 mick
mickI know we have some data accessible in the virufy repo, we need to process this data and workout the label scheme and get it ready for training.
Downloading the samples
First I need to create a notebook to do the data prep, this will download the samples, sort, filter etc and store them in an AWS S3 bucket to be used for training. Here I'm pulling down the samples and preparing the buckets, I'm also starting to work on a csv data set for tyhac to use later:

Here I'm starting to sort the data and look at the shallow and heavy cough samples. This notebook is outputing a custom tyhac dataset rather than using the virufy schema. While the virufy schema is good, it contains alot of extra information I don't want right now and makes it more difficult to merge data. Designing a custom basic data format for tyhac makes it easier to translate into.
I found that the librosa package didn't really support formats other than wav files, the samples I've found are a mix of webm, ogg and wav. So I need to convert the files before we can create images of the audio samples:

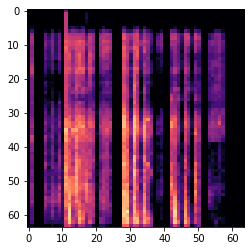
To create an image of an audio sample I'm using mel-spectrograms, this was what I found during my research and seems to be common. We can also see examples of this in the virufy repo which is helpful:

One of the generated mel-specs:
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.