 mick
mickThere just isn't enough data, I've combined both the datasets from virufy and coughvid and there is little data, the early results from fastai are better but still not great.
More data
If you look at the datasets in the source repo from virufy you'll notice the coughvid dataset has lots of audio samples. People speaking, breathing etc, what is worth noting is that there is both shallow and heavy coughs. I noticed this early on and I recall reading a research paper where another reseacher impoved the results by including both. I've redeveloped the data preperation notebook to capture both:

Imbalance
This is not an uncommon problem, often you will have a dataset where you have more of one type than the other. In this case, we have way more negative samples than positive so we need to try and work around that. We've added more data with the heavy and shallow coughs but some research shows weighting the samples can help. I found a nice examples of weighting, here we'll use that to help out:

Because we've spent time getting our data visualization down ;) we know we want to check this out before committing:
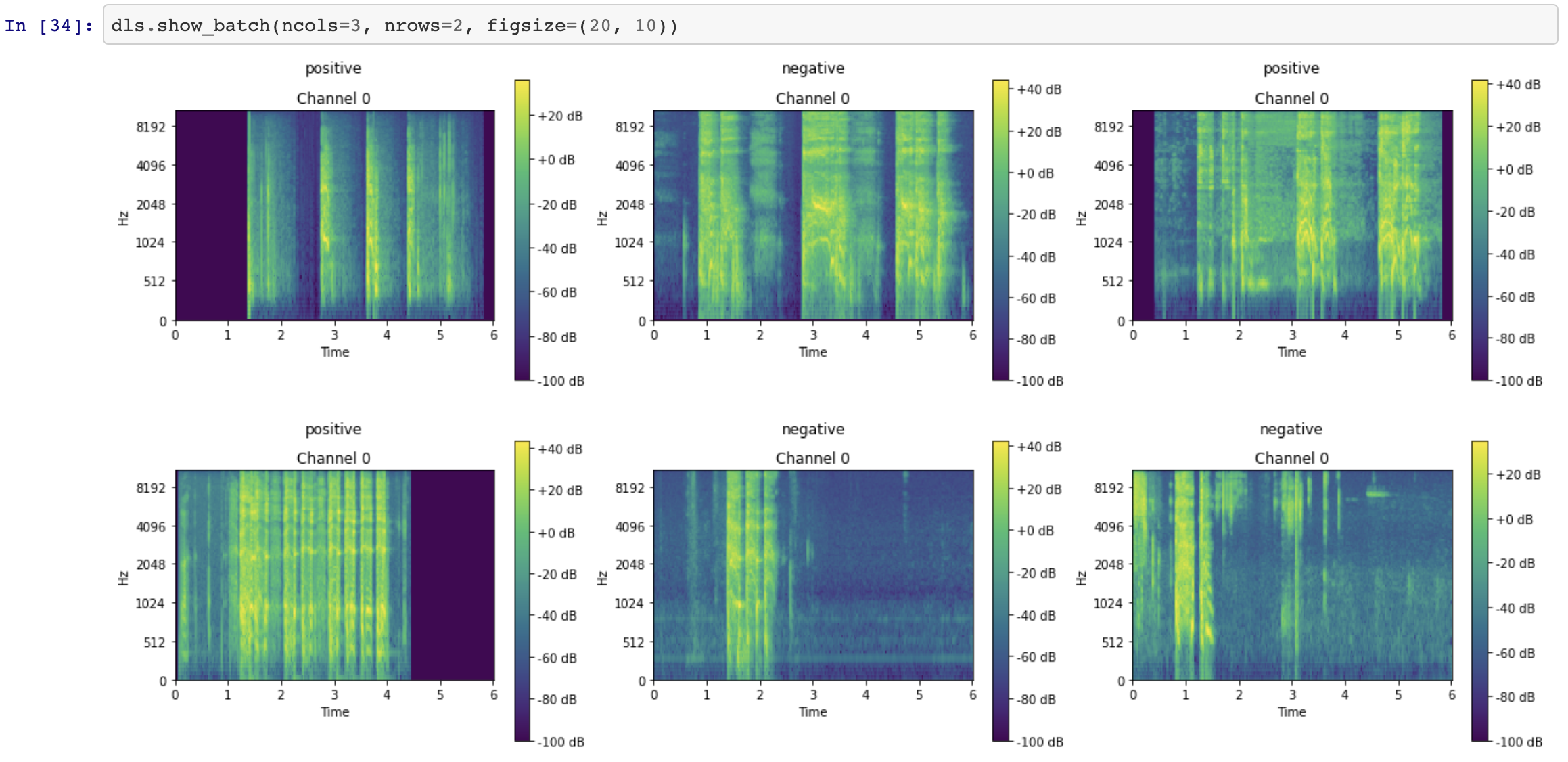
We can see the weighting appears to work, how cool is that! What I'm looking for is a more evenly distributed sample during training as above.
