 Neil K. Sheridan
Neil K. SheridanELEPHANT AI SYSTEM
Here's a talk I did about the project
INTRODUCTION AND GOALS
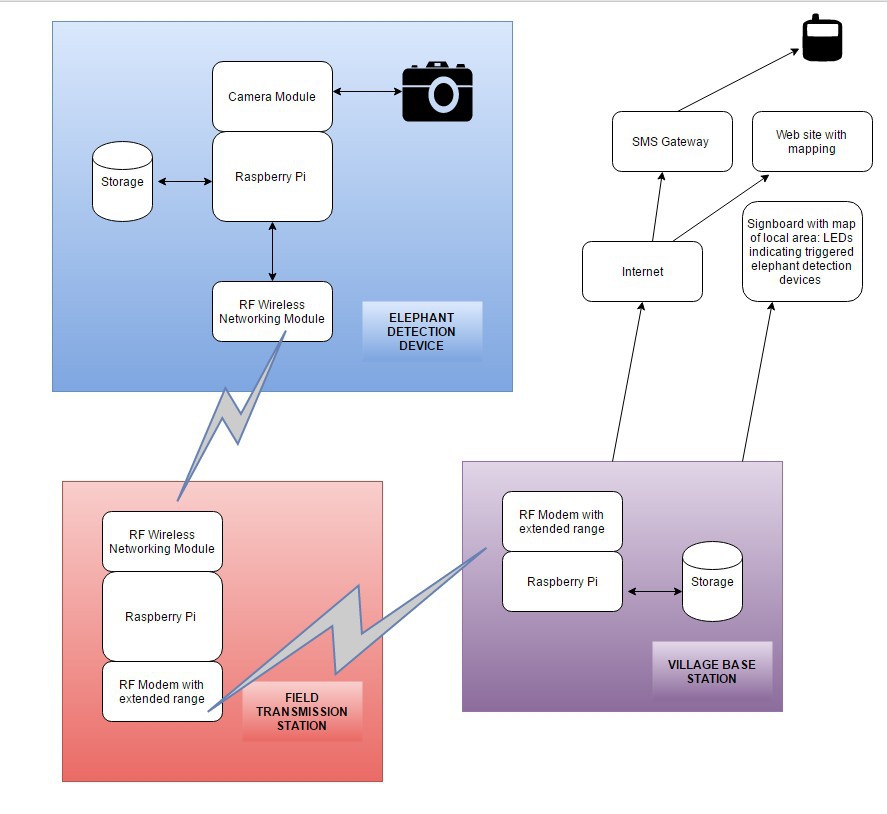
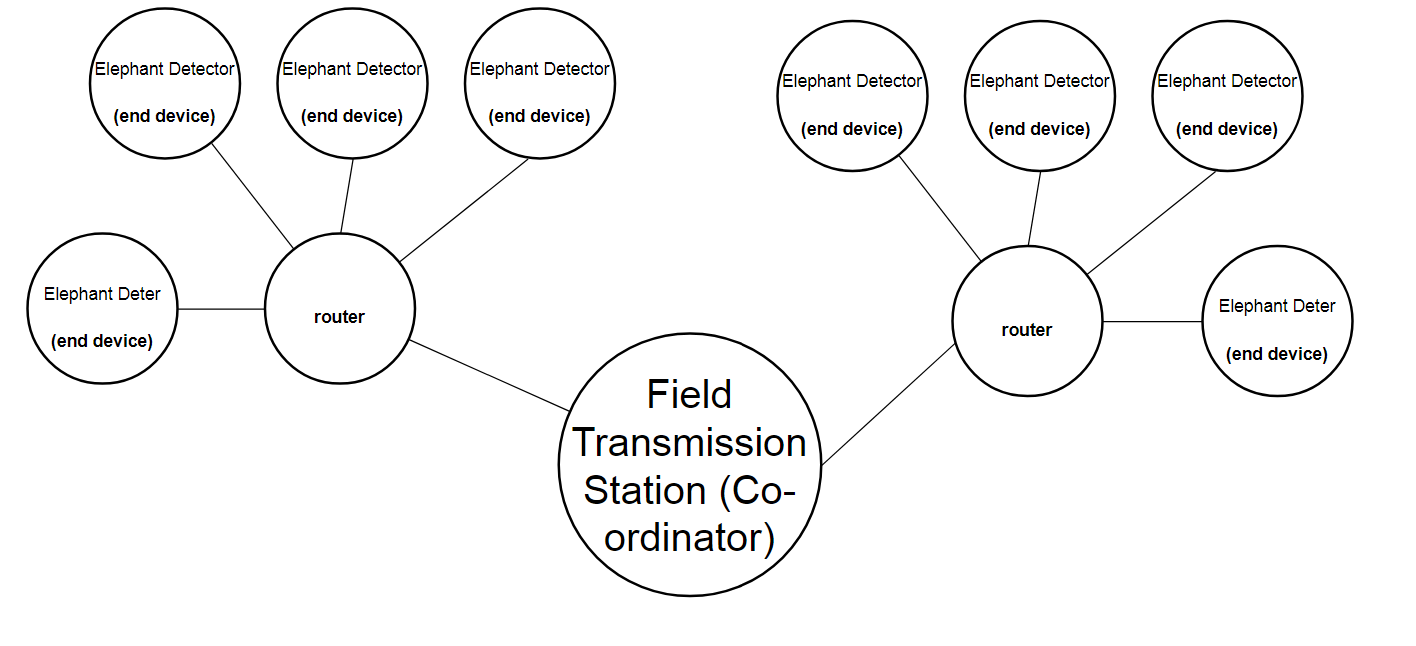
This is an evolution of my 'Automated Elephant-detection system' that was a semi-finalist in the Hackaday Prize 2016. The current project differs substantially in that it makes use of more advanced machine vision techniques, and eliminates the usage of RF communication and village base stations. Alternatively using 4G/3G/EDGE/GPRS on each elephant-detection device, and includes elephant-deterrence devices to completely eliminate interaction between humans and elephants whenever possible.

* Thanks to www.nerdycute.com for drawing our logo!
So, let's get to the primary goals of Elephant AI:
- Eliminate contact between humans and elephants
- Protect elephants from injury and death
- Protect humans from injury and death
How will the Elephant AI accomplish these goals?
