 Yann Guidon / YGDES
Yann Guidon / YGDESHTTaP was first published in the french GNU/Linux Magazine n°173 (july 2014) "HTTaP : Un protocole de contrôle basé sur HTTP" as a simpler alternative to WebSockets.
The project #micro HTTP server in C is designed to implement this protocol. This is where you'll find the low-level details discussions.
This project documents the protocol itself, its definitions and evolutions, to help other clients and servers interoperate.
HTTaP could be described as an attempt to formalise requests and replies between a HTTP-capable client and a HTTaP server, as well as all the surrounding parameters.
Think of HTTaP as a WebAPI for hardware and logic circuits.
For example it can embed/encapsulate SCPI commands over Ethernet or Wifi instead of RS232 or USB. No need to install stupid Windows drivers or lousy (binary, non-free and obfuscated) applications !
The client is usually a web browser running JavaScript code to perform high-level work. The code can come from the HTTaP server or any other source such as the local filesystem, Internet... One client can talk simultaneously to different servers but one server (at a given pair of TCP/IP address and port) can serve only one client at a time, to prevent race conditions.
HTTaP messages are very simple : just GET or PUT values to certain places, using JSON notation. This is intentionally simple but limited so actual work is achieved through convoluted sequences of small atomic messages.
Standard addresses provide well-known points that provide enough informations to discover/explore the system, its hierarchy and capabilities, through individual client requests.
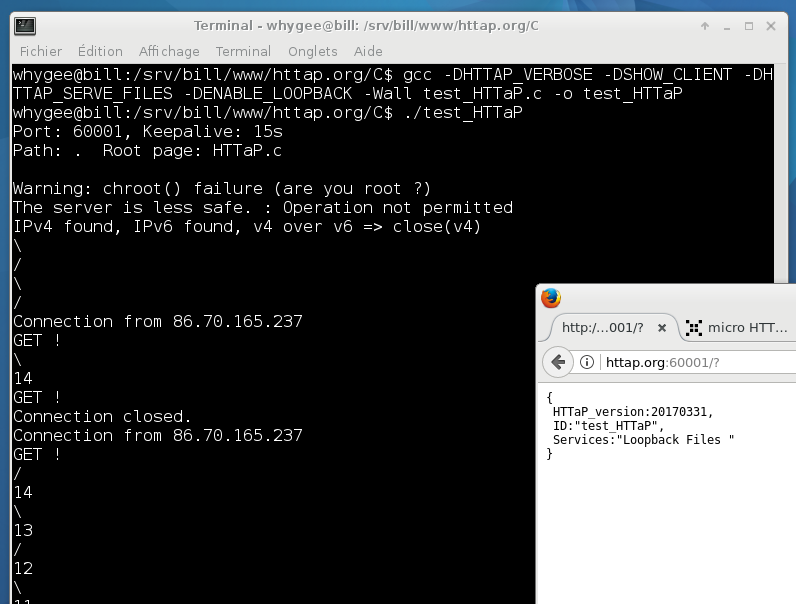
This is why the server needs to exchange many small packets "in order", in lock-step sequences, and fast, so the HTTaP server disables TCP's Nagle congestion-avoidance algorithm (this saves about 400ms second per round-trip).
The user is normally directly connected to the server so the latency is usually low and HTTaP doesn't implement elaborate bandwidth-enhancement algorithms. Real-time latency matters more because it is usually connected to a GUI.
Logs:
1. Overview
2. Compression
3. Loopback server
4. Vocabulary
5. HTTaP root object
6. Security and HTTP protocol
7. PING !
8. RFC2324/7168: HTCPCP
9. Keepalive algorithm
10. Session ID
.



 lpauly
lpauly
 W. Taylor
W. Taylor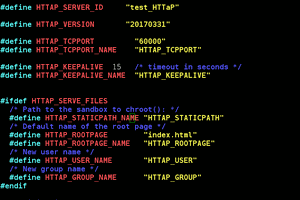
 alusion
alusion
Now found it. Very nice, I might revisit this!