupling and confirmed that this DC component was now added to the bias voltage at the output. I then measured the DC gain, which was just under unity. After the coupling tests, I switched on the attenuator and was greeted with a flat output - no oscillations this time! I cranked my function generator to the highest voltage it could do, and lo and behold I could see the signal again, now attenuated by a factor of 100.
![]()
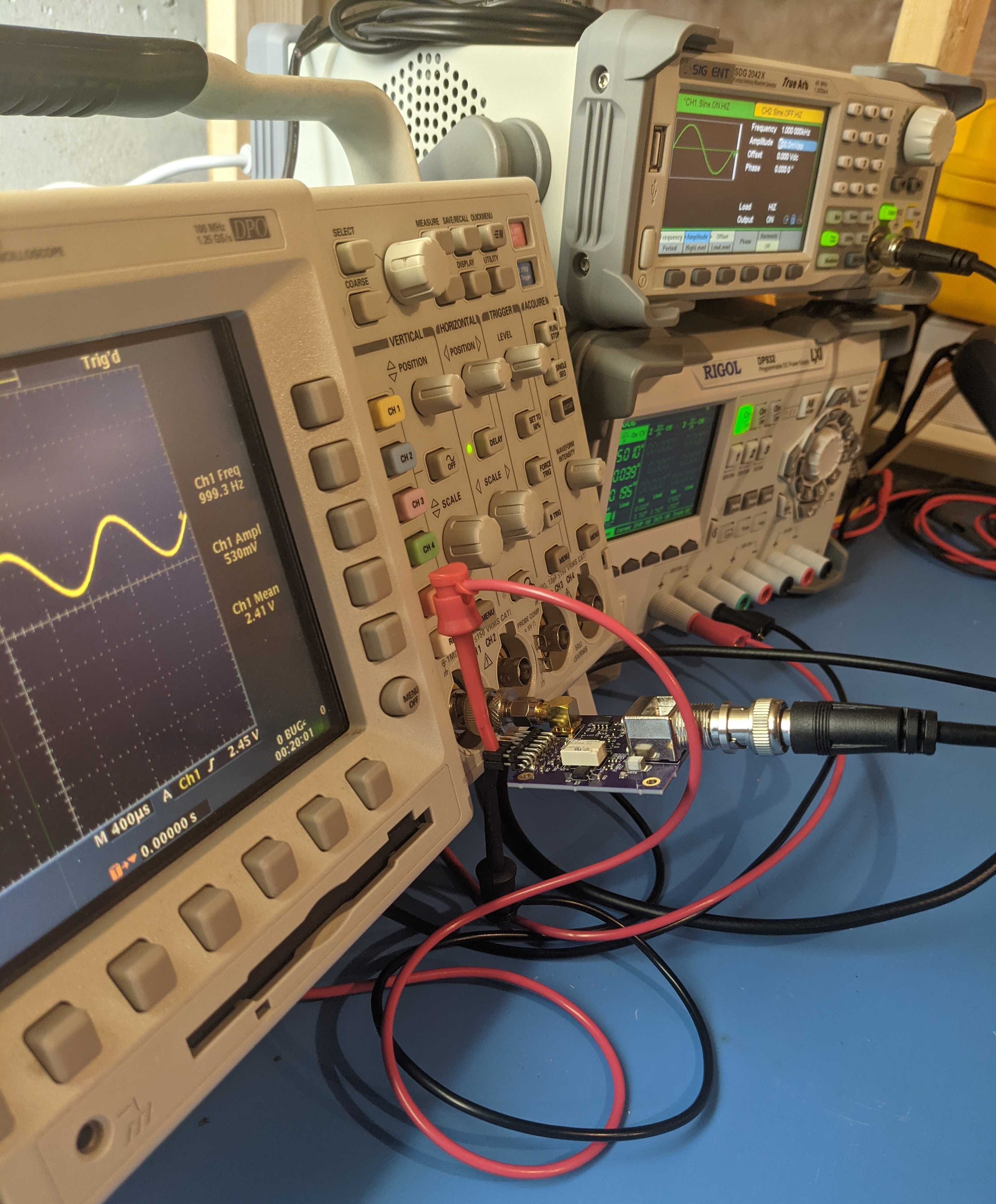
I then connected the FFE to the PGA and used the front end tester board to test the frequency response of the whole front end. I did this to avoid loading down the FFE’s buffer circuit with the high input capacitance (13 pF) of an oscilloscope input.
