 Colin Alston
Colin AlstonIt's about time I actually cluster computed some things. I played around with various HPC things like Slurm and VCL and to be honest I didn't really understand any of it, documentation is either scant or overwhelming to an HPC noob like me.
In the end I decided to battle my way through getting Jupyter notebook running with IPyParallel and mpi4py. This ended with great success! Once I figured out its little dark corners that is.
Given that it became laborious manually synchronising and installing things across 4 nodes I decided to use Ansible from my RaspberryPi management node to do the clusters real system administration. In a larger cluster I'd certainly go with Puppet as my preferred configuration management system because it can actually continuously manage stuff, but my bastion is a Pi B+ and there's no way I'd get a fully fledged Puppet server going on that.
Instead of prattling on about how I got Jupyter and the ipcluster stuff working I stuck the Ansible scripts in the Github repository here https://github.com/calston/tinyjaguar/tree/master/ansible
I decided to use Jupyter Hub which is pretty cool, instead of having to manually spin up a notebook process with my user. One thing that wasn't immediately obvious in the setup documentation is the ipcluster profile has to be started by the user of the notebook, so I wasted a lot of time building a systemd script for ipcluster which turned out to be useless - you just boot your cluster straight from the Jupyter web interface when you need it, which is actually much better.
A quick test and it all seems to work great, hooray!
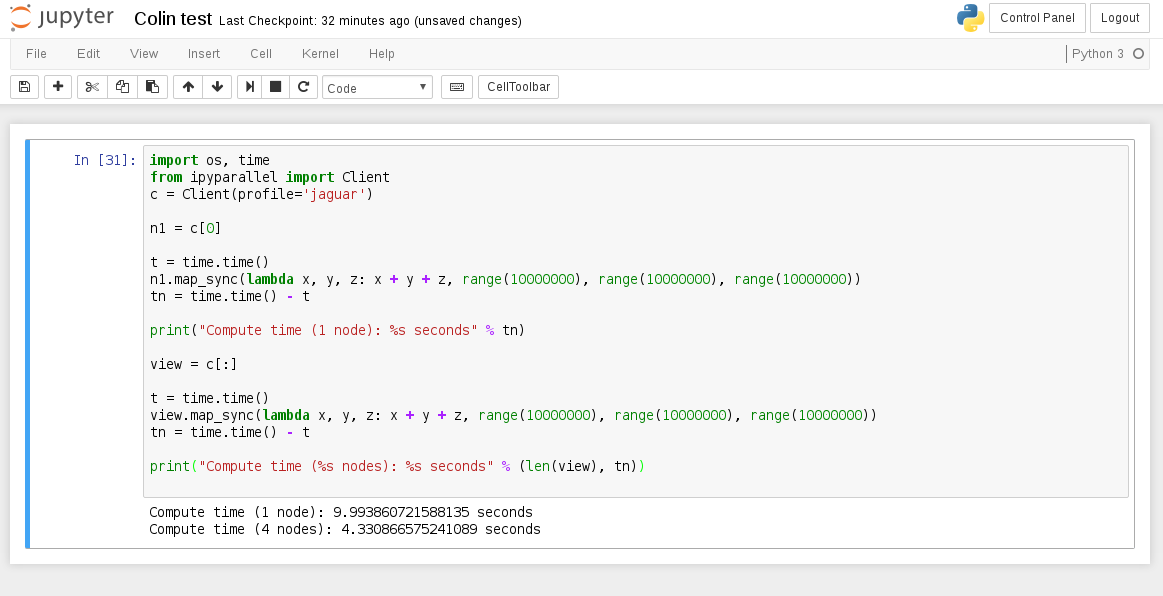 This is one of the basic examples from ipyparallel docs that I just knocked up a notch in iterations because obviously at small iterations the performance hit from reducing the computation results from the nodes over GigE stuff is actually slower over multiple nodes. This is quite a good reflection of Amdahl's Law in the perils of parallel workloads, you don't always get a performance increase over multiple compute nodes, and you almost never get a linear performance increase by adding more nodes. This is why Cray's and what-not have ridiculously expensive high bandwidth connections between computing cores to overcome the latency bottleneck, and also why wiring code for an HPC is not so easy as for a single system.
This is one of the basic examples from ipyparallel docs that I just knocked up a notch in iterations because obviously at small iterations the performance hit from reducing the computation results from the nodes over GigE stuff is actually slower over multiple nodes. This is quite a good reflection of Amdahl's Law in the perils of parallel workloads, you don't always get a performance increase over multiple compute nodes, and you almost never get a linear performance increase by adding more nodes. This is why Cray's and what-not have ridiculously expensive high bandwidth connections between computing cores to overcome the latency bottleneck, and also why wiring code for an HPC is not so easy as for a single system.
Now I want to try do some neat visualisations, and I'll keep putting stuff into my ansible repo moving all the manual cluster bootstrapping I did (like debootstrap, NFS, NTP and DHCP) to playbooks in-case I need to rebuild the system from scratch
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.