 Yann Guidon / YGDES
Yann Guidon / YGDES20230926 : Read the (French) article for free at https://connect.ed-diamond.com/gnu-linux-magazine/glmf-260/yams-encore-un-autre-algorithme-de-tri
..................................................................................................
It all started with page: The Sorting Demon after I watched too many sorting videos and related algos.
My programs sometimes have unusual data input requirements so I'm not too concerned about "in-place" operation or stability for example, and since resorting to external sorting programs can become a hassle, it can make sense that I finally invest a bit of my time on this subject. My main concern is #PEAC where the big scanning algo must manage huge files (up to 150GB ?) and the sort operation is a bit... cumbersome.
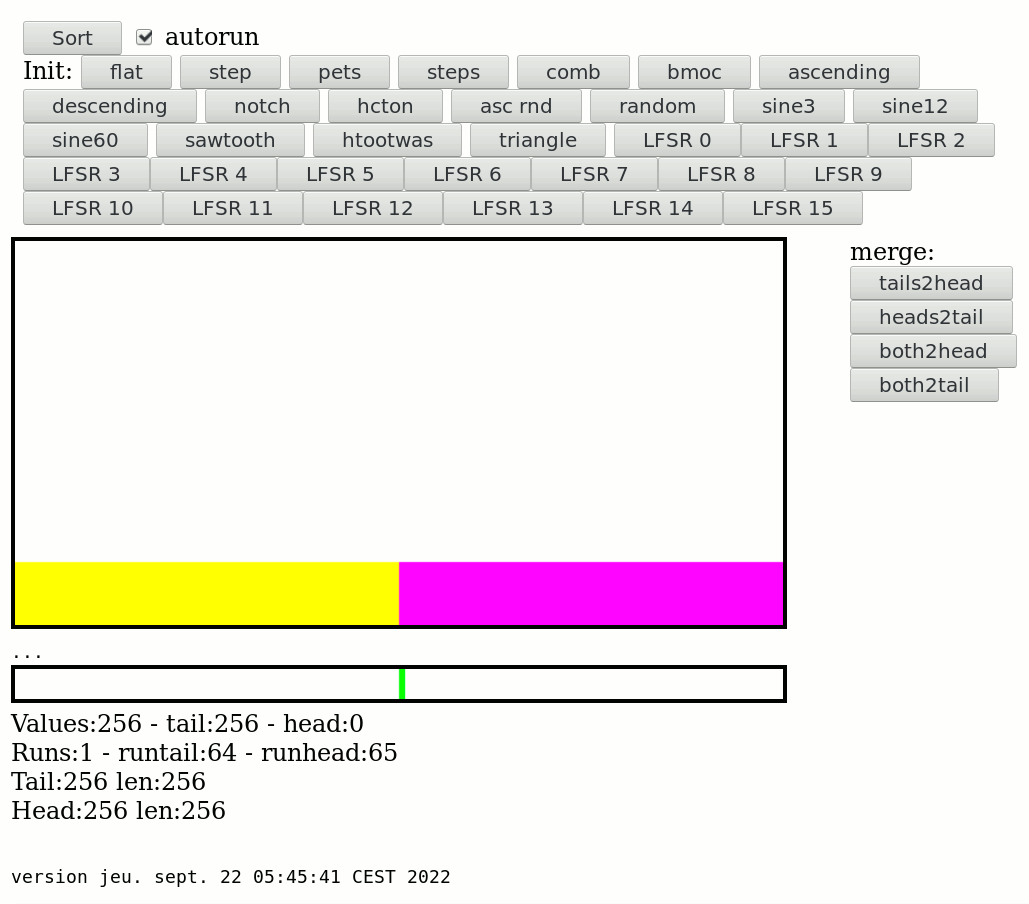
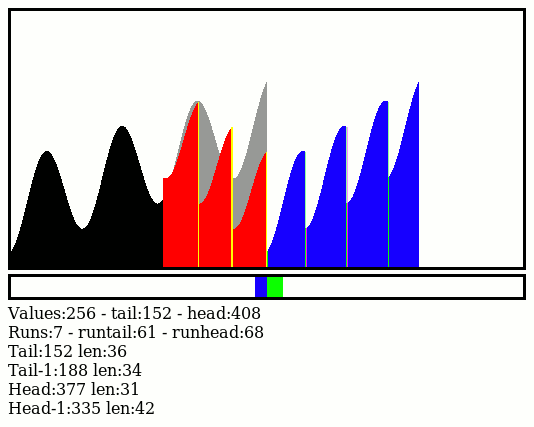
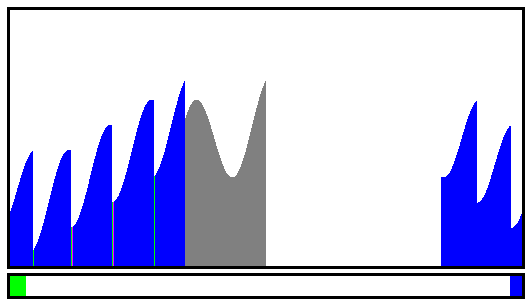