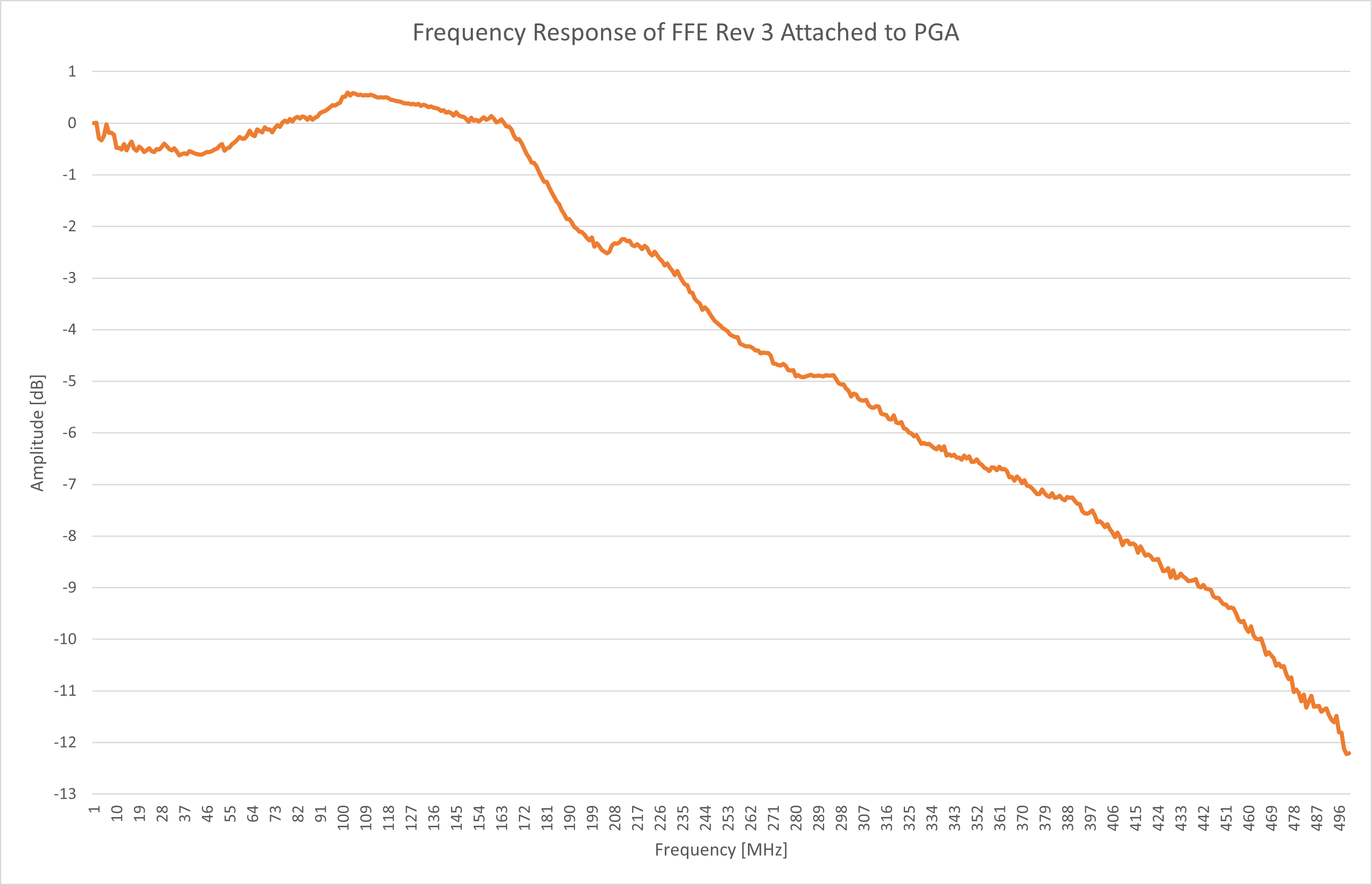
![]()
The frequency response certainly looked more promising than the previous attempts! The bandwidth was about 230 MHz, out of the 350 MHz promised by the simulations. This alone wouldn’t be too much of an issue if I scaled back the bandwidth requirement to 200 MHz. The real issue here is the flatness of the response, which is over +/- 0.5 dB when it should ideally be +/- 0.1dB. That means that on a scope with this front end, a 100 MHz clock would look 10% larger than a 32 MHz clock!
