Yann Guidon / YGDES
Yann Guidon / YGDES-
Session ID
05/04/2020 at 23:53 • 0 commentsHow can the client know it lost the connection ? It has no access to the TCP/IP level...
The easy solution is to add a HTTP header to all HTTaP calls, called HTTaP_Session with a unique value. This would not need to appear on plain HTTP requests.
Compared to the minimal C code of the server, modern JavaScript has more freedom and power to analyse the response headers so this is a minimal effort for the server, which only has to come up with a new unique (sequential) value for each socket accept().
The client compares the most recently received session ID with the previous one, and can restart any configuration or initialisation if the communication link was interrupted.
The ID can be set from gettimeofday().tv_sec to prevent reuse.
-
Keepalive algorithm
05/04/2020 at 00:43 • 0 commentsThe latest version of the server implements the new /?ping key that returns the time until connection timeout.
This makes the client's algorithm very simple : send a /?ping, receive the number, subtract 2 or 3 to have some margin, and wait during so many seconds before sending another ping. If the client sends a new request before, cancel the timer then reload it with the last result.
Easy, right ? At least it shouldn't make you sweat a bit in JavaScript.
The granularity of the value is quite coarse due to so many sources of jitter so 2 or 3 seconds of margin should work... Unless the server's workload is more than one second per poll. But in this case, the server will check for a new packet before eventually closing the socket so don't be afraid. The 3 seconds margin would be eaten up in case of severe network degradation... which shouldn't happen in a local network, right ?
-
RFC2324/7168: HTCPCP
04/26/2020 at 22:03 • 0 commentsReplying to Thomas P. :
No, HTTaP is not directly compatible with HTCPCP or its extensions because they work at a lower level. HTTaP works at a higher level, above the server level, using the HTTP protocol to transmit the data as payload instead of in the headers and meta-information.
Thomas is free to implement similar functionalities using the HTTaP features and protocol for the next April, 1st ;-)
-
PING !
04/26/2020 at 21:18 • 0 commentsWith the latest revision of the server, I have added one more word to the baseline vocabulary for explicit keepalive. As you might have guessed, the word is simply ping.
As an exception, ping is explicitly "free form" and can be followed by just about anything, because it helps to keep the browser and all intermediaries from caching the result, in case the headers are misinterpreted. Thus you can request:
?ping ?ping123 ?ping................
The trailing characters are simply discarded.
The root object should also contain the server's keepalive time/value to help the user script manage its time...
Reply
I forgot to specify it in the first draft (that's why this documentation is not definitive).
Early implementations simply reply this:
HTTP/1.1 200 OK Content-Type: text/plain Cache-Control: no-cache Content-Length: 4 PONG
However ?ping is meant to help keep the link alive and the reply has an opportunity to be more useful.
This is possible by sending back the number of seconds before the connection is closed. Thus the client can adjust its ping rate and timers to reduce the processor&network use. This is explained in the log 9. Keepalive algorithm. The new type of packet looks like this :
HTTP/1.1 200 OK Content-Type: text/plain Cache-Control: no-cache Content-Length: 2 12
This signals that the socket will close in about 12 seconds and another valid url should be requested before this time elapses.
20200511 : the new returned packet format is :
HTTP/1.1 200 OK Content-Type: application/json HTTaP-Session: gmahbf10 Cache-Control: no-cache Content-Length: 37 { "Remain": 7 , "Timeout": 10 }Timeout is defined at startup and Remain helps detect jitter, as it should be very close to the "margin" in the JS code.
.
.
-
Security and HTTP protocol
05/08/2017 at 11:29 • 0 commentsI have already addressed security in a different post but on a different, related project: Security and sandboxing
Today I address "antipatterns" as described in https://blog.cloudflare.com/iot-security-anti-patterns/
Let's review the 4 points that are raised :
HTTP Pub/Sub
There is no such thing in the basic HTTaP protocol. There is no redirection or even mention of a third-party URL in the server because the whole thing is meant to be self-contained and autonomous.
DOS is prevented through several passive means:
- Only one client can be connected at a time
- The connection protocol requires exchange of several messages, ensuring that there is no (basic) IP spoofing
- All resources/services that could allow arbitrary "traffic amplification" must be unlocked by a small "are you a fast real-time computer" challenge (to prevent traffic replay)
IoT Device as TLS Server
Encryption is a difficult thing to do, particularly for this class of devices where most corners are cut.
