 Eric Hertz
Eric HertzFLOPPY DISK IMAGE HAS BEEN SUCCESSFULLY EXTRACTED.
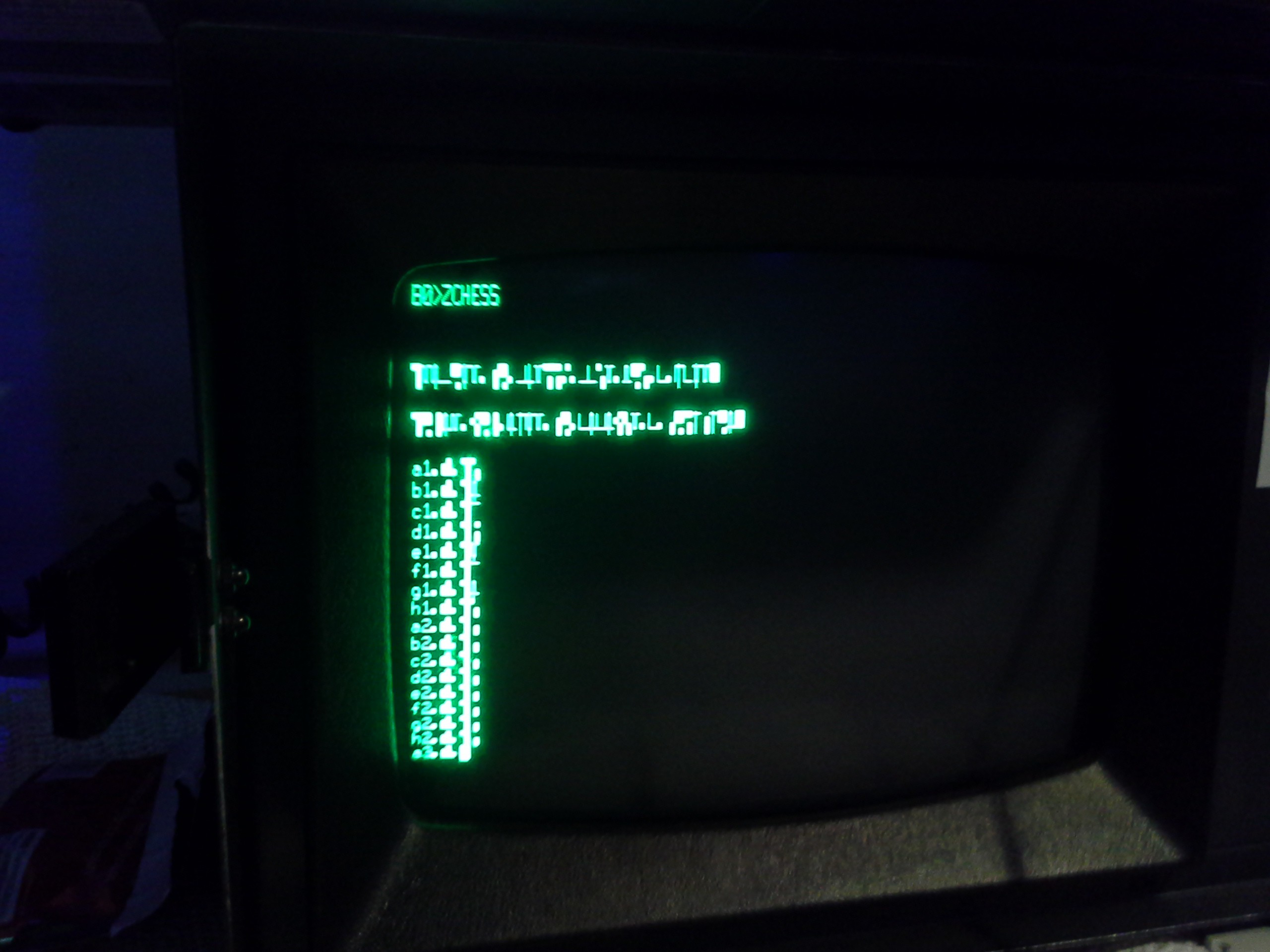
and this project-page has since become about many things OMNI 4.
Check out the old logs for floppy-disk extraction endeavors.
Newer logs are mostly @ziggurat29's amazing work looking into the boot and character ROMs, and even some explanation of the initial/low-level boot process/hardware!
---------
Based on the limited info I can find on the web...
(see a great article, here).
It would seem I've come across a system which may be one of only a few remaining in existence... or at least one of only a few that anyone's bothered to mention on the ol' interwebs.
And I've only got the one floppy disk containing the software for its unique hardware...
And thus beginneth my endeavor into learning a bunch about floppy-disks, drives, and more.
What I thought was going to be a one-night project with a floppy-disk imaging-utility like ImageDisk turned into several months of work, extracting as many sectors as possible via many different methods, including several scripts and a pretty large program I've written myself. Has turned into my learning about MFM-encoding, CRC-checking, Gap-lengths, and countless other factors of floppy-disks, some eccentricities and limitations of various floppy-disk-controller-chips, and more.
----------
So, what's the world-changing-ness of this project...? Well, as it stands, this little piece of history isn't too-well-documented... and if its lone floppy-disk fails before I can make a copy, the entire system could be lost to "bit-rot," plausibly leading its kind to extinction!