![]()
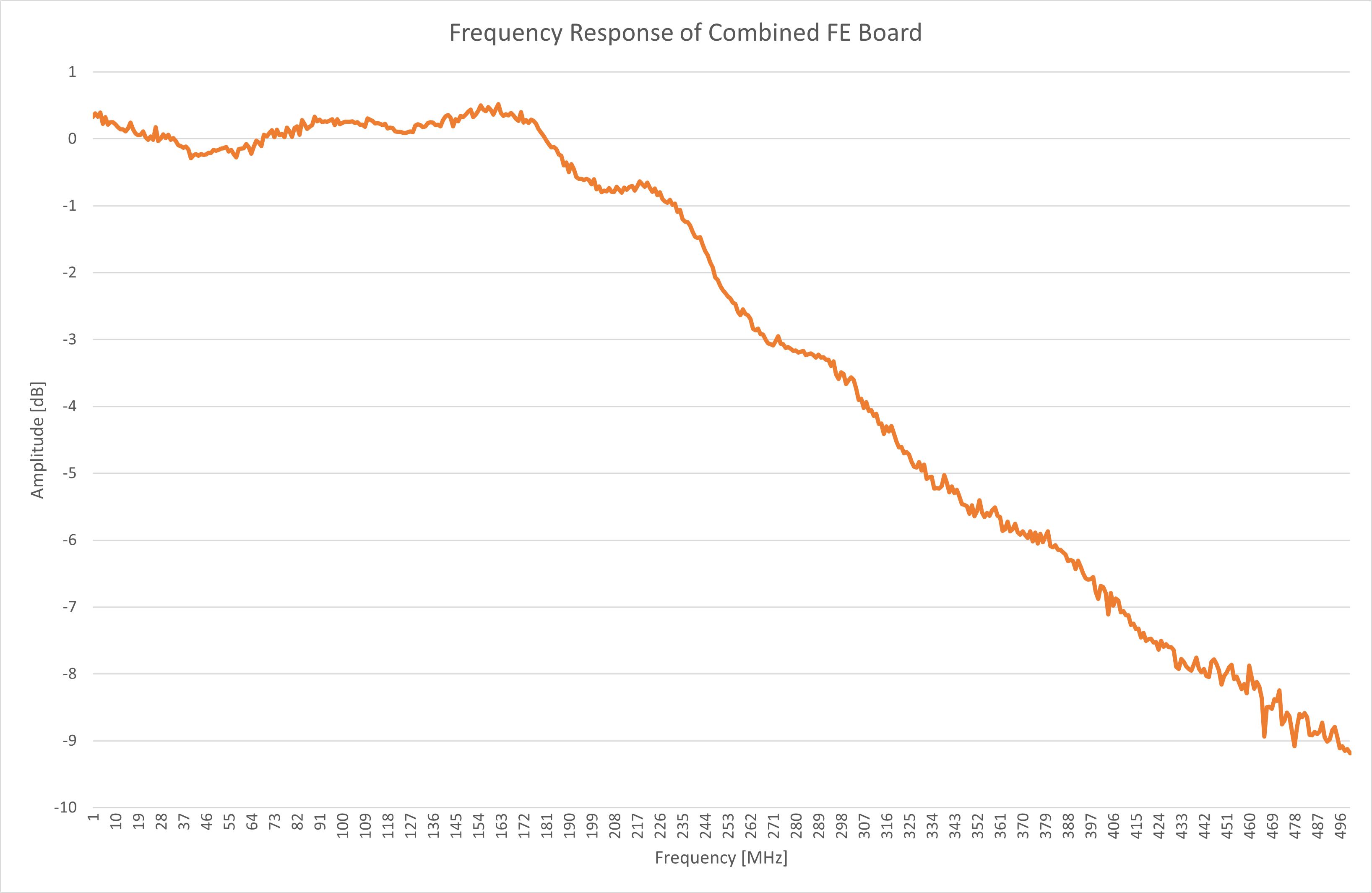
These peaks and valleys in the frequency response could have been caused by parasitics (unwanted inductance and capacitance) in the layouts of the two boards and in the connection between them. To reduce these parasitics and improve the bandwidth and flatness of the frequency response, I combined both FFE and PGA into one front end board, moving all the parts closer together to shrink the layout.