- Detect elephants as they move along their regular paths. These paths have been used by elephants for many years (perhaps centuries) and often cut through areas now used by humans. Humans will be warned that elephants are moving on the paths so they can stay away or move with caution.
- Detect elephants as they leave forested areas to raid human crop fields. At this point, elephant deterrence devices will attempt to automatically scare elephants. This will be using sounds of animals they dislike (e.g. bees and tigers, and human voices in the case of Maasai people in Kenya/Tanzania), and perhaps by firing chili balls into the paths of the elephants from compressed air guns.
- Detect elephants before they stray onto railway lines. This can be done via a combination of machine vision techniques and more low-tech IR (or laser) break-beam sensors. Train drivers can be alerted to slow-down and stop before hitting the elephants who are crossing.
Just how bad is it for humans and elephants to interact? This video, shot several months ago, in India, gives some idea. It is really bad indeed. It causes great stress to elephants, and puts both the elephants and humans at risk of injury or death.
That's why Elephant AI wants to take human-elephant interaction out of the equation entirely!
HARDWARE SETUP
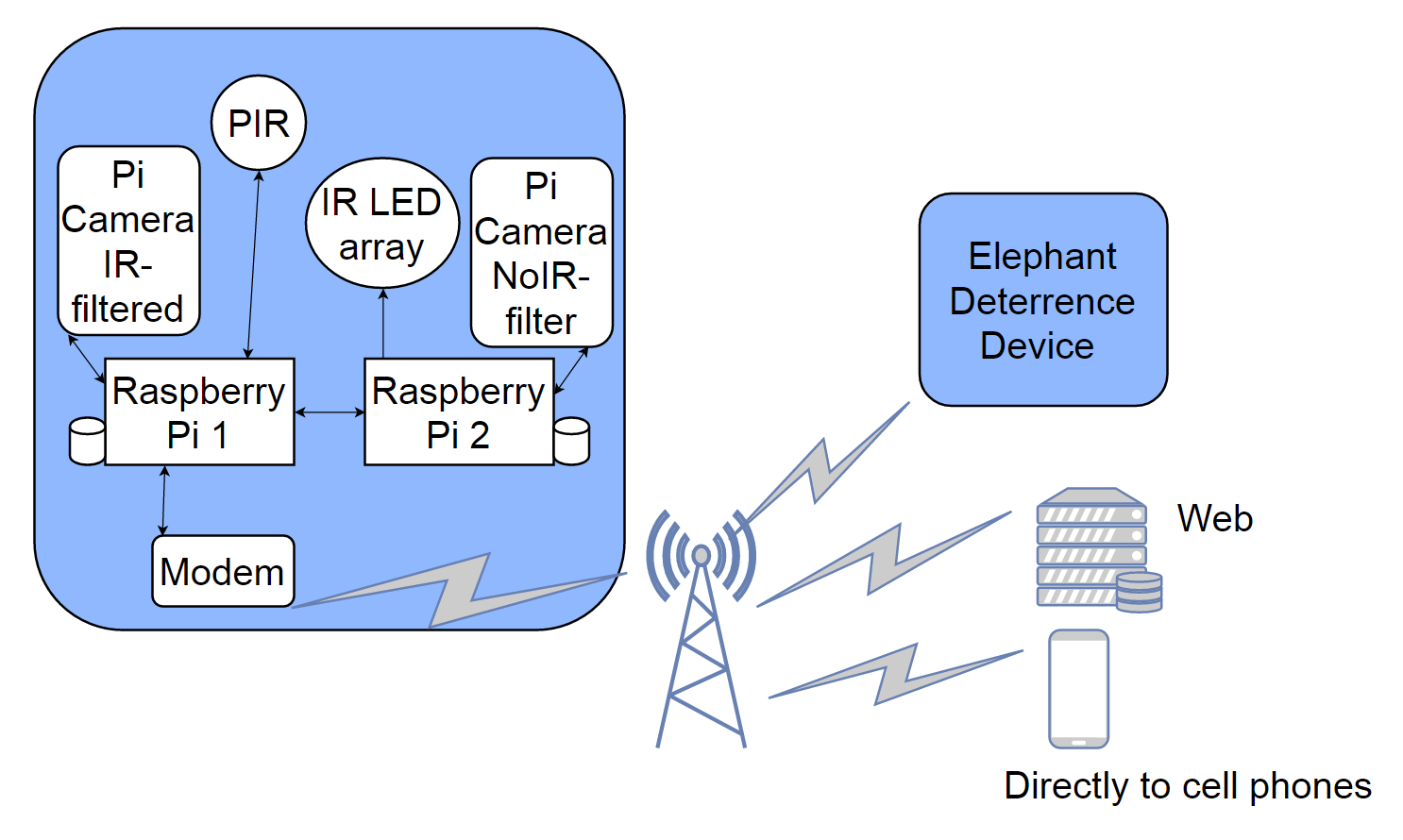
We need a daylight camera (IR-filtered) and a night camera (NoIR filtered + IR illumination array) since elephants need to be detected 24hrs per day! In my original project I completely forgot about this, then decided to multiplex cameras to one Raspberry Pi. It was actually cheaper and easier to use two raspberry pi's; each with its own camera. Night-time and daytime classification of elephant images both need their own trained object detector anyway, so I don't think it's such a bad solution (for now).
