 Stephanie Stoll
Stephanie StollA bit on Neural Networks in General
There has been an increasing trend to use Artificial Neural Networks (ANNs) for solving problems in a variety of fields, such as classification, compression and other data processing, control, and robotics. They are loosely based on the human nervous system, in the way it consists of a high number of simple, yet highly interconnected units (neurons) working together to solve problems. ANNs first gained popularity in the late 1980s/ early 1990s, however, their use cases were limited due to the relatively small computational resources at the time. In the last few years ANNs have experienced a renaissance as computational power has increased dramatically. Today they are an integral part in solving many data based problems.
Convolutional Neural Networks
CNNs are the type of neural network most commonly used for computer vision problems. Let's look at a simplified representation of a CNN architecture called LeNet:
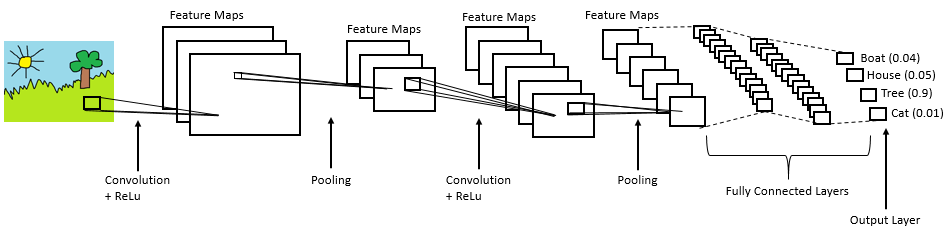
A CNN can have different architectures but always includes the following steps:
1. Convolution
2. Non-Linearity (Rectified Linear Unit)
3. Pooling (Sub Sampling)
4. Classification (Fully Connected Layer)
In the convolution stage the input image is convolved with a range of filters. The filters are the weights adjusted in training. The resulting feature maps are rectified by setting all negative pixel values to zero using the Rectified Linear Unit (ReLu) operation. In the pooling or sub-sampling step the dimensionality of the rectified feature maps is reduced whilst retaining important information. This makes the feature maps less computationally expensive and less susceptible to scale and translation. Convolution, rectification, and pooling steps can be repeated multiple times, extracting features from an input image. In the fully connected layer the extracted features are used for classification.
After looking at the structural elements of a CNN, it is necessary to define what is meant by ‘training a network’. Training takes place in two directions through the network, with feedforward and backpropagation: In training, data is fed through the network in a forward manner, resulting in an output at the output layer. This output is compared against the ground truth (the expected values) and a total error is calculated. The error is then backpropagated through all the layers from the output layer to the input layer, adjusting the weights (filters) depending on how much they account for the total error at the output. The feedforward and backpropagation process is repeated ideally until all weights are stable. In other words, a set of weights needs to be found iteratively that minimises the cost function associated with the total error of the network, causing the network to make better predictions over time.
Tools for using Neural Networks
Due to deep learning’s recent popularity, there are several frameworks and libraries available for building and utilising neural networks. Let's look at some of the most popular.
‘Caffe’ is a deep learning framework developed by Berkeley Artificial Intelligence Research at the University of California, Berkeley. It is written in C++ but has interfaces for Matlab, the command line as well as Python. Data is processed in N-dimensional arrays called Blobs. They are passed between layers, which are responsible for all computations, like convolution, pooling and inner products. A net consists of a connected set of layers. NVidia’s Deep Learning GPU Training System (DIGITS) provides a powerful browser-based interface to Caffe. It has facilities for creating databases, as well as training, designing, and visualising neural networks. There is also a choice of pre-trained models such as AlexNet and GoogleLeNet available for use.
Another deep learning framework is ‘Torch’, developed and maintained by researchers at Facebook AI Research, Twitter, and Google DeepMind. It is based on C/CUDA but has a LuaJIT interface. In 2017, an early-release Beta Python interface called PyTorch was released.
‘Theano’ is a deep learning library written in Python. It has been developed by the Montreal Institute for Learning Algorithms at the University of Montreal. Data is represented in multi-dimensional NumPy arrays. Theano allows relatively low-level access, which makes it versatile, but increases complexity.
‘TensorFlow’ is a library for machine intelligence developed by the Google Brain Team. It utilises data flow graphs to represent both mathematical operations and data. TensorFlow has a stable Python API, and other unstable APIs in C++, Java, and Go.
For this project Caffe in conjunction with Digits was chosen as a platform for utilising deep learning for making grasp predictions. Caffe specialises in processing visual data, whereas other tools provide support for different input such as text. Caffe is well-documented and popular with researchers at my university, therefore I receive a higher level of support compared to any other tool. Finally, Digits provides an intuitive and powerful interface that could not be found for any of the other frameworks.
In the future I would like to rewrite my algorithm to use TensorFlow, as it is increasingly becoming the state of the art deep learning library, with excellent documentation, and visualisation tools.
In the next log I will introduce the CNN architecture I used in my vision-based control algorithm.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.