![]()
This new board improved the bandwidth to 260 MHz and the flatness to 0.25 dB. This was clearly a step in the right direction, but also showed that the likely culprits were the components on the board. I resolved to tweak the component values to improve the response later, but was satisfied enough to keep this design and continue on to a very exciting new development in this project - breaking the 1 GB/s barrier!
Thanks for giving this post a read, and feel free to write a comment if anything was unclear or explained poorly, so I can edit and improve the post to make things clearer!
-
A New Front End Architecture
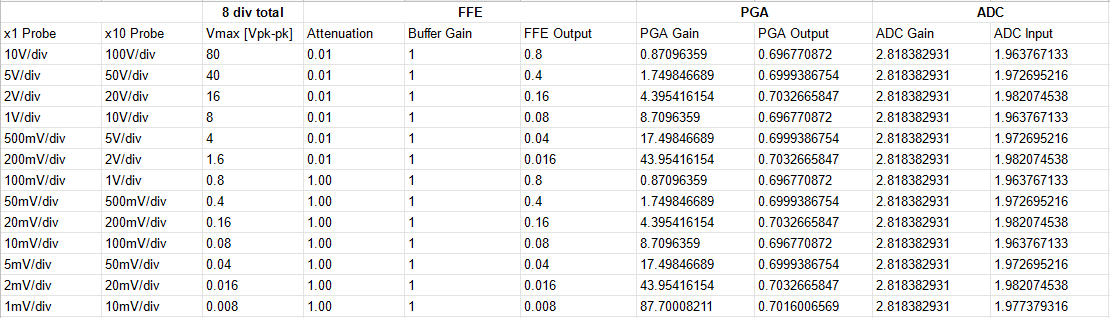
09/01/2021 at 23:59 • 0 commentsAt this point, there was one big issue with the front end. The attenuators could not be switched in without causing the whole circuit to oscillate! This issue was compounded by the maximum 0.7 V output of the PGA as well as the massive cost of the design (three relays and an unobtainium opamp don't come cheap). Since I already had to use digital gain to boost the output of the PGA, I decided to remove the opamp gain stage present in the current front of front end (FFE) board and replace it with a unity gain (x1) buffer. Using a unity gain buffer would allow me to remove one of the attenuators, as it would not need to scale the input voltage just to gain it up anyway. I would also need to use an active level shifting circuit instead of the resistive divider to avoid losing half the signal shifting it up to a DC level of 2.5V. Below is the spreadsheet I used to plan out the attenuation and gain needed for all the voltage division settings.
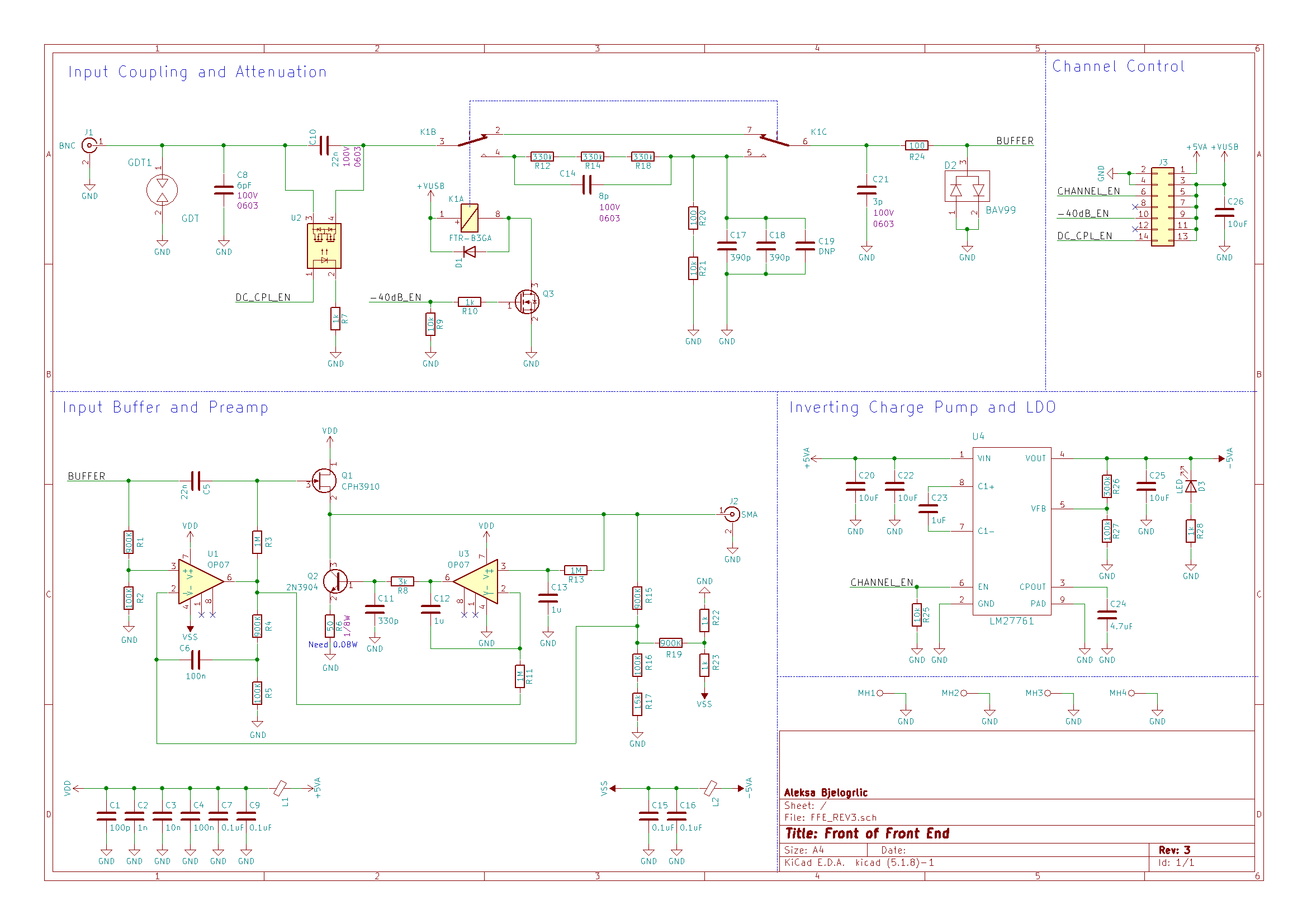
Let's take a look at the schematic, starting from the input coupling and attenuation block. I chose to remove the 50Ω termination relay to lower cost per channel since this wasn't a feature often used or provided on entry level scopes like this one. The move to one attenuator also saved another relay's worth of materials cost, and I replaced the mechanical relay used for the coupling cap with a solid state relay (U2) to further reduce cost. The input coupling cap and its relay were moved from behind the attenuator to in front of it. This maintains consistent input impedance behavior in AC-coupled mode regardless of the attenuator state, as before it would go from infinite resistance at DC to the 1 MΩ impedance of the attenuator when the attenuator was switched on.
