 Stephanie Stoll
Stephanie StollThis log presents and discusses the performance of the vision-based grasp learning algorithm used to control the hand prototype. Let's first examine the networks’ learning results before presenting and discussing the algorithm’s performance in grasping experiments using previously unseen test data.
Learning
The five CNNS at the heart of the learning algorithm were trained using 500 images of a glue stick object in the vicinity of the hand prototype and positional feedback of the hand’s fingers after a grasp attempt.
The graphs below show accuracy and loss for the net controlling the index finger with two different sets of parameters.
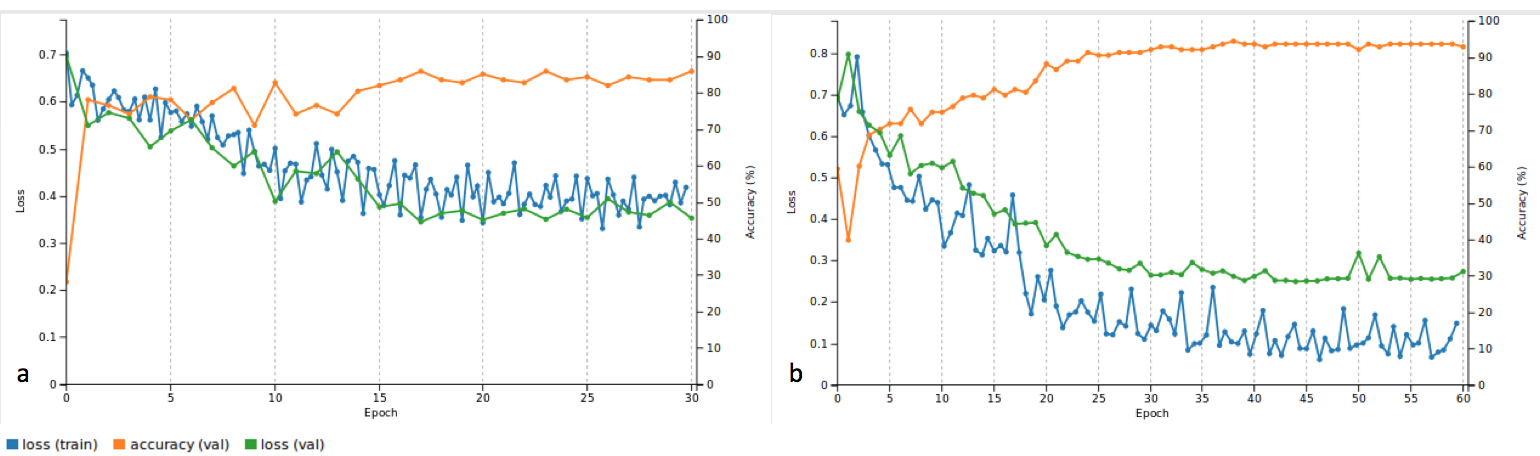
a) is the accuracy and loss over 30 epochs using a stochastic gradient descent solver and a base learning rate of 0.01. Whereas the accuracy is very acceptable with 86%, the system does appear to not have converged entirely, and appears unstable. To allow the system to converge and stabilise the solver type was changed to Adam, and the base and learning rate set to 0.0001 (see b). The system was trained over 60 epochs, but this did not change values significantly, so it was later reversed to 30 epochs.
Let's look at all the accuracies and losses for all five CNNs:

Accuracies for the thumb (a), index (b) and middle (c) finger are 80%. Compared to this the accuracy for the ring (d) and little (e) finger is poor with 63% and 72% respectively. This difference in performance could be due to the thumb, index and middle fingers having more defined use cases in wrap as well as pinch grasps, whereas there are less clear scenarios that would specifically require the ring or little finger to be used.
A higher amount of training and validation data would likely provide clearer and more meaningful results. However, the system still managed to learn queues to successfully grasp different objects as well as the object used in training as can be seen in the next section.
Grasping
This section presents the performance of the vision-based grasp learning algorithm under similar conditions to the grasp data collection (halogen light, white background). The CNNs responsible for learning were trained on images of a glue stick, which was one of the objects tested in grasping tests. However, other objects were also tested, to assess whether the system has generalised. The other objects are a glue bottle, an iPhone 6s with case and cover, a roll of masking tape, a white golf ball, and a black golf ball. A successful grasp was defined as being able to grasp and hold the object stably for at least three seconds, or for no finger reacting if the object is out of reach. An unsuccessful grasp was defined as the hand not being able to grasp and/or hold the object for at least three seconds, or for one or multiple fingers reacting when the object is out of reach. Figures indicating the percentages of success and failure for each object over 100 grasp attempts each are summarised here:
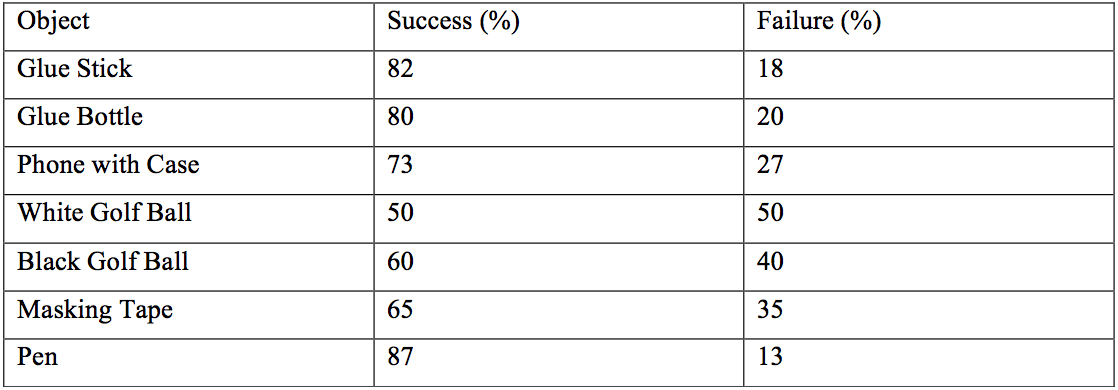
For the glue stick a success rate of 82% was found. Small and elongated objects such as the glue bottle and the pen out of the previously unseen objects performed almost equally well. This is possibly due to their similarity in shape to the glue stick. Small size makes it easier for the fingers to wrap around an object, which is possibly why the pen outperformed the glue stick in its success rate. This could however also be down to the relatively limited amount of data samples. An also elongated but bigger object like the phone was harder to grasp due to the fingers closing uniformly across their phalanges and therefore not being able to fully wrap around the object. Both golf balls’ performance was poor compared to all other objects. This was mainly due to the hand’s incapability to perform radial grasps, as this would require abduction of the fingers. Additionally, the white golf ball was hard to distinguish against a white background, further worsening performance.
Overall, the success rates for grasping objects different to the glue stick suggest that the system shows some level of generalisation.
Here are some examples of successful and unsuccessful grasp attempts for the glue stick and other objects:



To summarise the CNNs show an accuracy of up to 92% (index), and a minimum of 63% (ring finger). The hand is capable of grasping the training object with a success rate of 82%. The highest success rate over a 100 grasp attempts was 87% for a previously unseen pen object.
The next step to improve performance is to combine the 5 CNNs into one CNN to establish relations between the different fingers. I would also like to collect more training data to improve the network's performance.
Discussions
Become a Hackaday.io Member
Create an account to leave a comment. Already have an account? Log In.