Encryption is not required for now and I don't think I'll use a library, at least for the final version. This is a server-side requirement, since most HTTP clients transparently manage HTTPS.
The suggestion to use a 3rd party server for authentication actually helps a lot, to separate the authentication nightmare from the protocol itself. The HTTaP server can inquire or refresh a key once it starts, which helps a lot when several HTTaP servers are running in parallel (easier and dynamic key management, no more one-configuration-file-per-server nightmare).
But that's for a v2 of the protocol.
Unencrypted Bootloader
This is out of the scope of the protocol.
Database-as-IPC
The HTTaP server can be seen as a sort of database, in a way... but the protocol itself shields against backend implementation variations and their effects.
Note : for security over unreliable networks, whitequark suggests using a nginx layer in this minimalist Python server. I'm not fluent with cryptography and security protocols so I can't devise the best approach...
-
HTTaP root object
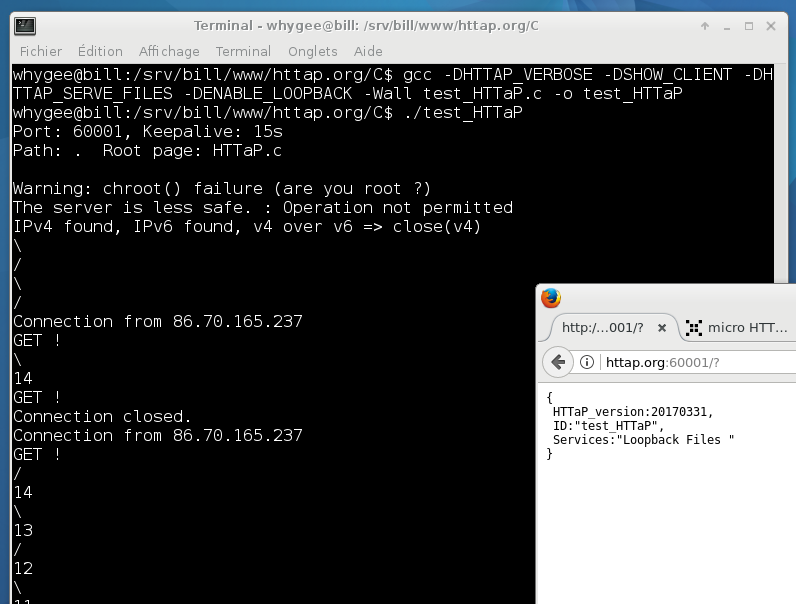
03/31/2017 at 09:29 • 0 commentsThe first thing that a HTTaP client does, upon first connection to a server, is to check its configuration and characteristics. They are provided by a JSON object with these properties:
- HTTaP_version : returns an integer that describes the date in YYYYMMDD format (when displayed in decimal). Reading this property indicates that the server is HTTaP-compatible so this property is required.
- HTTaP_open : this flag is cleared (0) during the first access, and set (1) for the next accesses. This is used to determine if another connection is established with another page on another tab in the same browser.
- Type : returns a string that describes the server (optional).
- Keepalive : how many second a connexion stays open. This way you can compute your own timing before you send a ping request. => this is moved to the ping packet.
- ID : return a string that descibes the name or serial number of the server. Put your name here ;-)
- Services : lists the available features that the server implements. For now it's a string but will become an object for a better (and hierarchical) description. Possible services : Loopback, Files, ...
- Signals : lists the available signals that can be queried. Each can be a complex object.
- SessionID : integer number, generated randomly at each new connection. Used as a token for the persistent connection. For example, helps the client detect that the connection was interrupted. => This is moved to the HTTP header
More will appear as the protocol grows...
![]()
As of 20200511 the current implementation returns this root object :{ "HTTaP_open": 1, "HTTaP_version":"20200511", "ID":"blocking server with HTTaP", "Services":"Files " }More will probably follow.
-
Vocabulary
03/28/2017 at 00:57 • 0 commentsThis page contains a draft for a uniform/universal URI layout and "vocabulary" that all applications/clients can use. As usual, only stable code will serve as a reference, this page is more of a reminder and declaration of intention.