Taking inspiration from the example oscilloscope circuit on page 34 of the LMH6518 datasheet, I used a JFET (Q1) as an AC-coupled input buffer alongside a opamp (U1) to handle the DC portion of the signal while adding the 2.5V offset needed for the PGA input. A JFET was a great choice for a front end buffer since they have very high input impedance and contribute very little noise to the signal. I used a clever circuit from page 34 of Jim Williams' AN47 application note to automatically bias the JFET at IDSS. This point is defined as the current at which the voltage between the gate and source is zero, resulting in a gain of exactly one - great news for our buffer! The circuit works by having the opamp (U3) adjust the current through the JFET using the BJT (Q2) until the filtered DC voltage at the output is equal to the DC component of the input (generated by U1) which by the definition above results in IDSS!
![]()
Hopefully this mashup of two interesting circuits makes for a working front end! Join me in the next project log where I go through the testing and results for this board and talk about the next steps I took to perfect this design.
Thanks for giving this post a read, and feel free to write a comment if anything was unclear or explained poorly, so I can edit and improve the post to make things clearer!
-
How Are The First Few Bytes?: Full System Testing
08/22/2021 at 19:53 • 0 commentsNow that the FPGA code was done, I could finally assemble and test the whole system. There were many untested blocks at this point, so each block was tested incrementally to pinpoint any issues. Once these incremental tests were done, the final test would be hooking up a signal to the front end and getting the sampled signal data back to the host PC.
![]()
The first of the incremental tests I did on the system was to turn a relay on in the front end. This would confirm that the FT2232 chip as well as the FT2 Read interface, FIFO and I2C FPGA blocks were working correctly. I figured out which bytes to send based off of the IO expander IC's datasheet and made a quick python script using pyserial to send the data (this interface on the FT2232 looks like a serial port to the PC). I executed the script and heard the clack of the relay on the front end board, it worked!
