 Eric Hertz
Eric HertzUPDATE: A more in-depth analysis of another sector-transition:

More analysis at the bottom...
--------------------------
Using "the trick" described two logs ago, and the last log's theories of why it's not oft-used, I've been analyzing a track-extraction from the floppy-disk...
(I'll go into the waveforms more, later).
--------------------
Between each data-section there's a bunch of housekeeping-data. But some of that data is (by design) very recognizable.
Immediately after the data-section (and its CRC) appears to be 24 bytes containing the value 0x4e. This allows the disk-controller's clock to resynchronize between/with each sector.
The first two sectors on the track I'm analyzing appear to be synchronized with each other. And, thus, the clock maintained its sync starting with the first sector, and into the second sector. I can view data starting at 0x0000, and if I count 512 bytes (or just search for address 0x1ff), I can see that data end, followed by two (CRC) bytes, then followed by the very-recognizable 24 copies of 0x4e.
If I continue from there, I can determine some low-level details of the format of the floppy. This one's definitely different than an IBM-PC format (as I've read). One example is that the IBM-PC format uses *80* bytes of 0x4e, rather than 24. (This makes sense... this disk appears to have 10 sectors/track whereas IBM uses 9... those extra bytes have to fit somewhere... so reduce some of those redundant-bytes...) Similar elsewhere. After those 0x4e's is 8 bytes containing 0x00. IBM uses 12 bytes, but, these changes in "gap" size are basically the only major difference.
So, it's easy to see where the sector-header starts (immediately after the 0x00's), and so-on. Thus, I've determined there's 595 bytes used for each sector. 512 for data, and the remaining for sector-headers, CRCs, gaps, etc.
So, if I advance through the file to address 595=0x253, or thereabouts, I actually see the end of the first sector, and into the next sector, and see that the data and header-stuff is aligned just as I expect.
From there I advance to address 595*2... but this time it looks different. Instead of 24 bytes containing 0x4e, I get 23 bytes containing 0x21.
As described, in the previous log, that kinda makes sense... Those gaps are there, largely, for the purpose of allowing the disk-controller to resynchronize its clock with each sector. That way slight timing-variations from one drive to the next won't cause issues like we're seeing in the data-stream here... where 0x4e is coming through as 0x21.
The thought, then, is that what's happening is a slight bit-shift... those 0x4e's are probably written properly to the disk, but since I'm not reading each sector *individually*, and instead reading the entirety of the track as though it's one gigantic sector, the error is due to bit-shift likely caused by the sectors' being written at different times on different drives.
But... 0x21 is nowhere near similar to 0x4e shifted-left or shifted-right by a few bits... so what's happening?
-------------------
MFM. was my theory, and I think I've proven it...
Briefly, storing the data on magnetic media requires both data *and* clock-synchronization information to be stored along with that data. (If you're familiar with SPI or other synchronous serial protocols, this is another way of doing that, on "one wire").
So, MFM is a scheme to assure that the clock stays synchronized despite the fact that one might store twenty bytes containing '0' consecutively. In that case, clock-bits are artificially-inserted... Go check out that link, it served me better than the wikipedia article, and more concise than I could be...
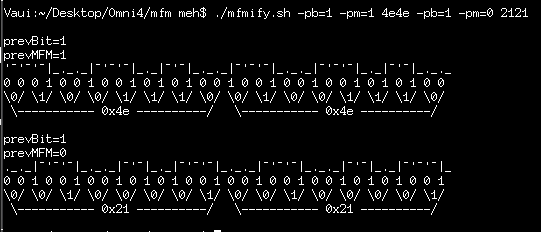
I wrote a shell-script to take in raw byte-data and "draw" the MFM-encoding for comparison-purposes... And, look-here... 0x4e looks darn-near exactly like 0x21, when encoded in MFM, and shifted by *one* MFM-clock.