Don't want to see that happen!
And, otherwise, even if it's not so unique, at least it'll still be functional, keeping a chunk of metal from the e-waste bin and, with the right owner, giving this system a few more years of usefulness. 20MS/s is still plenty for many needs!
(Heck, most of it is based on well-documented and easily-sourced chips... it could very-well outlast the majority of systems in use today, 30 years after its birth).













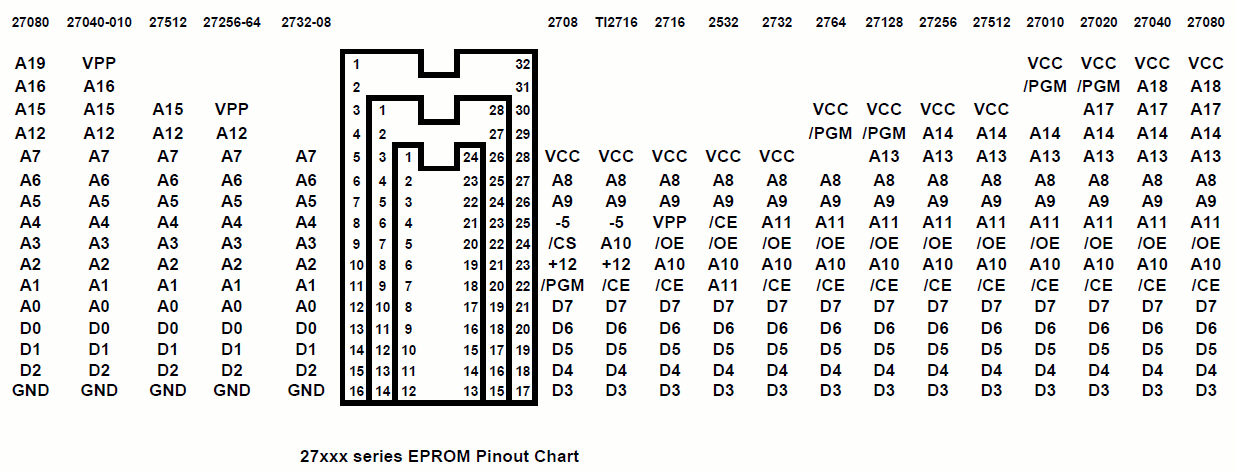










I used to have a DOS program that could read many flavours of CP/M diskettes including the Kaypro luggable by programming the 965 appropriately. That was almost 30 years ago I think. Might still be in some DOS shareware archive. Edit: I think it's 22disk.
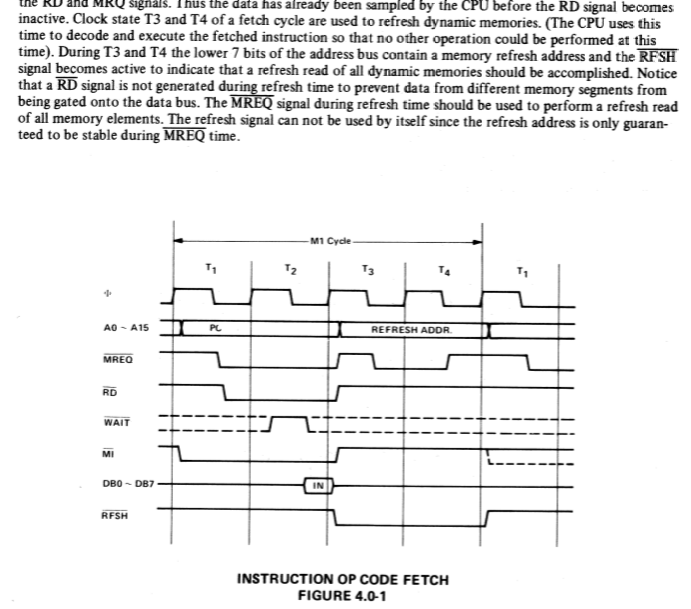
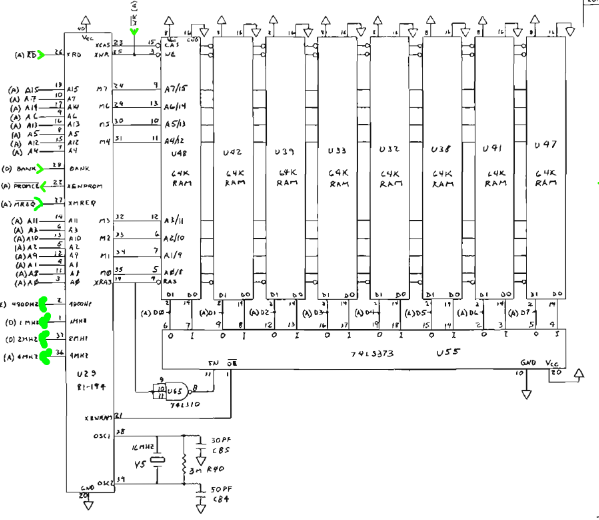
As for the refresh, does this machine use a Z80? You know that it implements hidden refresh right?