Next up, I would send a SPI command to the ADC to come out of power down mode. The ADC clock starts running when it goes into active mode, so I programmed the FPGA to blink the LEDs if it gets a clock from the ADC. This would confirm that the SPI FPGA block and ADC board worked. Some more datasheet searching and a new line of python later, I was greeted with a well-deserved light show from the (too-bright) LEDs on the digital interface board.
I tested the maximum transfer rate next. To do this, I lowered the clock generator's frequency from 400 MHz (theoretical maximum throughput of the FT601) down until the FIFO full flag (which I tied to an LED for this test) was not set while running transfers using FTDI's Data Streamer Application. This resulted in a consistent data throughput of 370 MB/s. This also verified that the FT6 Write block was initiating transfers correctly when the requests came in from the host PC.
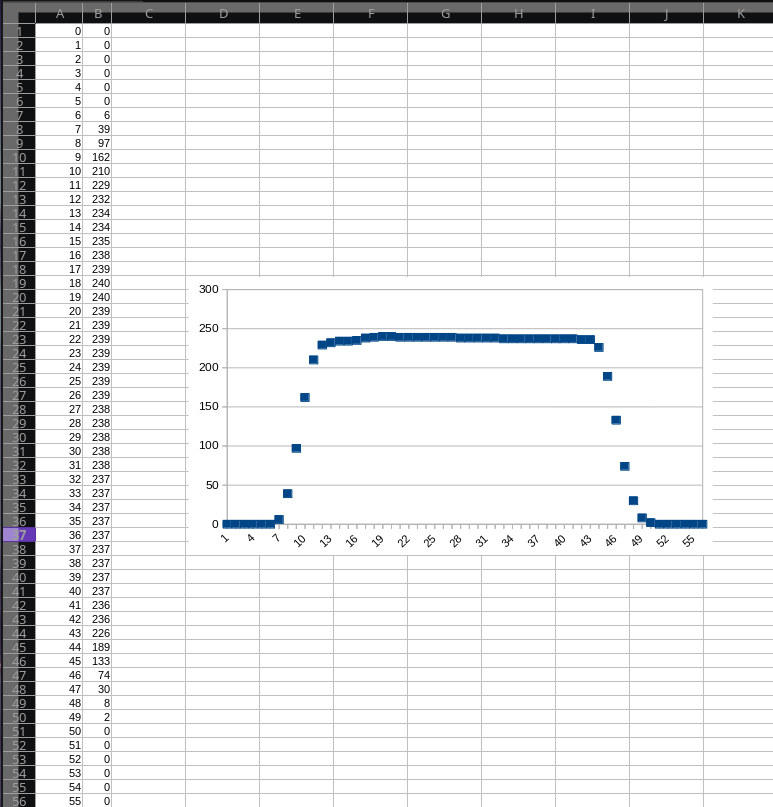
Up to this point, I didn't check the actual data coming in, only that the transfers were happening. I enlisted the help of a more software-savvy classmate (this scope would become our capstone project in a later term) to modify the data streamer code to dump a csv file from the data received. I then set the ADC to output a ramp test pattern. Since this pattern was generated inside the ADC, it would test only the FPGA blocks and not the front end. I captured the data and got what i expected: a count up from 0 to 255 and back to 0, over and over again. I did a basic check through the file and found no missing counts, this meant the transfers were completing smoothly with no interruptions in the FIFO or in the USB interface.
