 jaromir.sukuba
jaromir.sukubaAdam Fabio pointed out there could be a problem accepting 1kB challenge entry with HD44780 LCD, containing fair bit of character generator ROM. Though I have no problem with the HD44780, I'll try to rework my project to not use HD44780 or similar LCD driver with built-in character set - so, I have to use graphical LCD and construct character bitmaps from resources on my 1kB constrained FLASH.
I removed demo BF programs from FLASH and its copy routines, so I was able to obtain approximately 170 bytes of FLASH. But that seems too little for ASCII table character bitmaps - considering the usual font 5x7
 I'm kinda stuck, as every single character needs 5 bytes of FLASH and there is at least 96 of them, and 480 Bytes just for character bitmaps is way too much for this project. But I'm too stubborn to give up the display output.
I'm kinda stuck, as every single character needs 5 bytes of FLASH and there is at least 96 of them, and 480 Bytes just for character bitmaps is way too much for this project. But I'm too stubborn to give up the display output.
I could strip down the ASCII subset, but still, 170 Bytes is just 34 characters, not enough for alphabet and numbers, not to mention special symbols, so much used in BF. 64 or at least 56 characters would be better. That's still too much of FLASH consumed.
I noticed that having full 8 bits for one character btmap column is too much luxury. That is 256 combinations and many (most?) of them are simply unused. I decided to create the 16 most versatile combinations of pixels (vectors), so I can encode two columns into single byte. If I'd decrease symbol width to 4 columns (4x8 pixels characters) I can encode whole character into two bytes + 16 bytes of column vectors. For 64 characters it is 128 Bytes for character generator and 16 Bytes for vectors, consuming 144 Bytes. Much better!
I started by drawing vectors I would expect to appear most frequently.
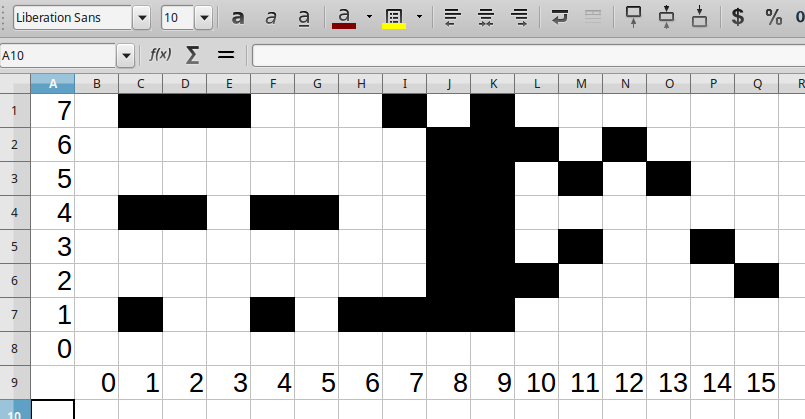
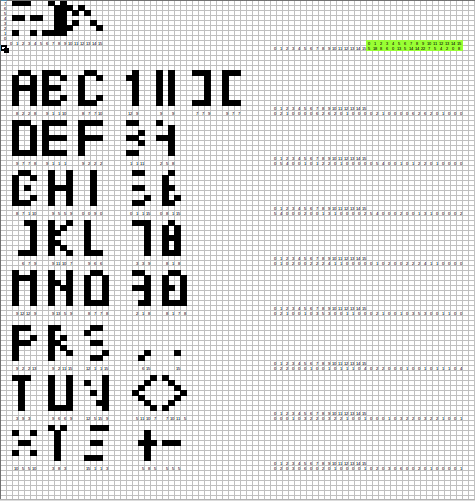
The first eight rows are just combinations of black dots at lines 1,4 and 7, the rest of vectors are the ones I expected to be common for alphanumeric symbols. I did my best to construct character table from it, though looking a bit weird.
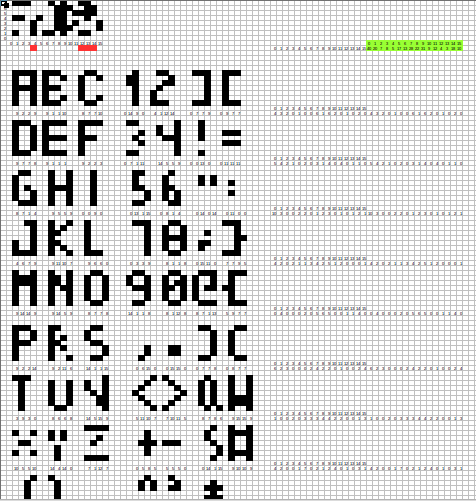
I replaced vector 14 with something more usable and character set looks a bit better now


Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.