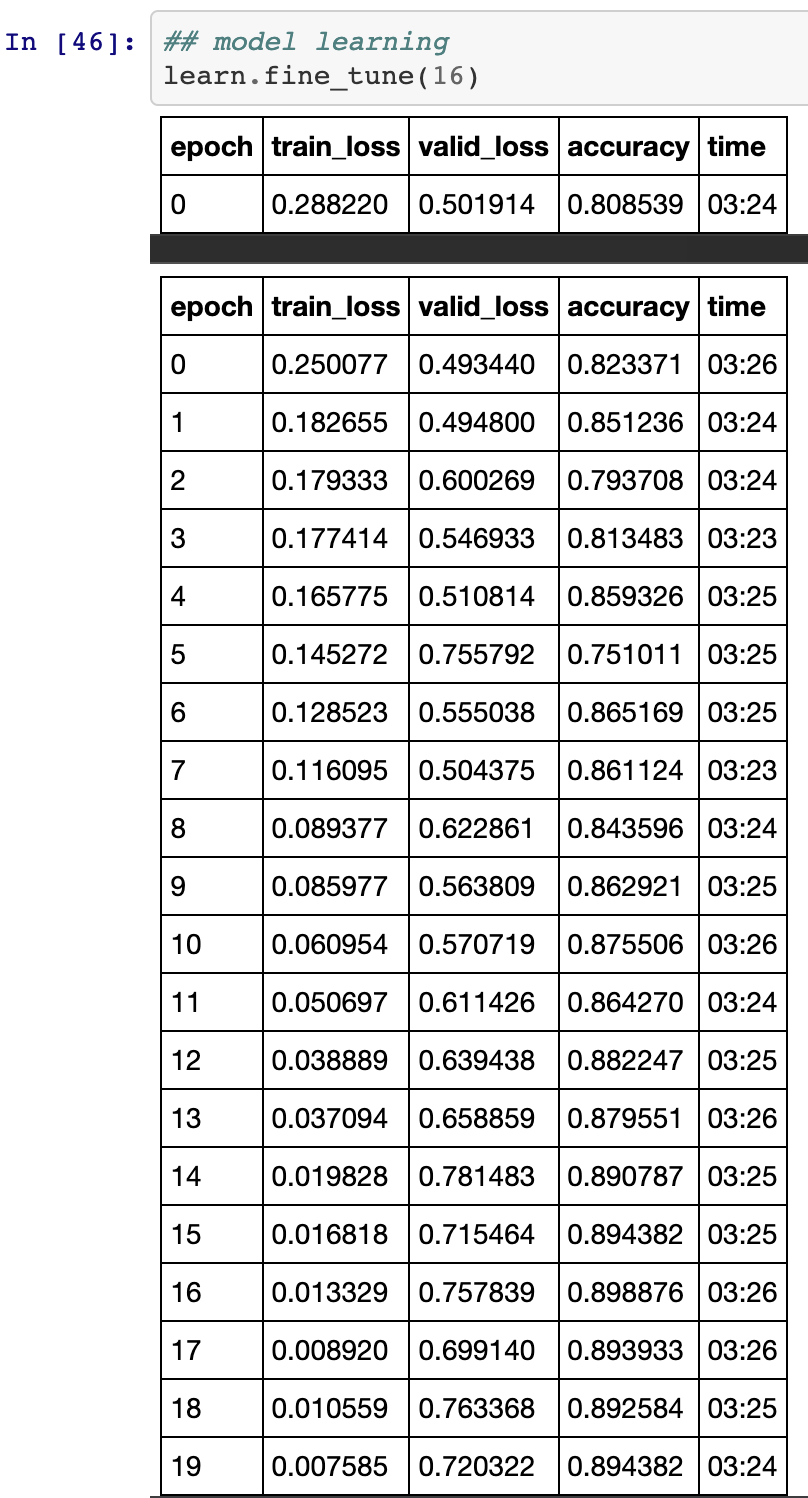
Retraining we more data and weighting:
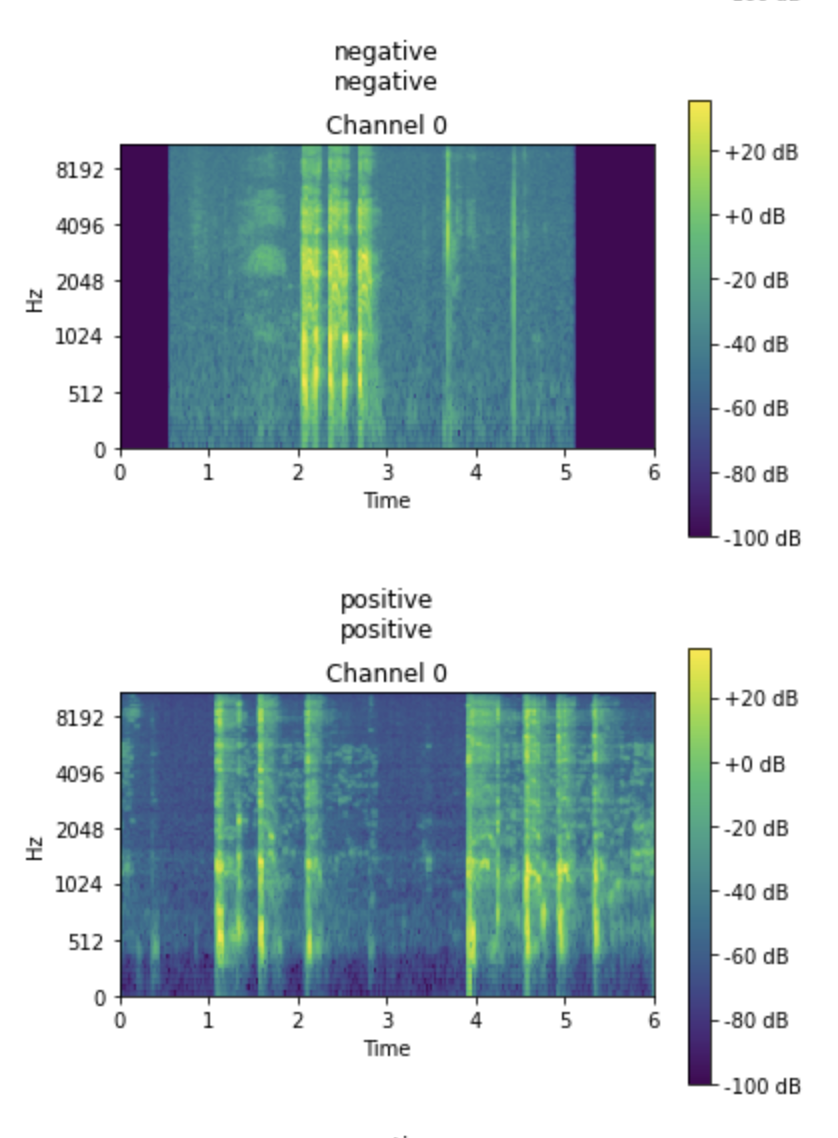