![]()
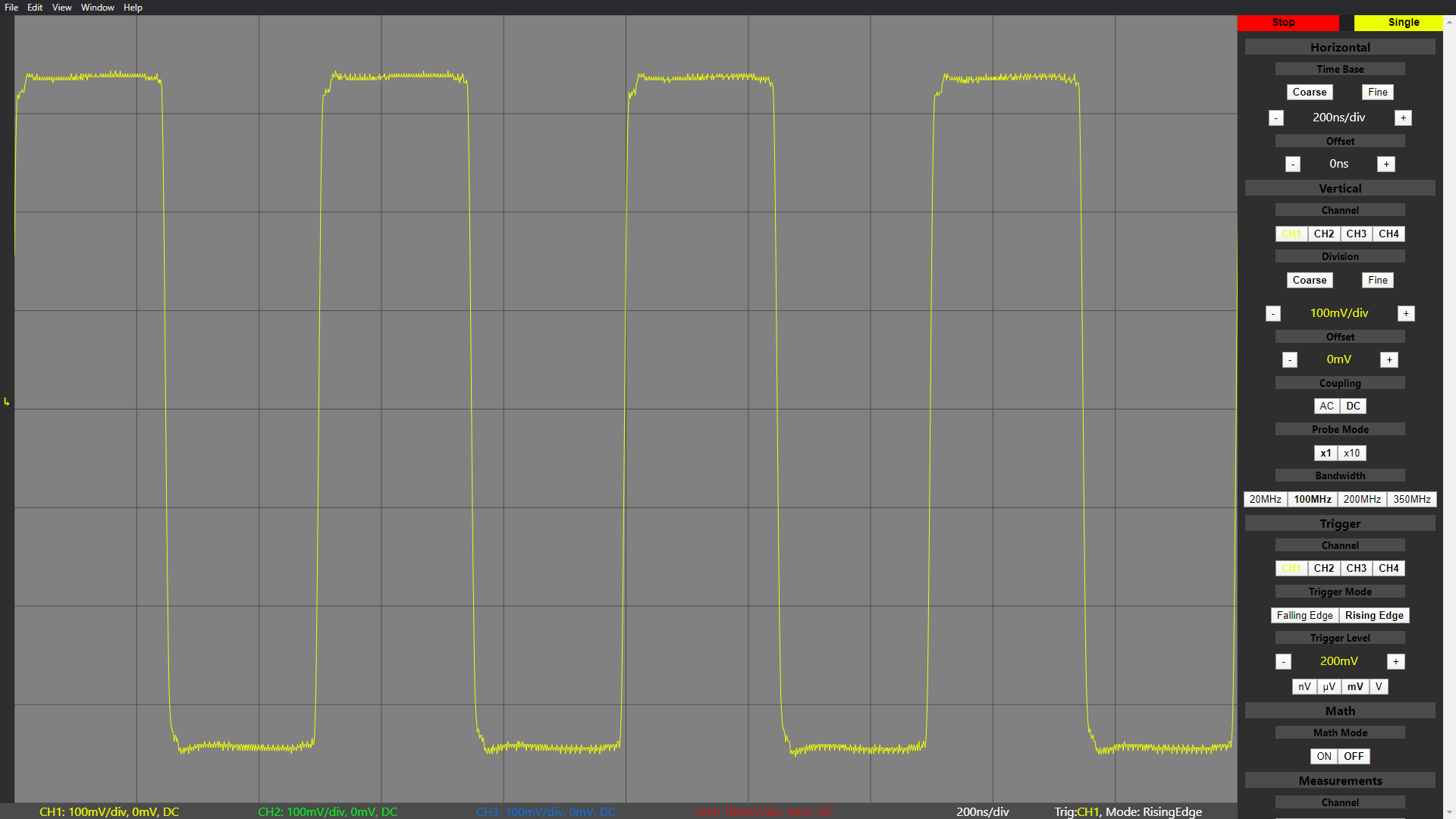
Finally, I hooked up my function generator to the front end, got together the set of commands needed to start sampling and sent them to the ADC. This would be the final test, a real signal in and sampled data out.
![]()
WE HAVE A PULSE! IT LIVESSSS! I was very happy to see the whole system working, but it had a long ways to go to meet the goal of this project. First of all, the front end still only supported a select few voltage ranges since the attenuators didn’t work. Secondly, the ADC’s sample rate was limited to 370 MS/s (of the 1 GS/s it was capable of) by the FT601’s maximum sustained transfer rate of 370 MB/s. And of course, software needed to be made to stream, process and display the data in real time. In my next blog post, I’ll recount how I fixed the front end issues and lowered the system’s materials cost with a new architecture!
Thanks for giving this post a read, and feel free to write a comment if anything was unclear or explained poorly, so I can edit and improve the post to make things clearer!


 After placing *wayyy* too many 0201s, here it is next to the module its replacing!
After placing *wayyy* too many 0201s, here it is next to the module its replacing! And finally, the purely purple prototype! Follow this project to catch the next mainboard revision, where we will be integrating Thunderbolt in a supremely janky way!
And finally, the purely purple prototype! Follow this project to catch the next mainboard revision, where we will be integrating Thunderbolt in a supremely janky way!