Thanks for sharing the file so quickly Jaromir, but I didn't see your share until after I'd already made my own! LOL...
For anyone who doesn't have libre office, or just likes google sheets, I set up a version of this at:
https://docs.google.com/spreadsheets/d/1u6zqFNge6mukWzv72dKhRjwrWkqPM1-MtmagKRP4_X4/edit?usp=sharing
just to play around with. You should be able to easily copy it into your own google account. I haven't finished mine, but I could spend hours and hours screwing with it...
There should be some way to show which vectors are used the least.... So I've added a count of the use of that vector on the top line. It will incorrectly pick up any mention of a number such as the label for the character 1, so be sure to label the numbers with "1" (in quotes) instead.
And you can show which characters use each vector. E.g. I added a formatting rule that turns any cell with a $ red, then we can temporarily change the # which makes cells black into a $ in the vector and get a quick reference for which characters use that vector.
I'm going to have such fun messing with this... best puzzle game around! Thanks!
Are you sure? yes | no
If you modify vector #10 to darken in bits 3 and 5, it will improve the appearance of the "3" and the "B", then you can change the last nibble of the "C" to use #7 for the last vector which will still look fine.
Are you sure? yes | no
As far as I can see, vector #6 is only used for the last nibble of "R" so why not turn on bits 2, 5 and 6? It would really improve it.
Are you sure? yes | no
Can you share your source file? The spreadsheet? I want to play with this.
Are you sure? yes | no
Yes, I uploaded it into files section right now.
Are you sure? yes | no
Thanks, I changed it as per you input - the K is affected too, as well as < and > and #. I have to decide which one to keep, but your suggestion is actually pretty good too, thank you!
Are you sure? yes | no
Wow, pretty awesome! How much code does the vector lookup and character generation take? Wondering if its something that I could borrow for OKOS, right now I'm using 40 glyphs from the 3x5 font in 80 bytes, with another 50 bytes to do table reads, unpack, and send to i2c to a rom-less oled display.
Are you sure? yes | no
Thanks. My font + display routines are going to be slightly bigger in consumed bytes, but I really wanted font larger than 5x3 :-) Perhaps it is not suitable in unchanged form due to constrained FLASH budget of your project, you may try to adapt similar compression scheme for OKOS, though.
Currently, the tables for 64 glyphs take 144B, the unpack + display routines will be small, I assume something like 20-30B. Due to simple compression scheme, unpack is nothing more than nibble swap and table read.
The display routines are not yet on github, I'm working on it; the display took longer to arrive than I anticipated.
Anyway, 5x3 or 4x4 fonts are possible solutions too, I just wanted to achieve another way to achieve the goal.
Are you sure? yes | no
Can't wait to check it out. Yeah, generating a 4x8 is way cooler than squeezing into a 5x3 or 4x4 :)
Are you sure? yes | no
have you considered a 4x4 font? it keeps all the BF characters unique and easy to read. http://fonts.webtoolhub.com/font-n19131-pixel-4x4.aspx
Are you sure? yes | no
I wonder if it would work better with a 3x5 font.
Are you sure? yes | no
Like this one:
Normally it's 2 bytes per character, but with your approach, that could be greatly compressed.
Are you sure? yes | no
Ah, sorry, that's the 4-color version, to get the 2-color, simply make the light gray white, and the dark grey black.
Are you sure? yes | no
I used 3x5 font in one of my projects (Z80 emulator running CP/M, not documented here yet). Problem is that such as low-res font can't tolerate any pixel changes - move one pixel and you get completely different character. My compression method is "lossy" - it relies on fact you can "bend" the character somehow and still get readable output. On the other hand, with 3x5 font you have less combinations of pixels in columns, so perhaps less vectors, not sure.
There is possibility of other compression methods, not just vertical vectors, but one could try horizontal ones, or dividing the character bitmap into areas (by 2x3 pixels or something) and finding predefined sub-bitmaps here (the same as vector thingy, just not in single line) - or even combination of both.
This is where optimizing in spreadsheet editor goes way too boring, some more software automation would be needed. At first I planned to write some software helper, but for this simple case spreadsheet was good enough.
Are you sure? yes | no
I wonder if you could just take a set of ready letters, and automatically split it into shapes that you would then XOR to get the letters. I can't think of a way to do that, other than solving a nasty set of equations modulo 2, though.
Are you sure? yes | no
This is great work! It's kinda like finding the Karhunen–Loève transform by hand. Well done.
Are you sure? yes | no