HTTaP defines two "domains" :
- The static domain contains files that do not change. They usually contain all the HTML/CSS/JS interface and all the support files. They are usually cacheable.
- The dynamic domain is introduced with a « URI with query component(s) », starting with "/?", to prevent them from being stored in cache (in addition to having appropriate headers).
The dynamic domain is split further:
- lowercase names are usually reserved for standard HTTaP features (such as ping or loopback)
- UPPERCASE names describe application-specific resources, signals, like memory, registers, sensors...
I'm not sure about the following paragraph:
Signals use the object notation (with a dot) to represent hierarchy. As a rule of thumb, if it uses a copy of the circuit or an instance of the code, it will be dot-represented. They will be treated similarly by the handler of the server, for example memory spaces...URI comments GET POST /path/filename Static file to serve. * /? Root of HTTaP, serve a JSON-formatted list of available of valid dynamic resources names * /?ping A simple key used to keep the connection alive.
Returns the number of seconds before the link is closed.
Note: the ping keyword can be followed by any character, to help with caching servers.* /?invalid Never decoded, always returns an error (if you want to close the session for example) /?loopback Loopback for JS save/restore (optional) * /?list (for signals)
Return the list of the signals and their hierarchy* /?changes (for signals)
same as /?list but only include signals that have changed* /?REG read the value of all the registers * /?REG/R1 read the value of register R1 * /?REG/R1,R2 read the values of registers R1 and R2 (optional?) * /?MEM Dump the contents of the memory * /?MEM/123-456 Dump the contents of the memory from locations 123 to 456 * /?IO.SPI.1/ Read the full status of the first SPI port * The uppercase names are just examples and are only suggestions.
I'm not sure about the representation/formatting of ranges but they are useful to reduce the bandwidth and CPU load.
Memory ranges should use the #HYX file format to save bandwidth, compared to plain JSON syntax.
-
Loopback server
03/28/2017 at 00:18 • 0 commentsHTTaP is meant to help integrate #YGWM with a web-based system, and there is more to it than serving files or sending commands to TCP widgets.
Any editor needs to read and write files from the local disk/storage and the chosen language/framework (HTML/JS) does not allow that. The web browser prevents scripts from doing it, for obvious security reasons !
Yet there is a solution. Or more precisely, it's a hack ! I have described it in an article in French:
"Accéder aux fichiers en JavaScript (ou le Cross-Site Scripting utile)" in GLMF#105 pp.42-54
This describes a dirty trick, using a PHP script along with a specially crafted HTML/JS page :
- To read a local file into the JS framework, tell the browser that you want to upload said file to the server. The JS part can't access at all the file contents but the server will reply with a JS-formatted string that is the exact copy of the file. Bazinga !
- To write a file to the local file system, the JS script will send the properly formatted data as a POST form. The server then transcode and reply with these data advertised as a binary blob of unknown type, which the server will understand as a file to save. Bingo !
Note : these manipulations usually require user interaction and are not inherently more unsafe than usual methods.
The PHP script was a pain to write and I'm glad to have a totally controlled environment (the HTTaP server) where I can process the data without layers of gotchas and poisonous sugaring...
The JS framework has evolved too and "binary blobs" now solve many of the encoding problems I have !
The "Loopback" feature should be a standard, user-configurable, option in the HTTaP protocol, with its own access key.
20170429:
Now, it seems that interactive websites use a technique similar to the loopback server. An example is the circuit simulator at http://www.falstad.com/circuit/circuitjs.html
I recently spotted an addition to the HTML5 standard at https://developer.mozilla.org/en-US/docs/Using_files_from_web_applications which looks promising but it doesn't seem to writte files, and support is yet untested and unknown. I hope that my system works with HTML4 clients.
-
Compression
03/27/2017 at 23:50 • 0 commentsHTTaP should not be used in public-facing networks, where bandwidth is a concern (latency often is more important). Compression is not a priority but it IS possible to implement it.
The inherent cost is that the server needs to parse the request headers and find the line that declares that compressed files are allowed. It's possible but this uselessly increases the coding effort...
20170429:
A couple of interesting things to notice.
