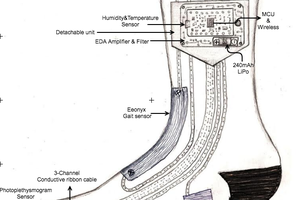
 Michael
MichaelThe idea to improve the electronic larynx is not really new, so here some things that already exist, but anyway might have some room for improvement, or at least room to get the relative high prices for these devices down:
This company here (I have nothing to do with them!) has already a commercial product that allowes to alternate the pitch using an inbuilt force sensor, and in this video they show the difference it makes:
Here is an academic project that has developed a hands-free concept: https://www.behance.net/gallery/11197981/Hands-free-Electrolarynx_Academic-Project-2011 (I also have nothing to do with that!)
My idea is to use a sampler for the sound creation, that will allow to test different waveforms with ease and can be easily tuned over the entire frequency range of human voice, male as female.
Based on a firmware that I already have, I will use a low-cost MCU, an amplifier, an exciter and good quality conductive rubber to build a logarithmic force sensor.
The force sensor is simply a piece of conductive rubber fixed on a PCB grid - the more you press the rubber to the pcb, the lower the electrical resistance of the rubber will be. This is a highly logarithmic force sensor, exactly what you want to transform finger pressure into expression. Linear force sensors are not the right choice for this since they react too strong on low forces and are also far more expensive.
In regard of the amplifier, I have not yet made a decision and so I just use a ready made D-type amp for the moment.
For the vibration I use an exciter, basically a loudspeaker that moves instead of a membrane a small weight. These exciters are used to transform any surface (e.g. a table or a window) into a loudspeaker.
For the MCU I will use a STMF32F4xx, an ARM Cortex M4. There might be also some cheaper choice, but sometime ago I build a monophonic synthesizer for that chip, so I will canibalize that firmware to create the sampler, which makes it a pretty straight forward task. I will publish at least part of the firmware - the very heart is the resampling algorithm.
With a sampler there are virtually unlimited possibilities to try different waveforms. Eventually it might even be possible to use audio samples from a persons (former) voice as base material to reconstruct that specific sound of voice. If this is possible, it would be quite an advance in respect to the devices that already exist.
The ADC of the chip will be used to get the data from the force-sensor (rubber pad) which will be used to modulate the pitch. The trick is to transform a harder grip into a higher pitch in a way that allowes the user to express emotions and excitement in a possibly natural way.
Since the audio does not need much dynamics, I will use the DAC of the MCU to output the audio frequency. Else a regular audio codec could be used over the I2S port. But I think this is a complication that won't pay in the end. With the DAC the frequency range will be a bit limited, but I see no point anyway in frequencies above 5 kHz.
So far the theory. As the next thing, I will setup a test with a laptop as sampler, the amplifier and the exciter to see how much power is really needed and where might be the problems that one never knows of, before trying. As soon as I can do that, I will post a little video here. I hope this will be soon, but I also have a challenging day job, so please be patient. Anyhow, if interested, please leave a comment or get in contact.

 Naveen Sridharan
Naveen Sridharan
 Gabriel D'Espindula
Gabriel D'Espindula
 Vignesh Ravichandran
Vignesh Ravichandran
 Debargha Ganguly
Debargha Ganguly
Hi greenaum, unfortunately I do not have much time to work on this project. My first results showed that the transducer and amp I used were not able to create enough loudness. Mainly the normal commercial transducers are not the right way, since they do not produce enough amplitude. Another type of transducer would be needed, but I fear that would have to be developed from scratch. The commonly used devices are basically not much more than a relay that excites itself - thats where the "cancer kazoo" sound comes from. The trick lies in finding a new way to make a transducer that can make the larynx vibrate with more complex waveforms. As always, please post any ideas - who knows, maybe someone has stroke of genius!? :-)