Viewing some of the results, we can see the actual label vs the predicted label, not all will be correct but it's something:
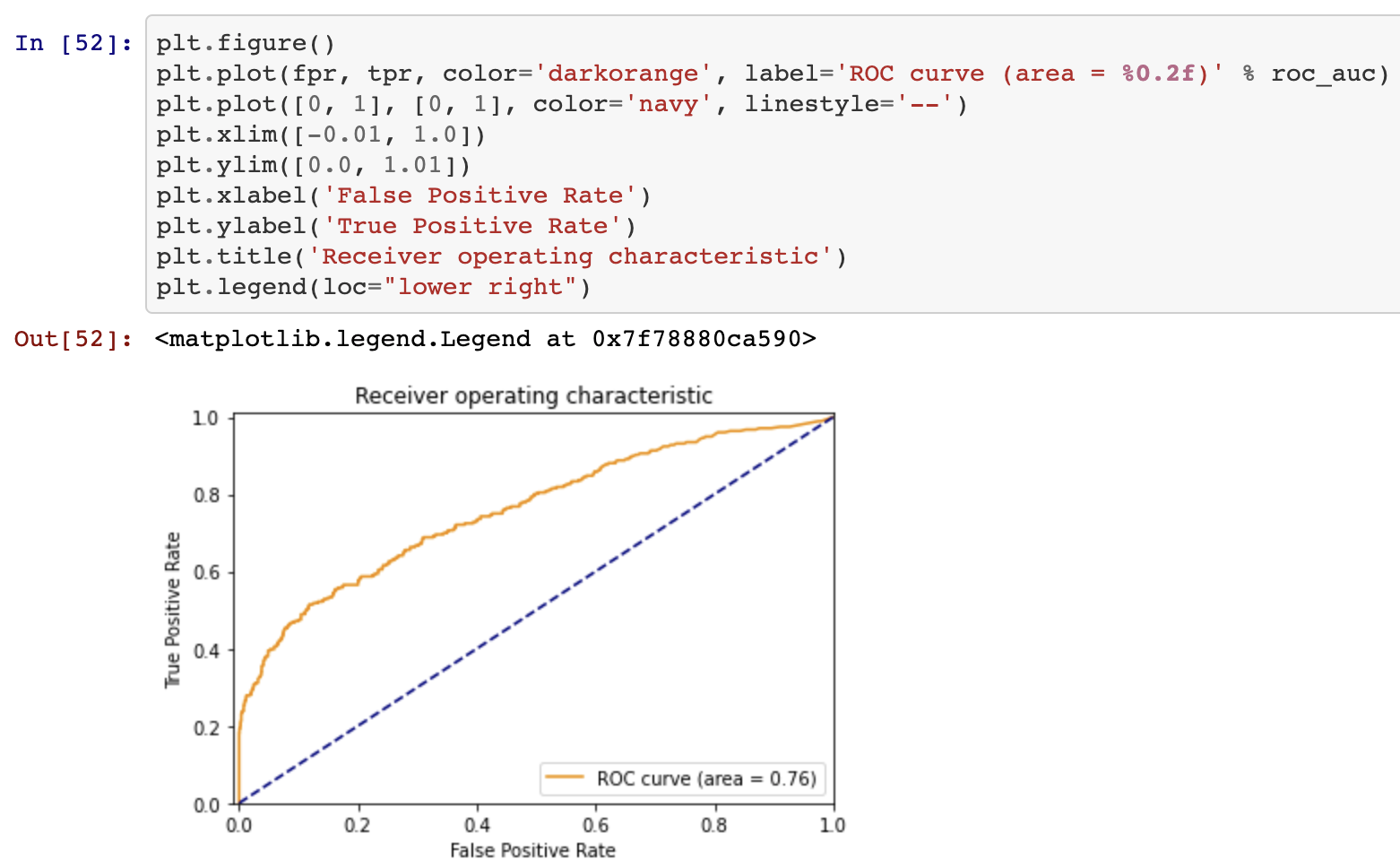
Woooo!!! An acceptable RoC!!!