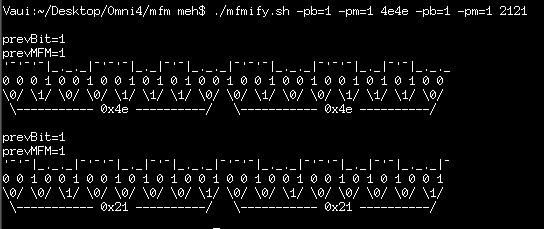
So, probably, what happened is that one sector was written at one time... then the second was written... and it just happened to be that the "gap" was used for exactly what it was designed for... The second sector (well, third, in my case) wasn't aligned with the previous, and overwrote its last "gap" bit (e.g. bit 0 of 0x4e) with the new sector's first gap-bit (e.g. bit 7 of 0x4e), and continued from there. Or something like that...
Interestingly, if the previous bit (before the 0x21's were read) was of the opposite level, the value would've changed dramatically.
----------
So, from here, then... I suppose it's a matter of writing a script which can *determine* the properties of the bit-shift on each sector... First I'll probably extract everything into separate 595-byte files. Then something like... I should see those gaps ~20 bytes long with a specific repeating value... Then... well there's a lot to try from there.
The example shown happens to be shifted by a single MFM-bit. Which is half a data-bit. But, the quote in the last log seemed to make it sound like the gap is *so large* because later-written sectors might be *way* misaligned. Maybe as much as 40+ *bytes*. So there's a bit to ponder...
What was the previous bit-value? That might be extractable from the other data in the file... or it may be easier to just guess-and-test.
What was the previous *level* of the MFM-encoding? That can't really be known from the raw data itself... But, knowing what byte we're *looking for* (0x4e) vs which byte we're *getting* will give us enough info to work with... Probably easiest to just guess-and-test, again.
That gives *four* combinations... But then, it could be off by any number of bits and half-bits... so I guess that's 15 more combinations... So, in all, I think there could be 15*4=60 combinations?!
I guess that's what computers are good for.
Handy, then, that there are *so many* gap-bytes, and the pattern of the gaps so recognizable.
-----------
A vague thought that this might be easier if I just didn't treat them as *bytes* at all, but instead shifted through the bits sequentially until it "locks"... but that's a bit beyond me at the moment. (And, again, slightly different than how a disk-controller would do-so, since the controller has the MFM encoding to look at, two bits for every data-bit, and I have only one bit for every data-bit).
This project's ridiculous! I really went into it thinking all I'd have to do is use the "disk copy" command from the menu that it booted into, and that it'd've been done that first night, weeks ago.
Here's another I'd seen... 0x90's instead of 0x4e's...
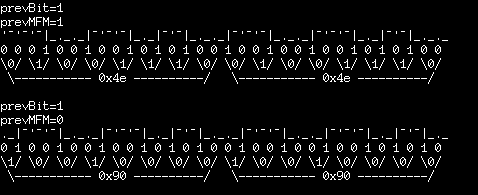
Looks like that, too, is only off by a half-bit. But note it'd've been *entirely* different if prevMFM=1:

(Then again, prevBit would have no effect on the 0x90 waveform, since it starts with a 1-bit... hmmm)
Ah hah... maybe the levels don't matter at all... I'll have to think about that some more... (note that the MFM encoding stores '1' at a *change-of-level*... hmmm) Well, waveforms are sure more fun to look at.
-------------------------------------
UPDATE:
Here's another case...

0x7a is supposedly the last CRC-byte of the previous sector. Then there are two bytes which I think should be 0x4e, but instead are 0xfe and 0x82. From there-on, we get 0x12 where the remaining 0x4e's should be.
So it would seem there may be some overlap from multiple sector-writes...(?)
I dunno. Regardless, I'm pretty sure 0xfe and 0x82 aren't supposed to be valid data.
And... it's easy to see here that the "bit-shift" is *way* larger than just a half-bit.
---------
This "project" was supposed to be a one-nighter... it's been several weeks, now... I suppose I should've put this in a new project-page altogether from the start... But I keep thinking it's going to end soon.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.