First, compression is interesting for large files, not the small requests and answers. This happens in two cases:
- For large HTML or JS files that are served to the browser. Images are typically already compressed. Selected files can be pre-compressed and served if the client supports the chosen algorithm (usually gzip/deflate). But don't forget that proper minification and cleanup already contribute to smaller files and shorter downloads. Removing the tabs, whitespaces and comments shrinks data from 20 to 60% (depending on the source code's style)
- Large data chunks, such as memory dumps, are expected to be exchanged in both directions and can't be pre-compressed. One easy way to reduce the chunk sizes is to use raw binary encoding instead of ASCII-encoded strings. Another is to use the #HYX file format that supports repetitions of the last character, as well as address ranges. It's not as good as proper compression but is easily supported in C, JavaScript, bash...
Second, the client is not expected to change its capabilities during a TCP session. This means that the headers can be parsed just once, when the server receives the first request. The next requests can just skip the headers.
20200505:If needed, the #micro HTTP server in C could serve pre-compressed files thanks to the "shadow" system that adds headers.
-
Overview
03/21/2017 at 21:42 • 0 commentsHTTaP uses a reduced subset of HTTP, keeping only a few essential features.
- Any HTTP compliant server must be able to understand HTTaP requests even though it can't fulfill all the requests (at worst, it replies with a 404 status)
- Any HTTP client can send a HTTaP compliant request with minimal effort. Normally, the HTTaP client is a classic web browser but wget or curl must work too.
HTTaP servers work mostly like classic HTTP servers but differ in a few ways, such as
- resource reference (naming conventions)
- caching
- no cookies
- timeout
- persistent connections
- serialisation (no simultaneous/multiple accesses)
- headers
These implementation choices come from constrains in size, speed, complexity : HTTaP must run in "barebone systems" with limited code and data memory, reduced CPU resources and lax security.
Development and support of HTTaP at the lowest level is on the server side because all the clients are meant to be HTTP compliant already. High-level development (the application's intelligence) focuses on the client side, which uses JavaScript (or any other powerful dynamic language, since Python is quite popular for example and a browser is not required) to assemble the requests and interpret the responses.
The HTTaP server must be as lean and simple as possible.
- One source of complexity is removed by not interpreting the client's request headers. Actually, none of these headers are pertinent or relevant to most of HTTaP's use cases (except Compression). This cuts a lot of work but also means there is no support for cookies. Standard authentication is impossible so HTTaP is unsecured. Any client can connect and use the resources at will. Use HTTaP only on airgapped networks.
- Another source of complexity comes from the HTTP "vocabulary" : the only supported methods are GET, POST and HEAD.
* GET reads resources (files or dynamic variables) like any usual request.
* POST writes these variables (file upload is only an option)
* HEAD is a requirement of HTTP1.1 and only minimal support is provided (because it is barely used in local links, since there is no proxy). In practice, HEAD is not even used, as the browser now relies on the server to send a 304 Not modified reply. - The server is single-threaded and serves only one client at a time
* This ensures by design that there can be no race condition.
* The server is typically used by only one client at a time anyway.
* This reduces code complexity and timing issues
* Raw performance and throughput are not critical, since the client and server are usually located next to each other and the server is minimalist, reducing processing and transfer overhead.
The single-socket approach seems to create its own set of troubles with browsers that insist on sending an avalanche of requests no matter what.
A HTTaP server typically provides two separate domains:
- a static files server (a very basic HTTP server)
- a dynamic sever, like an embedded CGI inside the server program.
The URL defines which domain is accessed with a very simple method : static files use standard URLs while dynamic ones start with the "?" character.
The question mark is a common indicator and good heuristic for dynamic contents and would not be messed with by eventual proxies.
- When the requested URI starts with "/?" then the dynamic mode is selected and an embedded program parses the URI.
- Otherwise, this is a standard file, with a direct mapping to the file system (often a sub-directory). There is no support of automatic index.html generation or "open directories".
No access control is provided for the static files, which usuallly contain the HTML/JS web application and all the required supporting files. Access rights must be correctly set on the filesystem by the developer to prevent 403 errors or unwanted access to unrelated files.
Lately, Facebook has added a nasty "fbclid" suffix to outgoing links and this breaks them when they refer to HTTaP resources. Some mitigations on the HTTaP side are possible but they are not considered critical because who would post a HTTaP link on Facebook ?