METHODS FOR IMAGE CLASSIFICATION (older approaches)
This is the main part of the project. In my original automated elephant detection project I'd envisaged just comparing histograms!! Or failing that I'd try feature-matching with FLANN. Both of these proved to be completely rubbish in regard of detecting elephants! I tried Haar cascades too, but these had lots of false positives and literally took several weeks to train!
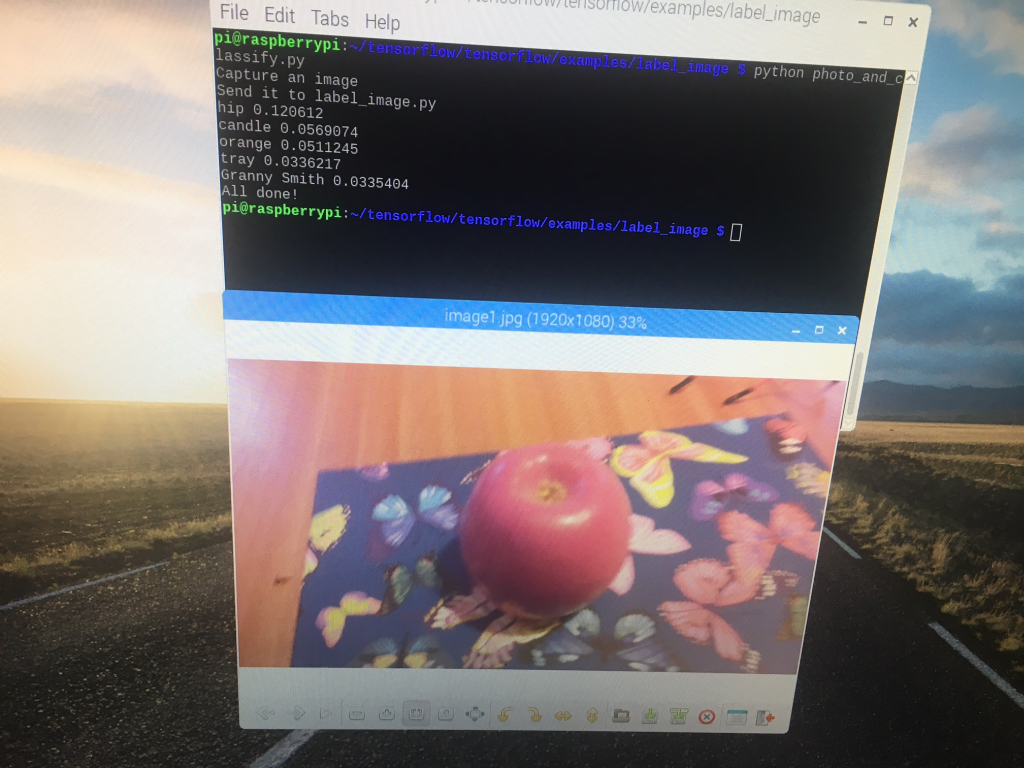
Initially with ElephantAI I worked with an object detector using Histogram of Oriented Gradients (HOG) and Linear Support Vector Machines (SVM). That had promising results; giving only 26% false-positives with a dataset consisting of 350 positive elephant images and 2000 negative non-elephant images (see https://hackaday.io/project/20448-elephant-ai/log/57399-4-result-for-object-detector-using-histogram-of-oriented-gradients-hog-and-linear-support-vector-machines-svm) and I would expect improved results