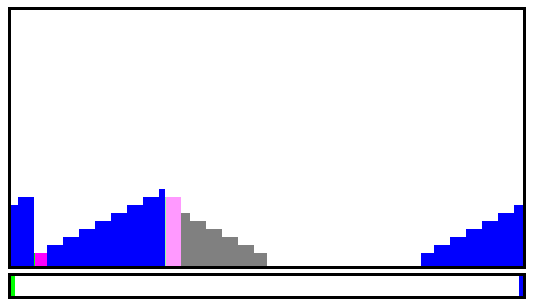
I had a feeling that a good first step would be to split the file in 256 chunks, each sorted independently, but it would be even better if I can further pre-sort the chunks while writing them to disk. I can use about 14GB of buffers, or 56MB per chunk, and I can pre-sort data while scanning or combining.
Using a straight binary format further speed things up for the combining algo and keys can be sorted by full 32 or 64-bit numbers, not characters with Big Endian. Partial chunks, with sorted data, could be split in various sequential files that an external sort program could then merge-sort. Even better: the main combining program can merge-sort the sub-chunks while reading the whole stream, thus removing the need for any external sort...
So the best top performance is not the goal here. I'm not sure you'll find mind-blowing tricks, look at Timsort for that.
-o-O-0-O-o-
Logs:
