 Splendide_Mendax
Splendide_MendaxPlease check the detailed information in the "INSTRUCTIONS" section below.
0%
0%
AMB21/22/23 TensorFlow Lite - Hello World
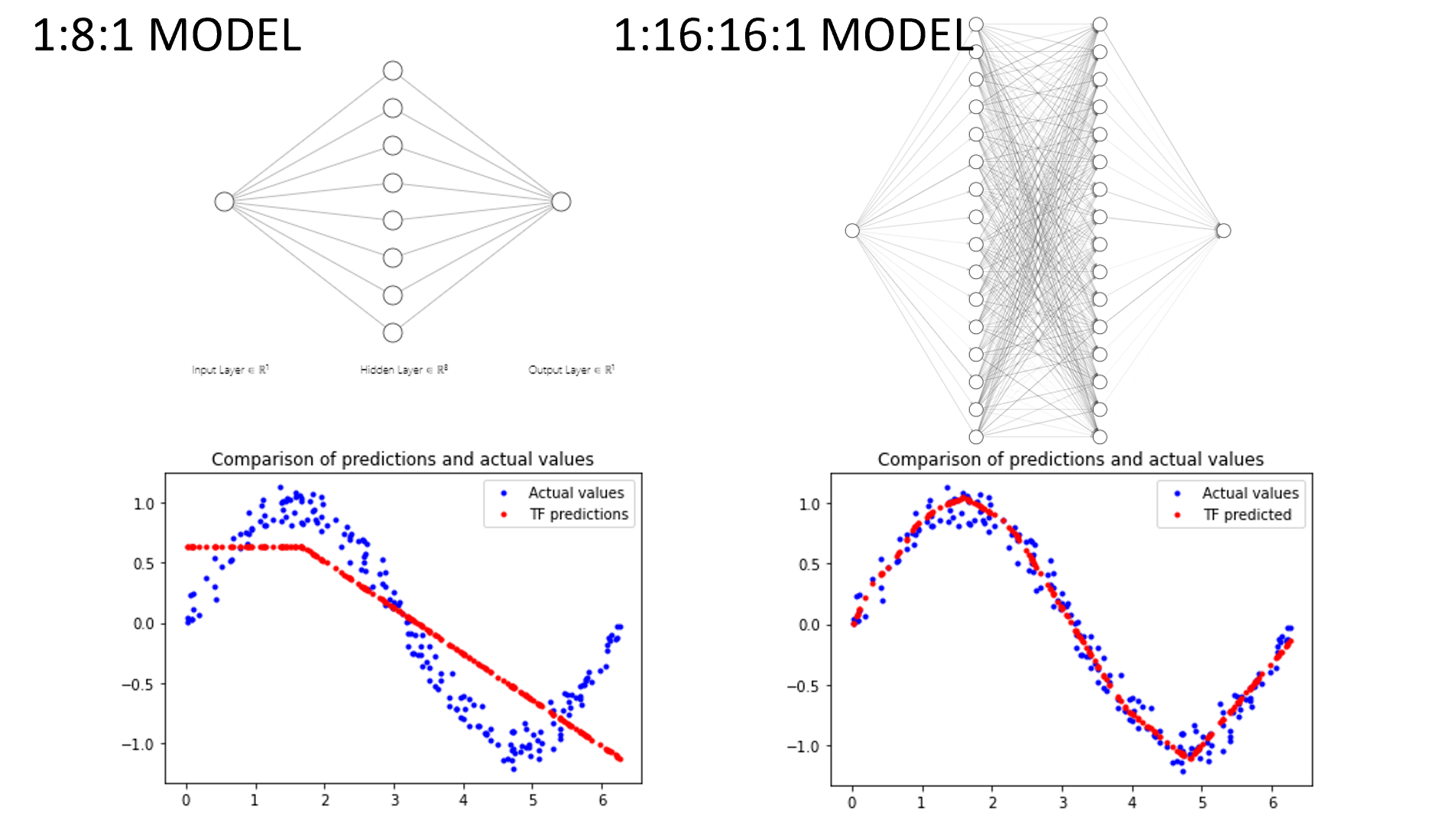
This project demonstrated how to apply a simple machine learning model trained via Google Tensor Flow, and transfer it to AMB21/22/23 board
Become a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests


 andrew.powell
andrew.powell
 RAMKUMAR R
RAMKUMAR R