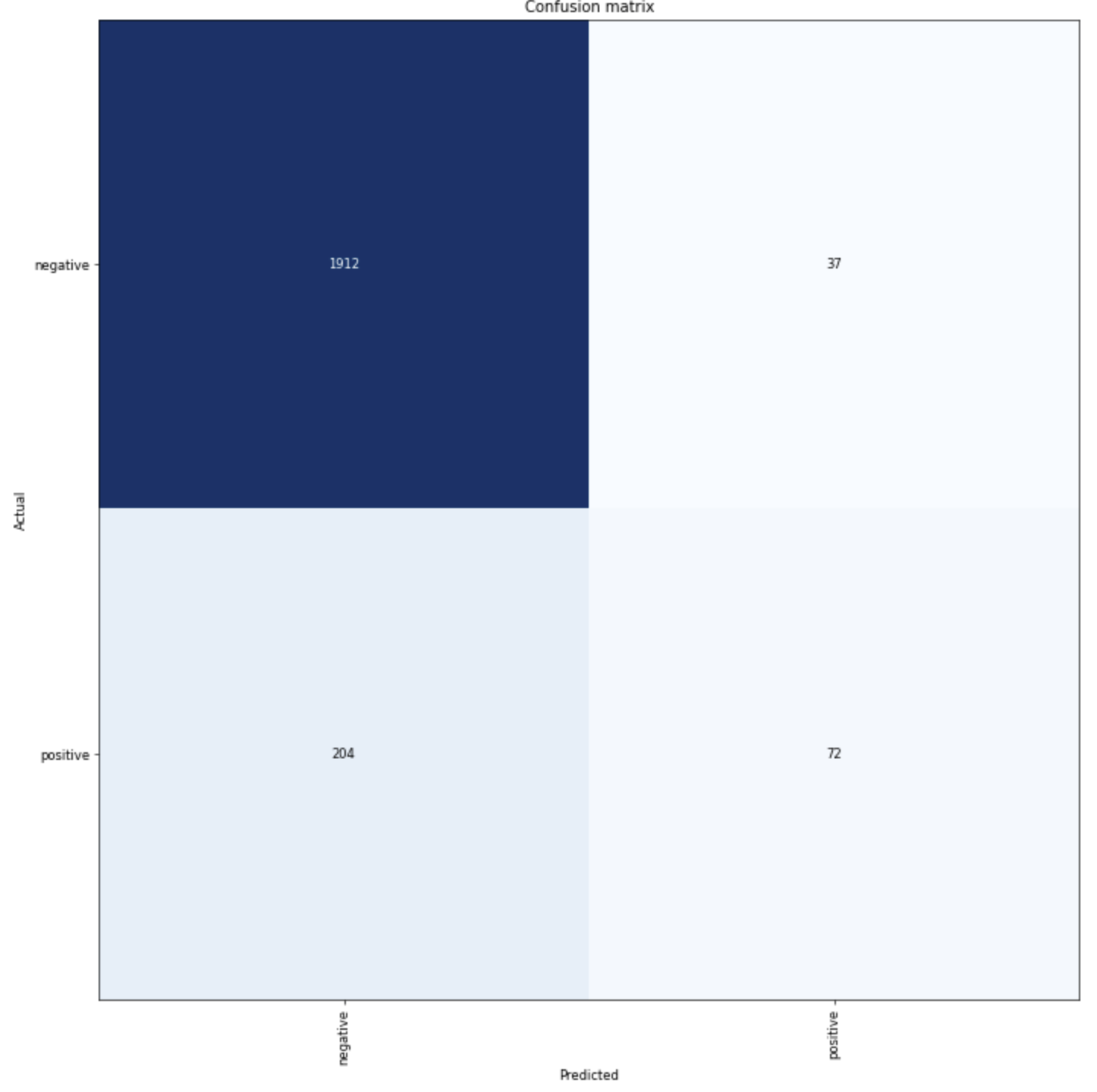
Not a bad confusion matrix, could be better, could be worse:
Thats it for model training, I have a working set of notebooks and a workflow to retrain the model wit
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.