with larger datasets. And it did. I got a result of 16% false-negatives with 330 positive elephant images and 3500 negative non-elephant images (see result #5)
At present, I am working on differentiating between types of elephants using deep convolutional neural networks for image classification vs. classical machine-vision techniques I had...
Read more »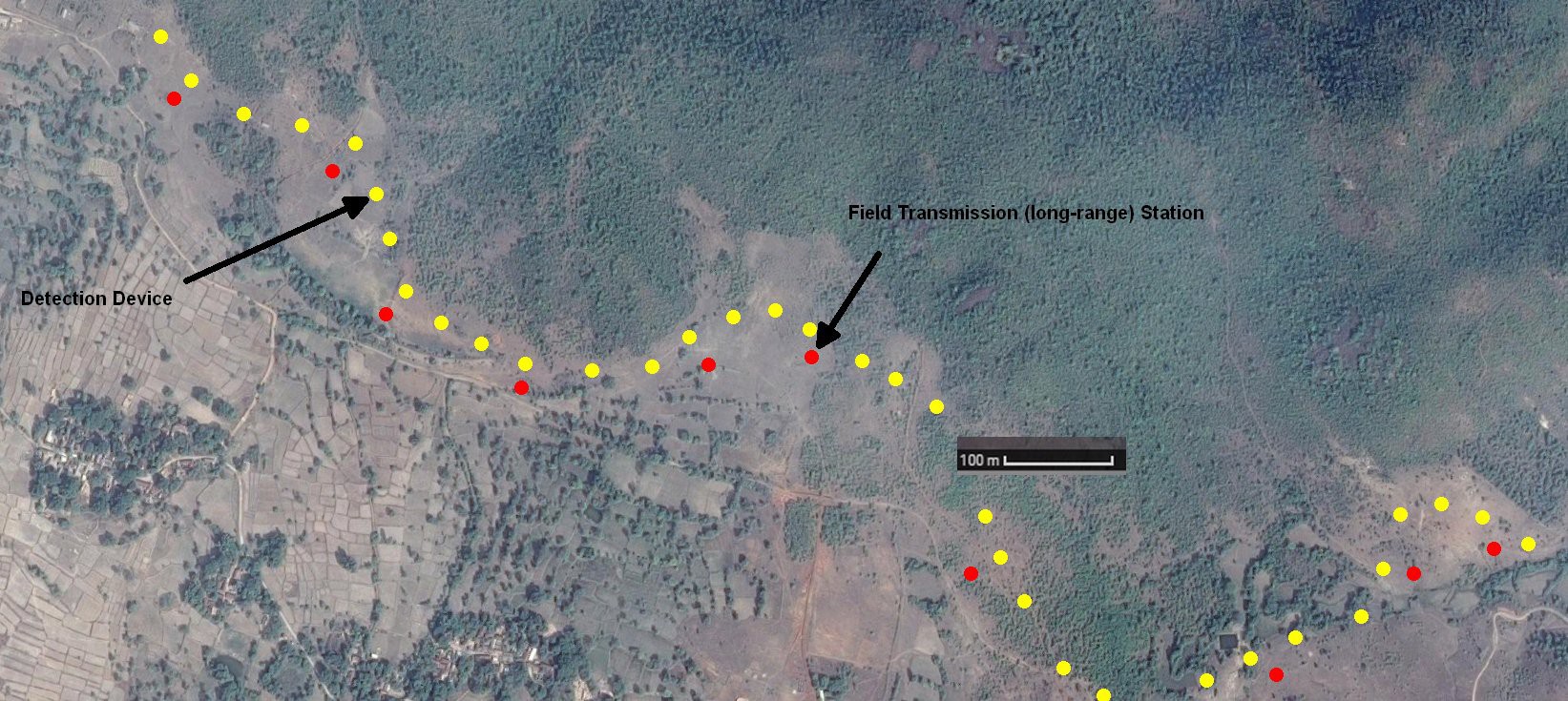












 Rob Lauer
Rob Lauer
hello Neil,
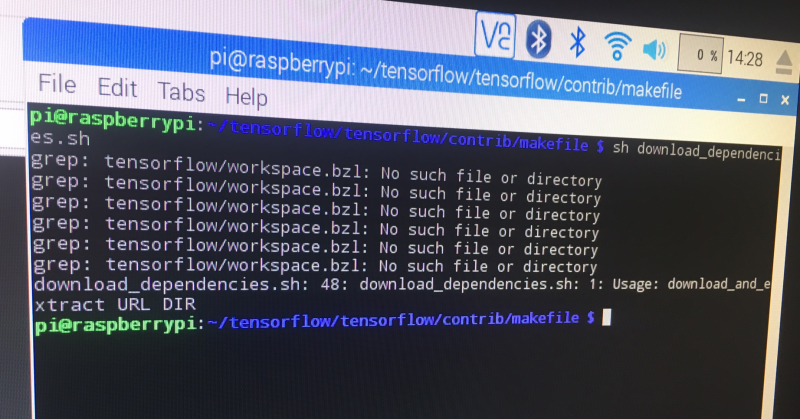
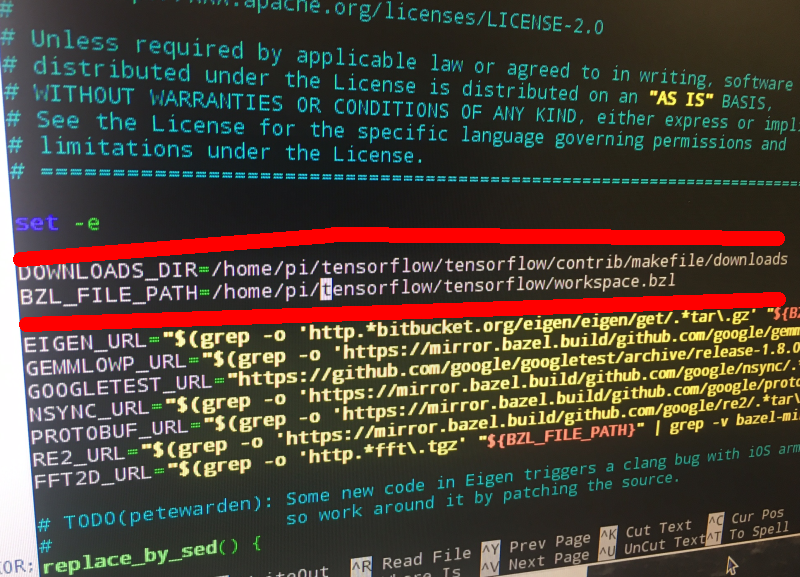
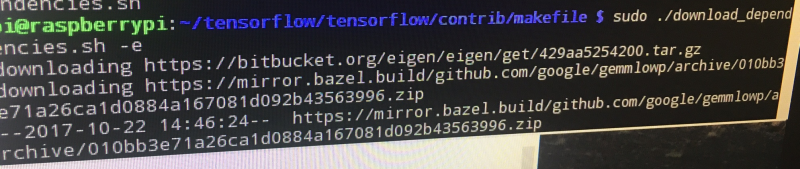
I am currently working on this project using a raspberry pi 3. I was able to successfully download tensorflow version 1.1.0 and also keras version 2.5.1. but when i run the following command
model = InceptionV3(weights='imagenet')
I get an error saying
TypeError: softmax() got an unexpected keyword argument 'axis'
How do i proceed from this. I'd appreciate it if you help me out here.