 Stephanie Stoll
Stephanie StollThis log discusses how the CNNs where trained for my system and what data was used, as well as describing the data collection and augmentation process.
Five convolutional neural networks are at the heart of the high-level control of the hand prototype. In order to retrain the networks for the task of classifying a finger as used or not used in a grasp attempt a dataset needed to be created for training and validation. Given time constraints only 500 grasp attempts were recorded but I hope to increase that number significantly and see what difference it makes on the performance of the system.
I will now look at the nature of the data, how it was collected and augmented and how it was used to train the five CNNs.
Data Collection and Augmentation
The data for the grasp attempts was collected from the hand’s sensory system consisting of a wrist camera and feedback sensors from the five servos controlling the hand. For each grasp attempt a still image was recorded of the hand in its open position and an object in its vicinity. The hand is then closed and the normalised feedback values of each finger are recorded and used as labels. The labels act as the ground truth in the training of the CNNs. The feedback values allowed us to measure if a finger had encountered resistance and therefore made contact with the object or whether it had fully closed and therefore was not part of the grasp. The figure below shows data examples for two different grasp attempts:

Data Collection Process
In total 500 grasp samples were collected over two days under similar conditions and using the same set up. To keep lighting conditions as constant as possible data collection took place indoors, using only artificial halogen light. The hand was placed in a sideways position (see below, and a white background placed behind the hand’s fingers, to minimise influence of any background features on the network’s learning process.

The object to be grasped was a glue stick, as its cylindrical shape lends itself to different grasp types like pinch and wrap grasps. The stick was manually placed into position, but a python script was written to automate as much of the data collection process as possible in order to minimise human interaction altering the data. The script contains the following steps:
-
set up camera, establish serial connection to Arduino.
-
set up and calibrate the hand.
-
Stream video to screen whilst positioning object.
-
Confirm by keypress when object is in position, record current frame.
-
Close hand using feedback mechanism.
-
When all fingers have reached their end positions, record positions as labels to frame.
-
Open hand.
-
Go back to 3.
9. Re-calibrate hand after 20 grasp attempts.
The raw data collected consists of one frame per grasp attempt and a text file listing full paths to all images and their corresponding labels.
The following section describes how this data was formatted and augmented to be used to train the five CNNs that control the hand’s fingers.
Data Formatting and Augmentation
he raw data collected needed to be formatted to be used in DIGITS, NVidia’s Deep Learning GPU Training System for Caffe. A separate dataset was created for each of the five networks. Each dataset is described by a text file with full paths to each image and the label belonging to the finger in question. The labels are quantised into two stages 0 and 1, signifying the two classes ‘used’ and ‘not used’. Each dataset was then balanced between positive and negative training examples. For all fingers apart from the thumb, this meant increasing the number of negative examples by duplication. The number of positive examples for the thumb (meaning the thumb being involved in the grasp) was significantly lower than for the other fingers, hence positive training examples needed to be increased by duplication. An example extract of the index’s dataset text file is shown here:

The next section describes how the datasets for each net were created and how they were used in training each net. It also shows the process of experimenting with different settings for the nets to improve performance.
Training of CNNs
DIGITS provides a graphical user interface for training and testing CNNs in Caffe. However, it also contains an interface to create and manage image databases used to train, validate, and test networks. The figure below shows the interface for creating a dataset using text files in the aforementioned format. Separate files are used for training and validation sets, and a file defining the labels for each class is needed to create a dataset.
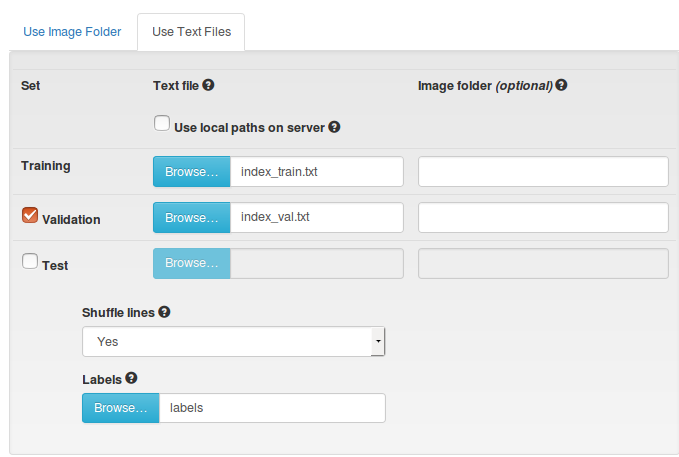
Once a dataset is created it can be used in DIGITS to train a new model. A model contains the definition of the net used, all its settings and a reference to the dataset.
Pre-trained AlexNets were used for all fingers, with just the fully connected layers being retrained using the collected data. First, the standard settings of 30 training epochs, a stochastic gradient descent (SDG) solver and a base learning rate of 0.01 were used. However, performance and stability of the nets was improved by lowering the learning rate to 0.0001 and changing the solver type to Adam, which like SDG is a gradient-based optimisation method.
In the next log I will present the performance of the current high-level control system.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.