1. First steps
2. Memory re-organisation
3. Has anybody...
4. Back to basics
5. slow progress
6. Well, no but yes !
7. Where to put the data in the first place ?
8. All in place
9. Latest code
10. Finally getting to the heart of merge sorting
11. Latest shower thoughts: it's just a dumbed down Solitaire
12. Another little optimisation
13. Latest.
14. YALO! (Yet Another Little Optimisation)
15. Landing on all 4s
16. Choosing the next move
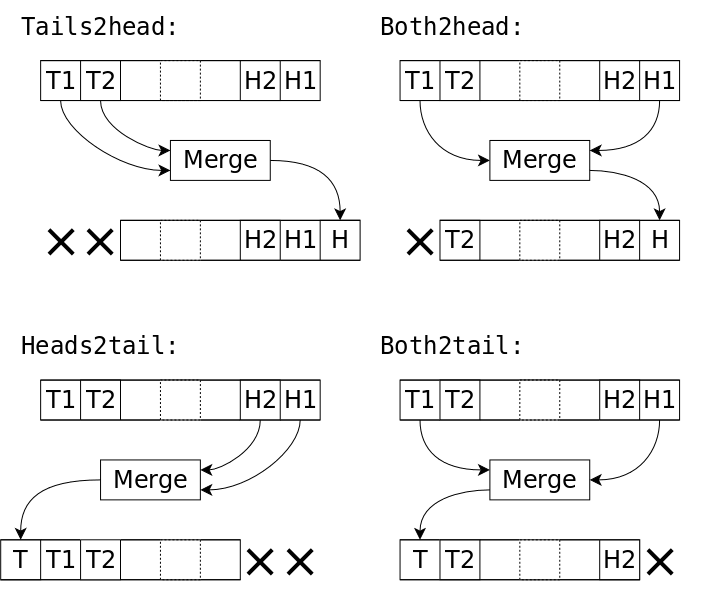
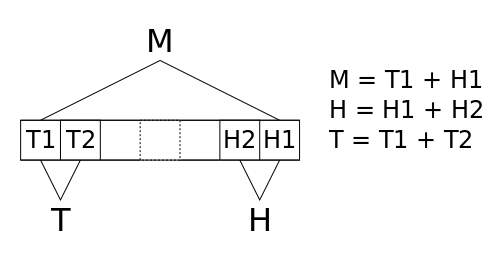
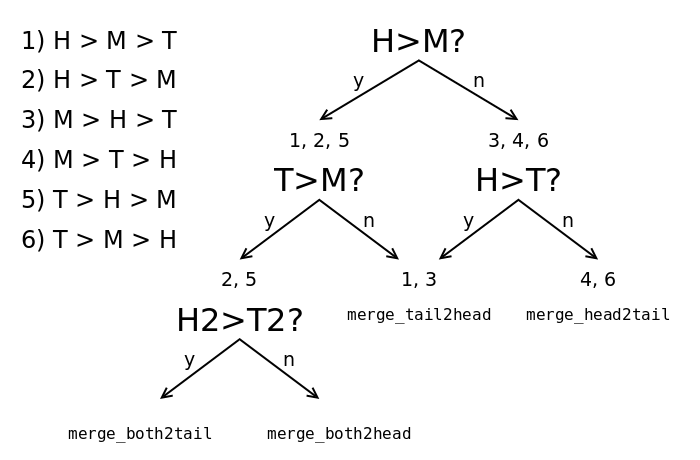
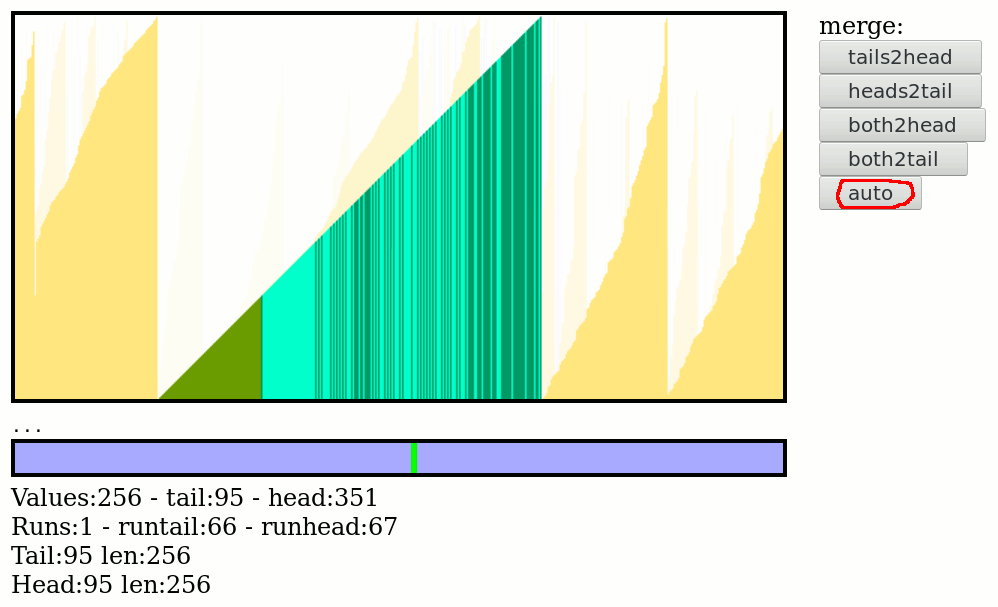
17. Better sorting
.
.
