0%
0%
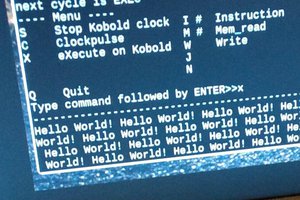
OPC-1 CPU for CPLD
A one-page CPU: spec, HDL, emulator and macro assembler each in one page. Fits in XC9572 CPLD.
 Ed S
Ed SBecome a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests





 kaimac
kaimac

 Pavel
Pavel
I think OPC soft-cores could be perfect lab rats for my C++HDL project https://hackaday.io/project/160393-trcm :)