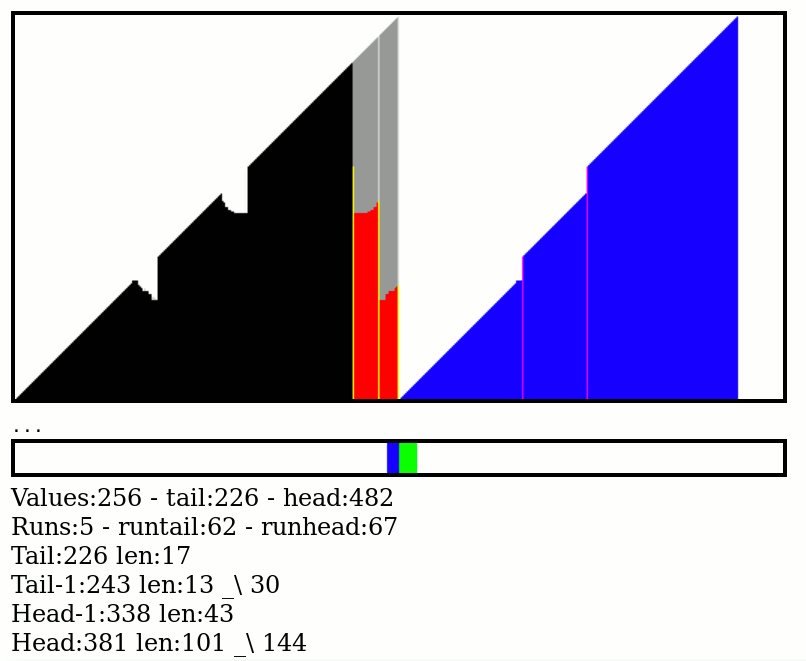
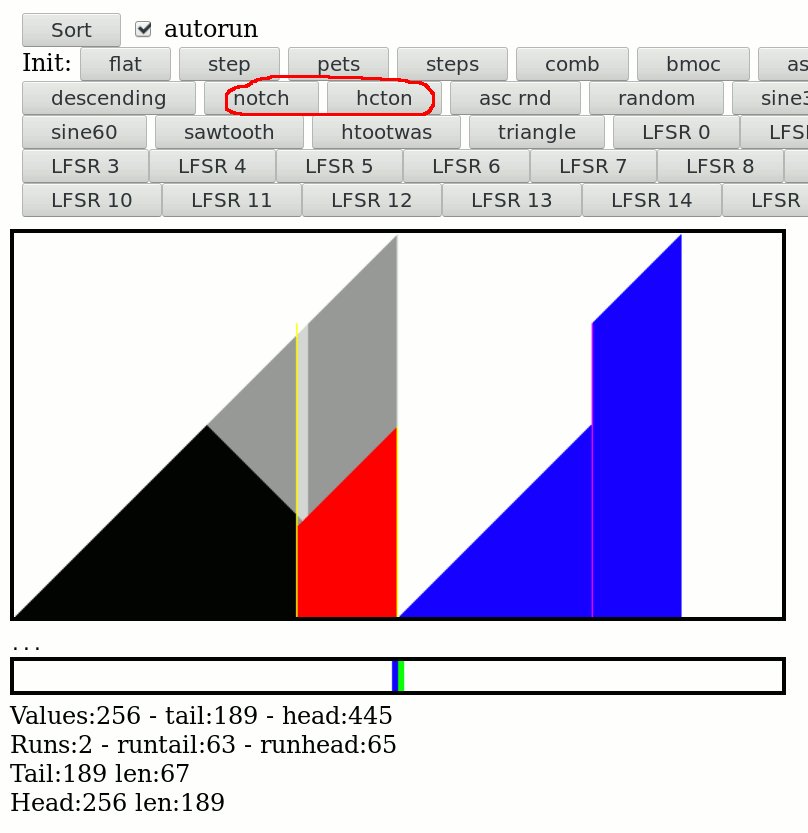
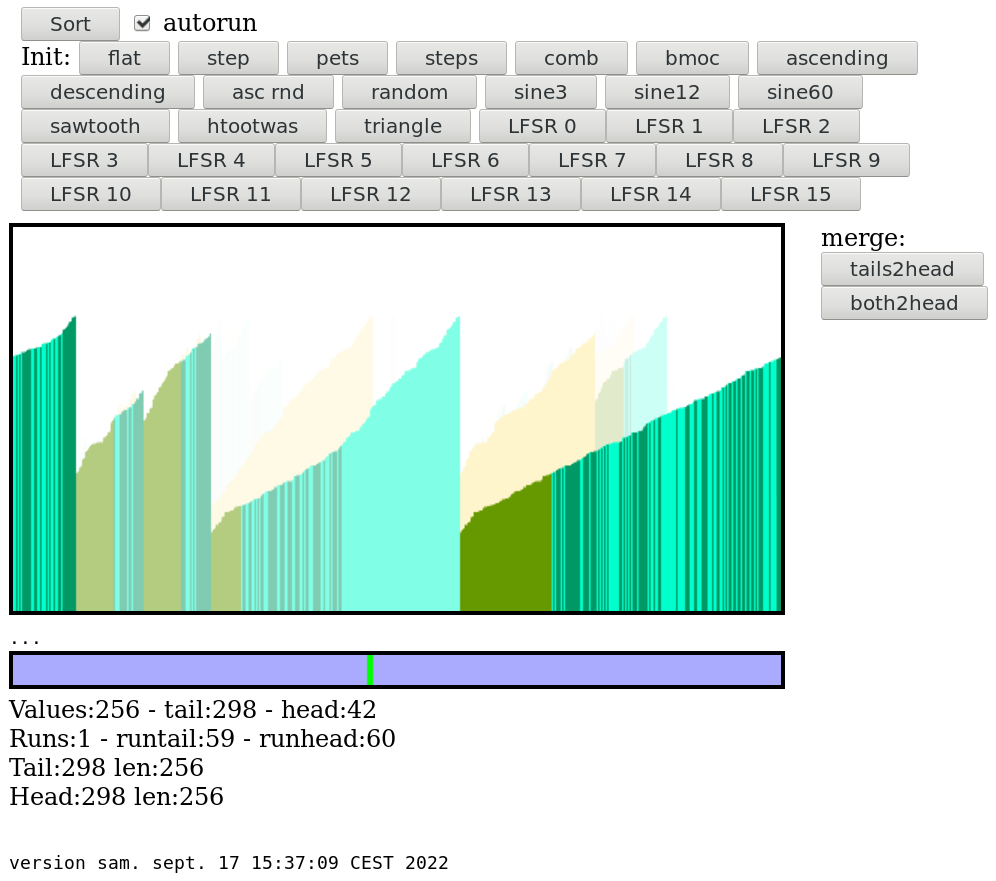
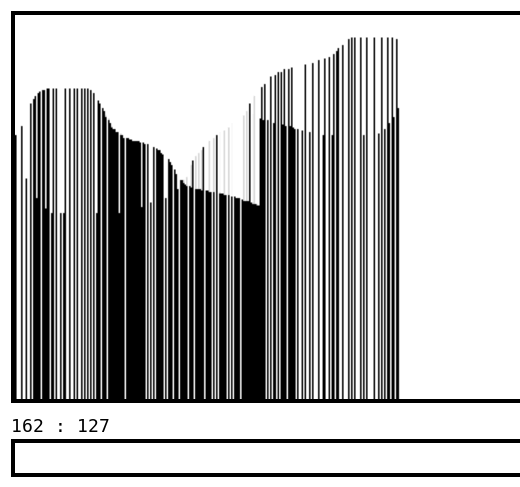




 Zack Freedman
Zack Freedman
 [skaarj]
[skaarj]
 Joe Perri
Joe Perri
 Rowanon
Rowanon
https://www.youtube.com/watch?v=FJJTYQYB1JQ